はじめに
こんにちは堤です。
Amazon BedrockがGAとなり、AWS内で完結してLLMアプリケーションを構築できるようになりました。
試しにRAGアプリケーションを作成してみようと思いましたが、現状AWSでRetrievalするデータソースを作成しようとすると、Amazon OpenSearch Serverless やAmazon Kendraを使用するしかありません。これらのサービスを使うのはコストもそれなりにかかり少しハードルが高いなーと思っていたら以下のブログを見つけました。
構成図を見ると分かるように、S3にembeddingしたデータソースを置いて、それを検索(Retrieval)することで回答を作成しているようです。
使っているサービスもLambda, S3, DynamoDB, API Gatewayと馴染みのあるサービスばかりなので、このブログの構成を簡略化してRAGアプリケーション作成してみることにしました。
RAGとは
そもそもRAGとはRetrieval Augmented Generationの略で、外部の知識ソースを利用して大規模言語モデル(LLM)の回答の質を向上させる手法です。LLM単体で回答するより正確性が増したり、最新情報にアクセスできるといった利点があります。
具体的な手順としては
- 質問したい情報源の文章をベクトル化(Embedding)する
- このベクトルをまとめてデータベースにする
- ユーザーが質問文を入力すると、その質問文に近い文章を取得する(Retrieval)
- 取り出した文章と質問を合わせて、LLMに入力し回答を得る
といった流れになります。
構成図
今回作成するアプリケーションの構成図です。
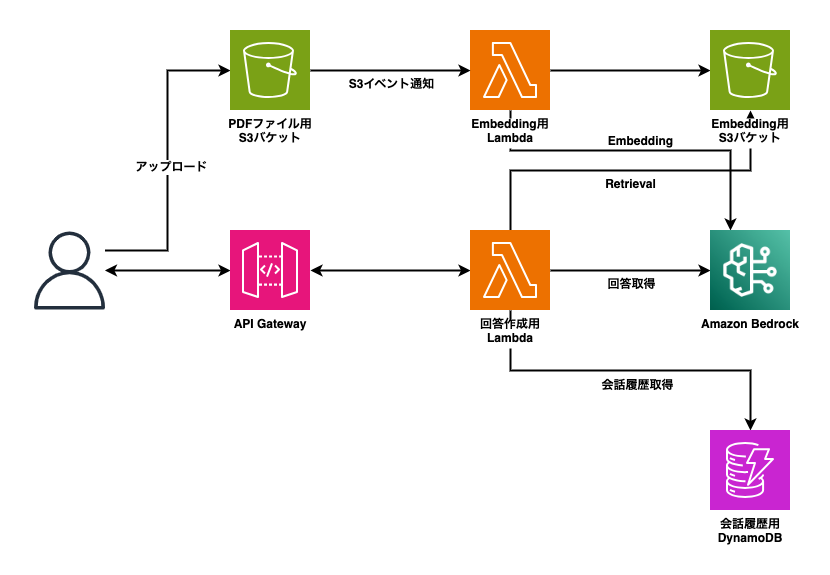
作成リソース
Lambda
1. PDFから文書抽出&Embedding取得Lambda
まずはPDFから文書を抽出して、そのEmbeddingを取得する関数です。この関数はPDF用S3バケットからのS3イベント通知で起動するようにします。
import json import boto3 import os from langchain.document_loaders import PyPDFLoader from langchain.embeddings import BedrockEmbeddings from langchain.indexes import VectorstoreIndexCreator from langchain.vectorstores import FAISS s3 = boto3.client("s3") embedding_bucket = os.environ["AWS_RAG_EMBED_BUCKET"] def handler(event, context): s3_info = event["Records"][0]["s3"] bucket_name = s3_info["bucket"]["name"] object_key = s3_info["object"]["key"] s3.download_file(bucket_name, object_key, "/tmp/input.pdf") loader = PyPDFLoader("/tmp/input.pdf") bedrock_runtime = boto3.client( service_name="bedrock-runtime", region_name="us-east-1", ) embeddings = BedrockEmbeddings( model_id="amazon.titan-embed-text-v1", client=bedrock_runtime, region_name="us-east-1", ) index_creator = VectorstoreIndexCreator( vectorstore_cls=FAISS, embedding=embeddings, ) index_from_loader = index_creator.from_loaders([loader]) index_from_loader.vectorstore.save_local("/tmp") s3.upload_file("/tmp/index.faiss", embedding_bucket, "index.faiss") s3.upload_file("/tmp/index.pkl", embedding_bucket, "index.pkl") return {"statusCode": 200, "body": json.dumps("Success")}
LangChainのpyPDFLoaderで読み込んだ文書からtitan-embed-text-v1でEmbeddingを取得し、FaissのインデックスをS3に保存しています。
2. 回答作成用Lambda
import boto3 import json import os import hashlib from langchain.llms.bedrock import Bedrock from langchain.memory.chat_message_histories import DynamoDBChatMessageHistory from langchain.memory import ConversationBufferMemory from langchain.embeddings import BedrockEmbeddings from langchain.vectorstores import FAISS from langchain.chains import ConversationalRetrievalChain embedding_bucket = os.environ["AWS_RAG_EMBED_BUCKET"] memory_table_name = os.environ["MEMORY_TABLE_NAME"] s3 = boto3.client("s3") def handler(event, context): event_body = json.loads(event["body"]) file_name = event_body["fileName"] human_input = event_body["prompt"] conversation_id = hashlib.sha256(file_name.encode()).hexdigest() s3.download_file(embedding_bucket, "index.faiss", "/tmp/index.faiss") s3.download_file(embedding_bucket, "index.pkl", "/tmp/index.pkl") bedrock_runtime = boto3.client( service_name="bedrock-runtime", region_name="us-east-1", ) embeddings = BedrockEmbeddings( model_id="amazon.titan-embed-text-v1", client=bedrock_runtime, region_name="us-east-1", ) llm = Bedrock( model_id="anthropic.claude-v2", client=bedrock_runtime, region_name="us-east-1" ) faiss_index = FAISS.load_local("/tmp", embeddings) message_history = DynamoDBChatMessageHistory( table_name=memory_table_name, session_id=conversation_id ) memory = ConversationBufferMemory( memory_key="chat_history", chat_memory=message_history, input_key="question", output_key="answer", return_messages=True, ) qa = ConversationalRetrievalChain.from_llm( llm=llm, retriever=faiss_index.as_retriever(), memory=memory, return_source_documents=True, ) res = qa({"question": human_input}) return { "statusCode": 200, "headers": { "Content-Type": "application/json", "Access-Control-Allow-Headers": "*", "Access-Control-Allow-Origin": "*", "Access-Control-Allow-Methods": "*", }, "body": json.dumps(res["answer"]), }
先ほど作成したFaissのインデックスを読み込み、それをもとに回答を行います。モデルはAnthropicのClaude v2を使用します。
AWS SAM テンプレート
これらのLambda関数とその他リソースはAWS SAMでデプロイしました。
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: # Lambda Functions PdfAndEmbeddingFunction: Type: AWS::Serverless::Function Properties: Handler: pdf_and_embedding.handler Runtime: python3.11 CodeUri: ./lambda/pdf_and_embedding/ Timeout: 180 MemorySize: 2048 Policies: - S3CrudPolicy: BucketName: !Ref awsRagPdfBucket - S3CrudPolicy: BucketName: !Ref awsRagEmbedBucket - Statement: - Sid: 'BedrockScopedAccess' Effect: 'Allow' Action: 'bedrock:InvokeModel' Resource: 'arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1' Environment: Variables: AWS_RAG_EMBED_BUCKET: !Ref awsRagEmbedBucket AnswerCreationFunction: Type: AWS::Serverless::Function Properties: Handler: answer_creation.handler Runtime: python3.11 CodeUri: ./lambda/answer_creation/ Timeout: 180 MemorySize: 2048 Policies: - DynamoDBCrudPolicy: TableName: !Ref SessionTable - S3CrudPolicy: BucketName: !Ref awsRagEmbedBucket - Statement: - Sid: 'BedrockScopedAccess' Effect: 'Allow' Action: 'bedrock:InvokeModel' Resource: - 'arn:aws:bedrock:*::foundation-model/anthropic.claude-v2' - 'arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1' Events: AnswerApi: Type: Api Properties: Path: /answer Method: post Environment: Variables: AWS_RAG_EMBED_BUCKET: !Ref awsRagEmbedBucket MEMORY_TABLE_NAME: !Ref SessionTable # S3 Buckets awsRagPdfBucket: Type: AWS::S3::Bucket DeletionPolicy: Retain awsRagEmbedBucket: Type: AWS::S3::Bucket # API Gateway MyApi: Type: AWS::Serverless::Api Properties: StageName: Prod DefinitionBody: swagger: '2.0' info: title: !Ref AWS::StackName paths: /answer: post: x-amazon-apigateway-integration: uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${AnswerCreationFunction.Arn}/invocations httpMethod: POST type: aws_proxy # DynamoDB SessionTable: Type: AWS::DynamoDB::Table Properties: AttributeDefinitions: - AttributeName: sessionId AttributeType: S KeySchema: - AttributeName: sessionId KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5
Streamlit
フロントエンドにはPythonのWebアプリケーションフレームワークであるStreamlitを使用します。
Chat elementsを使うことで簡単にChatGPTライクなアプリケーションを作成することができ便利です。
import streamlit as st import boto3 from io import BytesIO import requests def upload_to_s3(file, file_name, bucket): """ アップロードされたファイルをS3に保存 """ buffer = BytesIO(file.read()) s3.put_object(Body=buffer.getvalue(), Bucket=bucket, Key=file_name) def send_post_request(url, file_name, prompt): # 送信するデータを準備 data = {"fileName": file_name, "prompt": prompt} try: # POSTリクエストを送信 response = requests.post(url, json=data) # レスポンスのステータスコードをチェック if response.status_code == 200: return response.json() # 成功した場合はJSONレスポンスを返す else: return f"Failed: {response.text}" # 失敗した場合はエラーメッセージを返す except Exception as e: return f"Error: {str(e)}" # 例外が発生した場合はエラーメッセージを返す s3 = boto3.client("s3") url = "API_ENDPOINT" st.title("Chat With PDF") st.markdown("### Upload PDF File") uploaded_file = st.file_uploader("Upload file", type=["pdf"]) if uploaded_file is not None: # S3にアップロード upload_to_s3( uploaded_file, uploaded_file.name, "s3-bucket-name" ) st.markdown(f"### {uploaded_file.name}について質問する") if "messages" not in st.session_state: st.session_state.messages = [] for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"]) if prompt := st.chat_input("What is up?"): with st.chat_message("user"): st.markdown(prompt) st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("assistant"): response = send_post_request(url, uploaded_file.name, prompt) st.markdown(response) st.session_state.messages.append({"role": "assistant", "content": response})
動作確認
実際にアプリケーションを実行してみます。
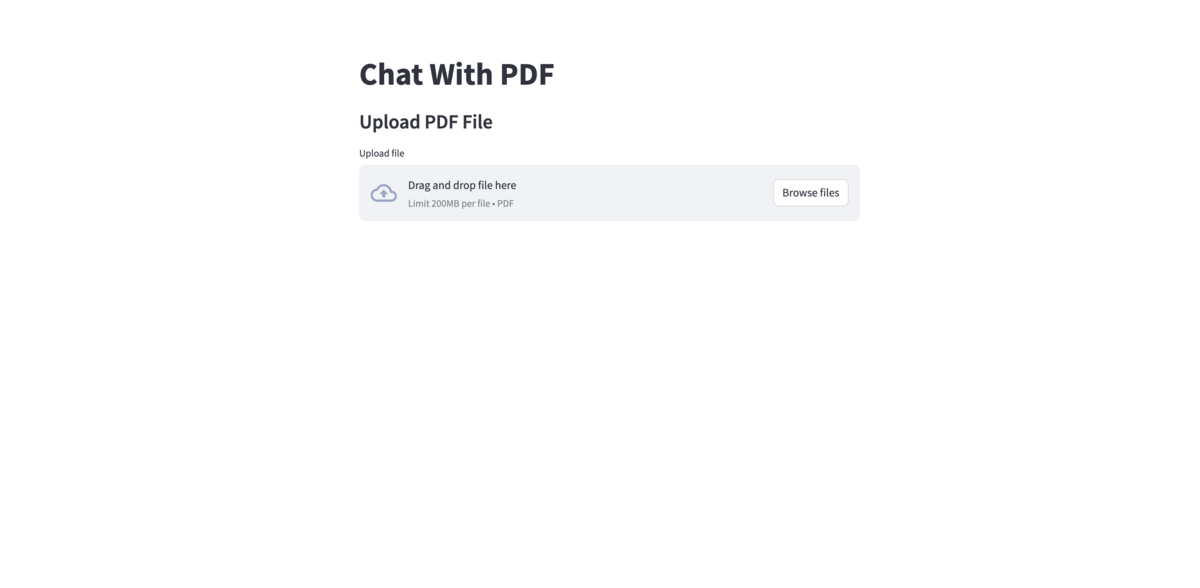
まずはPDFのアップロード画面が出てきます。 今回はAmazon BedrockのUser GuideのWhat is Amazon Bedrock?というページをPDFにしてアップロードしてみます。

チャット入力欄が出てきました。 上のPDFに書いてあることを聞いてみましょう。

正しい回答です!
Stable Diffusionを大規模言語モデル扱いしてしまっているのが気になりますがサポートしているモデルについては正しい回答を導きだしています。
もう一つ質問してみます。
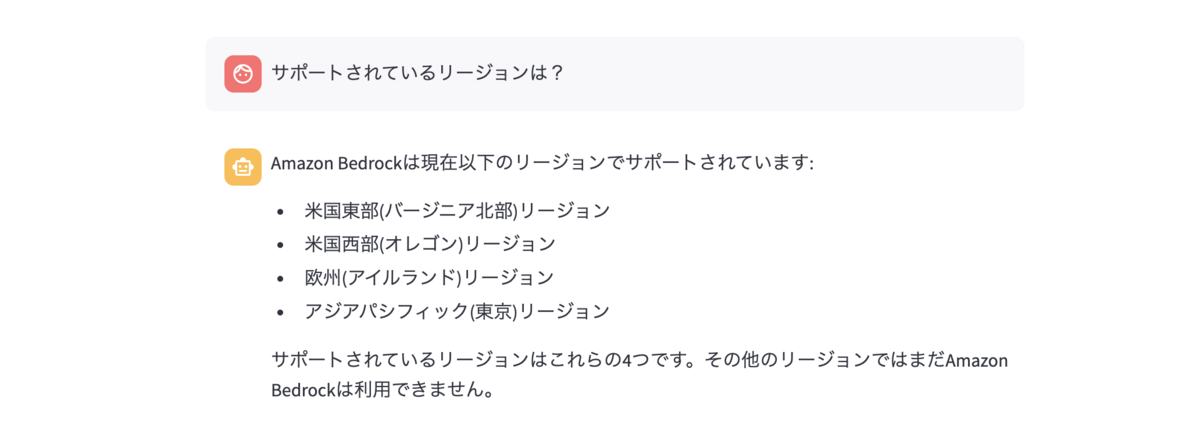
今度はサポートしているリージョンを質問してみました。執筆時点(2023年10月16日)でサポートされているリージョンは
- US East (N. Virginia)
- US West (Oregon)
- Asia Pacific (Singapore)
- Asia Pacific (Tokyo)
なので誤った回答となってしまっています。
英語で同じ質問をしてみます。

同じことを何度も繰り返しているのが少し気になりますが正しい回答です。 元のPDFが英語であることや言語間での性能差が影響していそうです。
まとめ
今回はAWSサービスのみでRAGを実装してみました。
大量のデータを読み込ませたりする場合はこの構成では厳しそうですが、個人利用であればレスポンスもそこそこ早く十分使えるなーと感じました。
基本的なサービスのみで構成されていてLangChainでいい感じに抽象化してくれるおかげで実装も比較的簡単なので是非お試しください。