はじめに
こんにちは。2年目の大林です。
今回は2度目のブログ執筆なのですが、前回の執筆から約3か月も経過していました...。
1年目の頃より2年目の方が時が経つのが早い気がしています。
本ブログでは、Amazon CloudFrontのアクセスログの保存パスをAthena用に最適化する方法を書いていきたいと思います。
課題
Amazon CloudFrontに対してアドホックなログ分析をする際、Amazon Athenaを利用することが多いのではないでしょうか。 Amazon Athenaを利用する際は、パーティションを指定してスキャン量を最小限に抑えることがコスト効率の上昇につながります。 しかし、Amazon CloudFrontのデフォルトのアクセスログ保存のパス体系はAthenaで分析するに当たって最適な形にはなっていません。 part1では、Lambda関数を使用してこの課題を解決してみたいと思います。
想定しているケース
ケース1
・CloudFrontのアクセスログが有効になっていない
・単一のS3バケットを使用したパス最適化を実施したい
ケース2
・CloudFrontのアクセスログが有効になっていない
・パス最適化処理の途中でエラーが起きた場合でもログファイルを消失したくない場合
ケース1
ケース1の設計と処理の流れ

①Amazon CloudFrontのアクセスログがS3バケットに保存される

②Lambda関数でアクセスログ保存のパスを最適化する
・ログファイルをパス(ディストリビューション名/yyyy/mm/dd)を指定してコピーします。
・上記の処理が終了した時点で、パス最適化前と最適化後のログファイルが存在することになるのでパスが最適化できていないほうを削除します。
使用するLambda関数のコードは以下です。
import re
import boto3
import os
import json
def lambda_handler(event, context):
# イベントログを出力
recieved_event = json.dumps(event)
print('Received event:' + recieved_event)
s3 = boto3.client('s3')
date_pattern = r'[^\\d](\d{4})-(\d{2})-(\d{2})-(\d{2})[^\\d]'
filename_pattern = r'[^/]+$'
bucket = event['Records'][0]['s3']['bucket']['name']
source_key = event['Records'][0]['s3']['object']['key']
target = '/'
target_find = source_key.find(target)
target_key_prefix = source_key[:target_find]
# ファイル名が定義したパターンにマッチしているか判定する
source_regex = re.compile(date_pattern)
match = source_regex.search(source_key)
if match is None:
print('ファイルが見つかりませんでした。')
else:
year, month, day, hour = match.groups()
filename_regex = re.compile(filename_pattern)
filename = filename_regex.search(source_key).group(0)
target_key = target_key_prefix + '/' + year + '/' + month + '/' + day + '/' + filename
print(source_key + ' to ' + target_key)
# パスを指定して、オブジェクトを移動させる
copy_result =s3.copy_object(Bucket=bucket, Key=target_key,
CopySource={'Bucket': bucket, 'Key': source_key})
print(copy_result)
# パス最適化前のオブジェクトを削除する
s3.delete_object(Bucket=bucket, Key=source_key)
③Amazon Athenaでアクセスログをクエリする
分析用のテンプレートは以下です。
AWSTemplateFormatVersion: "2010-09-09"
#----------------------------------------------------------------------#
# Athenaを利用したCloudFrontのアクセスログ分析用テンプレート
# 作成されるリソース:Glue:Database, Glue:Table, S3bucket, Athenaワークグループ
#----------------------------------------------------------------------#
Parameters:
#アカウントIDを入力
AccountId:
Description: "input Account Id "
Type: String
#環境名を入力
Env:
Description: dev or prod
Type: String
#システム名を入力
SystemName:
Description: System name
Type: String
#CloudFrontのアクセスログが保存されているS3バケットを指定する
S3bucketCloudFrontLogs:
Type: String
#オブジェクトの有効期限を入力
ExpirationInDays:
Type: String
Default: 1825
#Glueテーブルのパーティションに設定するCloudFrontディストリビューションを入力
distributions:
Description: "enter distribution name by Comma Delimiter list (XXXXXXXXXXXX,XXXXXXXXXXXX...)"
Type: String
Resources:
#------------------------------------------------------------#
# Glue
# アクセスログ用のデータベースとテーブルを作成する
#------------------------------------------------------------#
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Sub '${Env}_${SystemName}_cloudfront_database'
#CloudFrontアクセスログのGlueテーブル
GlueTableCloudFrontLogs:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref GlueDatabase
TableInput:
Name: !Sub '${Env}_${SystemName}_cloudfront_table'
TableType: EXTERNAL_TABLE
Parameters:
EXTERNAL: true
projection.enabled: true
projection.distribution.type: enum
projection.distribution.values: !Sub '${distributions}'
projection.datetime.type: date
projection.datetime.format: yyyy/MM/dd
projection.datetime.range: 2023/01/01,NOW
storage.location.template: !Sub 's3://${S3bucketCloudFrontLogs}/${!distribution}/${!datetime}'
skip.header.line.count: '2'
serialization.encoding: utf-8
PartitionKeys:
- Name: distribution
Type: string
- Name: datetime
Type: string
StorageDescriptor:
Columns:
- Name: date
Type: date
- Name: time
Type: string
- Name: location
Type: string
- Name: bytes
Type: bigint
- Name: requestip
Type: string
- Name: method
Type: string
- Name: host
Type: string
- Name: uri
Type: string
- Name: status
Type: int
- Name: referrer
Type: string
- Name: useragent
Type: string
- Name: querystring
Type: string
- Name: cookie
Type: string
- Name: resulttype
Type: string
- Name: requestid
Type: string
- Name: hostheader
Type: string
- Name: requestprotocol
Type: string
- Name: requestbytes
Type: bigint
- Name: timetaken
Type: float
- Name: xforwardedfor
Type: string
- Name: sslprotocol
Type: string
- Name: sslcipher
Type: string
- Name: responseresulttype
Type: string
- Name: httpversion
Type: string
- Name: filestatus
Type: string
- Name: encryptedfields
Type: int
- Name: cPort
Type: string
- Name: timeToFirstByte
Type: string
- Name: xEdgeDetailedResultType
Type: string
- Name: scContentType
Type: string
- Name: scContentLen
Type: string
- Name: scRangeStart
Type: string
- Name: scRangeEnd
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Location: !Sub 's3://${S3bucketCloudFrontLogs}/'
SerdeInfo:
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Parameters:
serialization.format: "\t"
#------------------------------------------------------------#
# Athena
#------------------------------------------------------------#
AthenaWorkGroup:
Type: AWS::Athena::WorkGroup
Properties:
Name: !Sub "${Env}-athena-work-group"
WorkGroupConfiguration:
ResultConfiguration:
OutputLocation: !Sub "s3://${AthenaQueryResultBucket}/data"
EnforceWorkGroupConfiguration: true
PublishCloudWatchMetricsEnabled: true
#------------------------------------------------------------#
# S3 Backet
# Athenaでクエリを実行した結果が格納されるS3バケットを作成する
#------------------------------------------------------------#
AthenaQueryResultBucket:
Type: AWS::S3::Bucket
DeletionPolicy: 'Retain'
Properties:
BucketName: !Sub '${Env}-${SystemName}-cloudfront-athena-result'
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
LifecycleConfiguration:
Rules:
- Id: life-cycle-rule
Status: Enabled
ExpirationInDays: !Sub '${ExpirationInDays}'
BucketEncryption:
ServerSideEncryptionConfiguration:
-
ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
ケース1のデモ
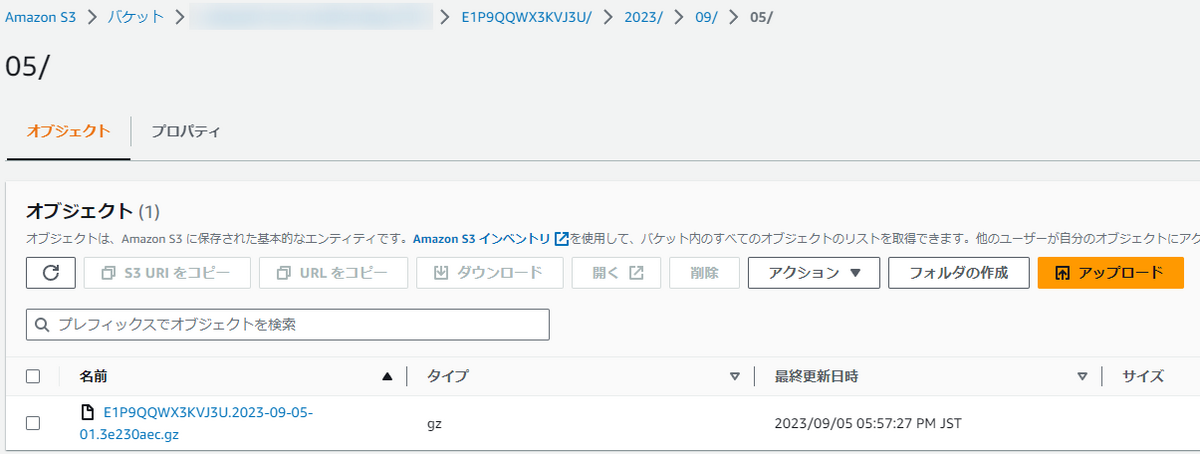
まずはコンテンツにアクセスして、CloudFrontのアクセスログがS3バケットに作成アップロードされるのを待ちます。
ログファイルは、指定したプレフィックス名のフォルダの配下にアップロードされます。
※CloudFrontのログファイルは、ログ有効化設定時に指定したプレフィックス名のフォルダ配下にアップロードされます。
ログファイルがS3バケットにアップロードされたことをトリガーにLambda関数が起動され、パスが最適化されると以下のようになります。
ケース2
ケース2の設計と処理の流れ
ケース2では、S3バケットを2つ使用するためその分コストがかかってしまいます。
ライフサイクルポリシーを使用するなどコストを抑える対策を取る必要があります。

①Amazon CloudFrontのアクセスログがS3バケットに保存される
この段階では、通常のCloudFrontのアクセスログ保存パスと同じです。

②Lambda関数でアクセスログ保存のパスを最適化する
ログファイルをパス(ディストリビューション名/yyyy/mm/dd)を指定して別のS3バケットにコピーします。
使用するLambda関数のコードは以下です。
import re
import boto3
import os
import json
def lambda_handler(event, context):
# イベントログを出力
recieved_event = json.dumps(event)
print('Received event:' + recieved_event)
s3 = boto3.client('s3')
date_pattern = r'[^\\d](\d{4})-(\d{2})-(\d{2})-(\d{2})[^\\d]'
filename_pattern = r'[^/]+$'
destination_bucket = os.getenv('s3bucket')
bucket = event['Records'][0]['s3']['bucket']['name']
source_key = event['Records'][0]['s3']['object']['key']
target = '/'
target_find = source_key.find(target)
target_key_prefix = source_key[:target_find]
# ファイル名が定義したパターンにマッチしているか判定する
source_regex = re.compile(date_pattern)
match = source_regex.search(source_key)
if match is None:
print('ファイルが見つかりませんでした。')
else:
year, month, day, hour = match.groups()
filename_regex = re.compile(filename_pattern)
filename = filename_regex.search(source_key).group(0)
target_key = target_key_prefix + '/' + year + '/' + month + '/' + day + '/' + filename
print(source_key + ' to ' + target_key)
# パスを指定して、オブジェクトを移動させる
copy_result =s3.copy_object(Bucket=destination_bucket, Key=target_key,
CopySource={'Bucket': bucket, 'Key': source_key})
print(copy_result)
③Amazon Athenaでアクセスログをクエリする
ケース2で使用するテンプレートはケース1で使用したものと同じものを使用しますが、Glueのテーブルを作成する際に指定するS3バケットが異なります。 Glueのテーブルを作成する際は注意する必要があります。
ケース2のデモ
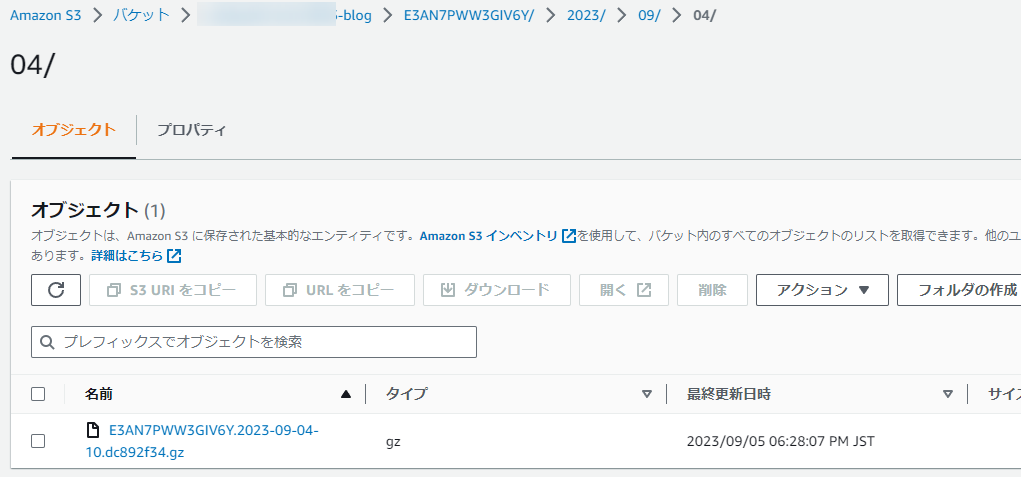
まずはコンテンツにアクセスして、CloudFrontのアクセスログがS3バケットに作成アップロードされるのを待ちます。
ログファイルは、指定したプレフィックス名のフォルダの配下にアップロードされます。
※CloudFrontのログファイルは、ログ有効化設定時に指定したプレフィックス名のフォルダ配下にアップロードされます。

ログファイルがS3バケットにアップロードされたことをトリガーにLambda関数が起動され、パスを最適化して別のS3バケットアップロードされます。
さいごに
今回はLambda関数でCloudFrontのアクセスログのパス保存を最適化する方法を紹介しました。 今回紹介した方法は、新規でS3バケットにアップロードされたログファイルのパスを最適化する際に使用できるものです。 次回のAmazon CloudFrontのアクセスログ保存パスをAthena用に最適化してみた~part2~では、既存のCloudFrontのアクセスログに対してパス保存最適化処理を行う方法を紹介します。
