小西秀和です。
以前の記事でAmazon Bedrockの参考資料、モデル一覧、価格、使い方、トークンやパラメータの用語説明、Runtime APIの実行例について紹介しました。
今回はAnthropic Claudeで英訳したテキストをもとにStability AI Stable Diffusion XL(SDXL)で画像を生成するAmazon Bedrockの使用例を紹介します。
※本記事および当執筆者のその他の記事で掲載されているソースコードは自主研究活動の一貫として作成したものであり、動作を保証するものではありません。使用する場合は自己責任でお願い致します。また、予告なく修正することもありますのでご了承ください。
※本記事執筆にあたっては個人でユーザー登録したAWSアカウント上でAWSサービスを使用しています。
※本記事執筆にあたって使用したAmazon Bedrockの各Modelは2023-10-09(JST)に実行し、その時点における次のEnd user license agreement (EULA)に基づいています。
Anthropic Claude v2(anthropic.claude-v2): ANTHROPIC BEDROCK AI SERVICES AGREEMENT(last modified: October 3, 2023)
Stability AI Stable Diffusion XL(stability.stable-diffusion-xl-v0): STABILITY AMAZON BEDROCK END USER LICENSE AGREEMENT(Last Updated May 30, 2023)
今回の記事の内容は次のような構成になっています。
Anthropic Claudeの概要
AnthropicはOpenAIの元エンジニアが創業し、GoogleやAmazonも出資をする生成AI技術に関するUSのスタートアップ企業です。
ClaudeはAnthropicが開発したチャット型AIモデルで、Hallucination(ハルシネーション:事実に基づかない情報)が少なく、日本語を含む多言語に対応した自然で人間に近い会話ができるとされています。
Anthropic ClaudeはAmazon Bedrockで本記事執筆時点で選択できるモデルの中でも日本語対応に強みがあるため、今回の要件である日本語から英語への翻訳に対応するために採用しました。
Claude v2で指定するパラメータの概要
AWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行する例を用いて、Claude v2で指定するパラメータの概要を説明すると次のようになります。
import boto3 import os region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) response = bedrock_runtime_client.invoke_model( modelId='anthropic.claude-v2', # 使用するモデルを指定する識別子。 contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) body=json.dumps({ "prompt": "\n\nHuman:<prompt>\n\nAssistant:", # <prompt>の部分をユーザーが入力したPromptに置き換える。 "temperature": 0.5, # temperatureの値を指定する。(デフォルト: 0.5、最小値: 0、最大値: 1.0) "top_p": 1.0, # topPの値を指定する。(デフォルト: 1.0、最小値: 0、最大値: 1.0) "top_k": 250, # topKの値を指定する。(デフォルト: 250、最小値: 0、最大値: 500) "max_tokens_to_sample": 200, # トークンの最大数であるmaxTokensの値を指定する。(デフォルト: 200、最小値: 0、最大値: 4,096) "stop_sequences": ["\n\nHuman:"] # 指定された文字列またはシーケンスがテキスト生成中に検出されると、その時点でモデルはテキストの生成を停止する。 }) )
これらのパラメータのうち、テキストを扱うモデルの一般的な推論パラメータであるtemperature、top_p(topP)、top_k(topK)、max_tokens_to_sample(maxTokens)の意味については次の記事で説明していますので合わせて御覧ください。
Amazon Bedrockの基本情報とRuntime APIの実行例まとめ:一般的な推論パラメータの意味
その他、Anthropic Claudeモデルで使用するパラメータの詳細については次のAWS Documentを参照してください。
参考:Anthropic Claude models - Inference parameters for foundation models - Amazon Bedrock
Claude v2モデルで生成されるテキストの所有権や著作権について
Claude v2のライセンスを参照して、モデルで出力される画像の所有権や著作権について確認しておきます。
Amazon BedrockコンソールのAnthropic Claude v2モデル画面にあるEnd User License Agreement (EULA)によるとプロバイダーであるAnthropicはプロンプトやアウトプットの所有権を主張しないと記載されています(※正確な全容はライセンスを確認してください)。
D. Ownership of Prompts and Outputs. Anthropic makes no claim to ownership of Prompts or Outputs.
そのため、ライセンスに記載されている内容を遵守すればモデルで生成された出力テキストは自由に使用できることが読み取れます。
Stability AI Stable Diffusion XL(SDXL)の概要
Stability AIはUSの投資会社やベンチャーキャピタルからも大型資金調達をしているオープンソースの生成AI技術に関するUKのスタートアップ企業です。
Stable Diffusion XL(SDXL)はUKにあるStability AI社が開発した画像生成AIモデルで、SDXLは短いシンプルなプロンプトでリアルな画像、画像内の読みやすいテキスト、優れた画像合成を生成できるとされています。
SDXLはAmazon Bedrockで本記事執筆時点で選択できるモデルの中で唯一の画像生成AIモデルであるため、今回の要件である英訳したテキストからの画像生成に対応するために採用しました。
SDXL(v0.8 - preview)で指定するパラメータの概要
AWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行する例を用いて、SDXL(v0.8 - preview)で指定するパラメータの概要を説明すると次のようになります。
response = client.invoke_model(
modelId='stability.stable-diffusion-xl-v0', # 使用するモデルを指定する識別子。
contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json)
accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json)
body=json.dumps({
"text_prompts": [
{"text": "<prompt>"} # <prompt>の部分をユーザーが入力したPromptに置き換える。
],
"seed": 0, # Seedの値を設定する。初期のノイズ設定を決定する。以前の実行と同じシード、同じ設定を使用すると、同様の画像を生成するための推論ができる。この値を設定しない場合はランダムな値が設定される。
"cfg_scale": 10, # Prompt strength(プロンプト強度)の値を設定する。最終的な画像がプロンプトをどれだけ反映するかを決定する。数値を小さくすると、生成におけるランダム性を増やすことができる。(デフォルト: 10、最小値: 0、最大値: 30)
"steps": 50 # Generation step(生成ステップ)の値を設定する。画像がサンプリングされる回数を決定する。ステップ数を増やすと、より正確な結果が得られることがある。(デフォルト: 5、最小値: 0、最大値: 150)
})
)
その他、Stability AI Stable Diffusion XLモデルで使用するパラメータの詳細については次のAWS Documentを参照してください。
参考:Stability.ai Diffusion models - Inference parameters for foundation models - Amazon Bedrock
Stable Diffusionモデルで生成される画像の所有権や著作権について
Stable Diffusionのライセンスを参照して、モデルで出力される画像の所有権や著作権について確認しておきます。
Amazon BedrockコンソールのStable Diffusion XLモデル画面にあるEnd User License Agreement (EULA)によるとユーザーとStabilityの間においてユーザーは適用される法律で許可される範囲で本サービスを使用して生成したコンテンツを所有すると記載されています(※正確な全容はライセンスを確認してください)。
As between you and Stability, you own the Content that you generate using the Services to the extent permitted by applicable law
また、Stability AIでStable DiffusionがPublic Releaseとなった際の記事「Stable Diffusion Public Release — Stability AI」ではモデルが「Creative ML OpenRAIL-M license」に基づいていることが記載されています。これによると、次のようにモデルを使用して生成した出力に対する権利をライセンスでは主張していません(※正確な全容はライセンスを確認してください)。
The Output You Generate. Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
次にStable Diffusionのライセンスに記載されている使用制限について確認します。
Amazon BedrockコンソールのStable Diffusion XLモデル画面にあるEnd User License Agreement (EULA)の「禁止される使用(Prohibited Uses)」から一部分を取り上げると次のような目的に使用しないことが記載されています(※正確な全容はライセンスを確認してください)。
規約やポリシーに違反すること、個人情報を含むこと、第三者のプライバシー・肖像権・その他の権利(知的財産権を含む)を侵害すること、犯罪行為を促進すること、性的なコンテンツを生成すること、中傷・脅迫・嫌がらせをすることなど
「Creative ML OpenRAIL-M license」の使用制限(Use Restrictions)から一部分を取り上げると次のような目的に使用しないことが記載されています(※正確な全容はライセンスを確認してください)。
法令に違反する使用目的、未成年者搾取目的、他者に危害を加える目的、検証可能な虚偽情報の生成目的、個人に危害を加えるための個人情報の生成目的、中傷・誹謗・嫌がらせ目的、医学的アドバイスを提供する目的など
このようにライセンスを確認すると、ライセンスに記載されている条件や使用制限を遵守すればモデルで生成された画像は自由に使用できることが読み取れます。
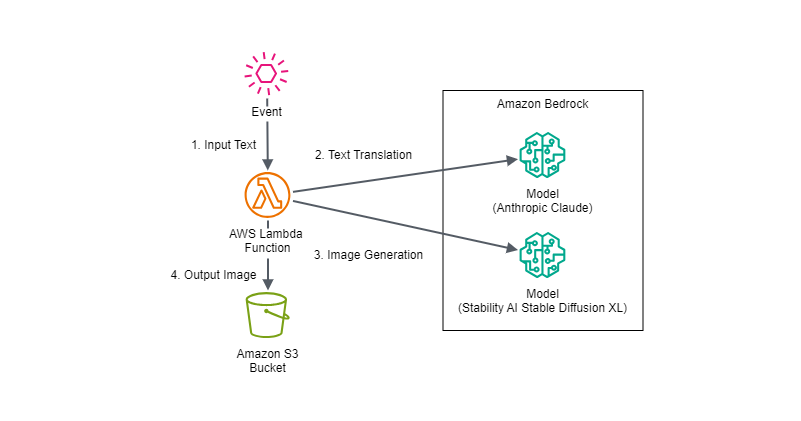
構成図
今回はAWS Lambda関数からAnthropic ClaudeとStability AI Stable Diffusion XLのモデルを実行する際の入出力やパラメータ調整での出力の変化を特に確認したかったため、構成自体は次のようなシンプルなものにしています。
AWS Lambda関数にEvent入力するAWSサービスはAmazon API Gateway、Amazon EventBridgeなど様々な可能性が考えられますが、Eventパラメータは使用するAWSリソースに合わせてマッピングやトランスフォーマーを使用したり、AWS Lambda側のフォーマットを変更したりする想定です。
実装例
今回はAWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行するようにAWS Lambda関数を実装しています。
実装でのポイント、工夫、注意点などには次のものが挙げられます。
- 各モデルに指定するパラメータに対する出力の変化を確認したかったので主要な各モデルのパラメータはEventで指定できるようにした
- SDXLに入力するPromptに「execution」に関する文字列があると「One or more prompts contains filtered words.」のエラーが出るので、Claudeの英訳した出力に「execution」に関する文字列を使用しないようにPromptで指示した
- Promptで指示してもClaudeでテキストを英訳した出力に「Here is the translation:\n\n」のようなプレフィックスを出力する場合があるので除去する処理を入れた
- SDXLの画像を生成するPromptは次のようにして、英訳テキストからインスパイアされた最高品質で意外性と独自性があり、人のいない風景または宇宙の写真を指示した
A Top quality, unexpected and original landscape or space photo without people inspired by "{translated_user_prompt}".
今回モデルを実行する際の入出力やパラメータ調整での出力の変化を特に確認したかったため、各モデルで使用するPromptはシンプルなものになっていますが、工夫をすれば精度や出力のコントロールをより理想に近づけるように調整できると考えられます。
※本記事執筆時点ではAWS Lambda関数のデフォルトのAWS SDK for Python(Boto3)ではbedrock、bedrock-runtimeのClientがまだ呼び出せなかったため、以降では最新のAWS SDK for Python(Boto3)をLambda Layerに追加してbedrock-runtimeのClientを使用しています。
import boto3 import json import os import sys import re import base64 import datetime region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) s3_client = boto3.client('s3', region_name=region) def lambda_handler(event, context): ##入力するイベントのフォーマット #{ # "input_text": "<画像生成のインスピレーションとして使用するテキスト>", # "output_s3_bucket_name": "<生成した画像を出力するAmazon S3バケット>", # "claude_temperature": <Claudeに指定するtemperatureパラメータ値>, # "claude_top_p": <Claudeに指定するtop_pパラメータ値>, # "claude_top_k": <Claudeに指定するtop_kパラメータ値>, # "claude_max_tokens_to_sample": <Claudeに指定するclaude_max_tokens_to_sampleパラメータ値>, # "sdxl_cfg_scale": <SDXLに指定するcfg_scaleパラメータ値>, # "sdxl_steps": <SDXLに指定するstepsパラメータ値> #} result = {} try: input_text = event['input_text'] claude_temperature = event['claude_temperature'] claude_top_p = event['claude_top_p'] claude_top_k = event['claude_top_k'] claude_max_tokens_to_sample = event['claude_max_tokens_to_sample'] sdxl_cfg_scale = event['sdxl_cfg_scale'] sdxl_steps = event['sdxl_steps'] #SDXLに入力するPromptに「execution」に関する文字列があると「One or more prompts contains filtered words.」のエラーが出るので訳文に使用しないように指示する。 input_prompt_for_claude = f'You are a professional translator. Please translate the text under "-----" into English and output only the translated text. However, please do not use the word "execution".\n-----\n{input_text}' print(f'input_prompt_for_claude: {input_prompt_for_claude}') claude_res = bedrock_runtime_client.invoke_model( modelId='anthropic.claude-v2', # 使用するモデルを指定する識別子。 contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) body=json.dumps({ "prompt": f'\n\nHuman:{input_prompt_for_claude}\n\nAssistant:', # <prompt>の部分をユーザーが入力したPromptに置き換える。 "temperature": claude_temperature, # temperatureの値を指定する。(デフォルト: 0.5、最小値: 0、最大値: 1) "top_p": claude_top_p, # topPの値を指定する。(デフォルト: 1.0、最小値: 0、最大値: 1.0) "top_k": claude_top_k, # topKの値を指定する。(デフォルト: 250、最小値: 0、最大値: 500) "max_tokens_to_sample": claude_max_tokens_to_sample, # トークンの最大数であるmaxTokensの値を指定する。(デフォルト: 200、最小値: 0、最大値: 8,000) "stop_sequences": ["\n\nHuman:"] # 指定された文字列またはシーケンスがテキスト生成中に検出されると、その時点でモデルはテキストの生成を停止する。 }) ) print('Claude Response Start-----') print(claude_res) print('Claude Response End-----') print('Claude Response Body Start-----') claude_res_body = json.loads(claude_res["body"].read()) print(claude_res_body) print('Claude Response Body End-----') print('Claude Response Completion Start-----') claude_res_completion = claude_res_body["completion"] print(claude_res_completion) print('Claude Response Completion End-----') #Promptで指示してもClaudeが「Here is the translation:\n\n」のようなプレフィックスを出力することがあるので、それを除去する処理 if ':\n' in claude_res_completion: translated_user_prompt = re.split(':\n', claude_res_completion)[1].strip() else: translated_user_prompt = claude_res_completion print(f'translated_user_prompt: {translated_user_prompt}') input_prompt_for_sdxl = f'A Top quality, unexpected and original landscape or space photo without people inspired by "{translated_user_prompt}".' print(f'input_prompt_for_sdxl: {input_prompt_for_sdxl}') sdxl_res = bedrock_runtime_client.invoke_model( modelId='stability.stable-diffusion-xl-v0', # 使用するモデルを指定する識別子。 contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) body=json.dumps({ "text_prompts": [ {"text": input_prompt_for_sdxl} # <prompt>の部分をユーザーが入力したPromptに置き換える。 ], #"seed": 20230928, # Seedの値を設定する。初期のノイズ設定を決定する。以前の実行と同じシード、同じ設定を使用すると、同様の画像を生成するための推論ができる。この値を設定しない場合はランダムな値が設定される。 "cfg_scale": sdxl_cfg_scale, # Prompt strength(プロンプト強度)の値を設定する。最終的な画像がプロンプトをどれだけ反映するかを決定する。数値を小さくすると、生成におけるランダム性を増やすことができる。(デフォルト: 10、最小値: 0、最大値: 30) "steps": sdxl_steps # Generation step(生成ステップ)の値を設定する。画像がサンプリングされる回数を決定する。ステップ数を増やすと、より正確な結果が得られることがある。(デフォルト: 5、最小値: 0、最大値: 150) }) ) print('SDXL Response Start-----') print(sdxl_res) print('SDXL Response End-----') print('SDXL Response Body Start-----') sdxl_res_body = json.loads(sdxl_res["body"].read()) print(sdxl_res_body) print('SDXL Response Body End-----') print('SDXL Response Artifact Start-----') claude_res_artifact= sdxl_res_body.get("artifacts")[0].get("base64") print(claude_res_artifact) print('SDXL Response Artifact End-----') print('SDXL Response Artifact Decoded Start-----') claude_res_artifact_decoded= base64.b64decode(claude_res_artifact) print(claude_res_artifact_decoded) print('SDXL Response Artifact Decoded End-----') output_s3_bucket_name = event['output_s3_bucket_name'] output_s3_key = f'{translated_user_prompt}_{datetime.datetime.now().strftime("%y%m%d_%H%M%S")}.png' s3_client.put_object(Bucket=output_s3_bucket_name, Key=output_s3_key, Body=claude_res_artifact_decoded) result = { "status": "SUCCESS", "output_s3_bucket_url": f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}' } except Exception as ex: print(f'Exception: {ex}') tb = sys.exc_info()[2] err_message = f'Exception: {str(ex.with_traceback(tb))}' print(err_message) result = { "status": "FAIL", "error": err_message } return result
実行内容
パラメータの設定
実装したAWS Lambda関数へ渡す次のようなフォーマットのEventパラメータを様々な値に変更して出力の変化を確認しました。
※SDXLのseedはランダムなものが設定されます。
{ "input_text": "<画像生成のインスピレーションとして使用するテキスト>", "output_s3_bucket_name": "<生成した画像を出力するAmazon S3バケット>", "claude_temperature": <Claudeに指定するtemperatureパラメータ値>, "claude_top_p": <Claudeに指定するtop_pパラメータ値>, "claude_top_k": <Claudeに指定するtop_kパラメータ値>, "claude_max_tokens_to_sample": <Claudeに指定するclaude_max_tokens_to_sampleパラメータ値>, "sdxl_cfg_scale": <SDXLに指定するcfg_scaleパラメータ値>, "sdxl_steps": <SDXLに指定するstepsパラメータ値> }
以降では、それらの試行の中でも次のようにClaudeはデフォルトのパラメータ設定、SDXLはPrompt strengthとGeneration stepを最大値にした設定で出力された英訳テキストと画像を紹介します。
{ "input_text": "<画像生成のインスピレーションとして使用するテキスト>", "output_s3_bucket_name": "<生成した画像を出力するAmazon S3バケット>", "claude_temperature": 0.5, "claude_top_p": 1.0, "claude_top_k": 250, "claude_max_tokens_to_sample": 200, "sdxl_cfg_scale": 30, "sdxl_steps": 150 }
想定するシナリオ(入力データの内容)
英訳の対象となるinput_textには私が今まで書いてきたブログ記事のタイトルを使用して、英訳されたブログ記事のタイトルからインスパイアされた画像の出力を試みました。
記事一覧(小西秀和) - NRIネットコムBlog
これがうまくいくのであればブログ記事のOGP画像(アイキャッチ画像、サムネイル画像)をブログ記事のタイトルから自動的に生成できるのではと思ったからです。
それでは、ブログ記事タイトル、Claude出力英訳テキスト、SDXL入力Prompt、SDXL出力画像の組み合わせを見ていきましょう。
実行結果
私が今まで書いてきたブログ記事の中でもタイトルに含まれる単語が画像としてイメージ化しやすいものについて実行した結果を、ブログ記事タイトル、Claude出力英訳テキスト、SDXL入力Prompt、SDXL出力画像の組み合わせで紹介します。
実行例1: Bedrock(岩盤)という単語を含むタイトル
<入力データ(ブログ記事タイトル)>
Amazon Bedrockの基本情報とRuntime APIの実行例まとめ - 参考資料、モデルの特徴、価格、使用方法、トークンと推論パラメータの説明
<Claude出力英訳テキスト>
Summary of Amazon Bedrock's basic information and Runtime API usage examples - Reference materials, model features, pricing, usage, explanation of tokens and inference parameters
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "Summary of Amazon Bedrock's basic information and Runtime API usage examples - Reference materials, model features, pricing, usage, explanation of tokens and inference parameters".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'Summary of Amazon Bedrock's basic information and Runtime API usage examples - Reference materials, model features, pricing, usage, explanation of tokens and inference parameters'.
※予想通りBedrock(岩盤)がメインの画像になっています。実行例2: Aurora、Neptuneという単語を含むタイトル
<入力データ(ブログ記事タイトル)>
クォーラムモデルを使用したAWSデータベースサービスの違い、共通点の比較 -Amazon Aurora、Amazon DocumentDB、Amazon Neptuneの比較表 -
<Claude出力英訳テキスト>
A comparison table of the differences and similarities between AWS database services using the quorum model - Comparing Amazon Aurora, Amazon DocumentDB, Amazon Neptune
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "A comparison table of the differences and similarities between AWS database services using the quorum model - Comparing Amazon Aurora, Amazon DocumentDB, Amazon Neptune".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'A comparison table of the differences and similarities between AWS database services using the quorum model - Comparing Amazon Aurora, Amazon DocumentDB, Amazon Neptune'.
※予想通りAuroraがメインの画像になっています。ただ、Neptuneも背景に混ぜてほしいという期待はありました。実行例3: Ground Station(衛星地上局)という単語を含むタイトル
<入力データ(ブログ記事タイトル)>
【仮想試験】AWS Ground Stationの練習問題を作ってみた -AWSに関する設問・解答の作り方-
<Claude出力英訳テキスト>
Creating Practice Questions for AWS Ground Station - How to Create AWS-related Questions and Answers
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "Creating Practice Questions for AWS Ground Station - How to Create AWS-related Questions and Answers".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'Creating Practice Questions for AWS Ground Station - How to Create AWS-related Questions and Answers'.
※衛星地上局とは異なる気がしますが、それに似たような建物がメインの画像になっています。実行例4: Route(道、道路、経路)という単語を含むタイトル
<入力データ(ブログ記事タイトル)>
歴史・年表でみるAWSサービス(Amazon Route 53編) -機能一覧・概要・アップデートのまとめ・入門-
<Claude出力英訳テキスト>
History and Timeline of AWS Services (Amazon Route 53 Edition) - Summary of Features, Overview, Updates, and Introduction
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "History and Timeline of AWS Services (Amazon Route 53 Edition) - Summary of Features, Overview, Updates, and Introduction".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'History and Timeline of AWS Services (Amazon Route 53 Edition) - Summary of Features, Overview, Updates, and Introduction'.
※予想通り道路がメインの画像になっています。実行例5: Bridge(橋)という単語を含むタイトル
<入力データ(ブログ記事タイトル)>
歴史・年表でみるAWSサービス(Amazon EventBridge編) -機能一覧・概要・アップデートのまとめ・入門、Amazon CloudWatch Eventsとの違い-
<Claude出力英訳テキスト>
A History and Timeline of AWS Services (Amazon EventBridge Edition) - Summary of Features, Overview, Updates, Introduction, Differences from Amazon CloudWatch Events
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "A History and Timeline of AWS Services (Amazon EventBridge Edition) - Summary of Features, Overview, Updates, Introduction, Differences from Amazon CloudWatch Events".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'A History and Timeline of AWS Services (Amazon EventBridge Edition) - Summary of Features, Overview, Updates, Introduction, Differences from Amazon CloudWatch Events'.
※橋はこれから架けるようです。。。EventBridgeという単語だったこともあり、全体としてイメージを具現化しにくいタイトルだったのかもしれません。実行例6: この記事そのもののタイトル
<入力データ(ブログ記事タイトル)>
Anthropic Claudeで英訳したテキストをもとにStability AI Stable Diffusion XL(SDXL)で画像を生成するAmazon Bedrockの使用例
<Claude出力英訳テキスト>
An example of using Amazon Bedrock to generate images with Stability AI Stable Diffusion XL (SDXL) based on text translated into English by Anthropic Claude
<SDXL入力Prompt>
A Top quality, unexpected and original landscape or space photo without people inspired by "An example of using Amazon Bedrock to generate images with Stability AI Stable Diffusion XL (SDXL) based on text translated into English by Anthropic Claude".
<SDXL出力画像>

A Top quality, unexpected and original landscape or space photo without people inspired by 'An example of using Amazon Bedrock to generate images with Stability AI Stable Diffusion XL (SDXL) based on text translated into English by Anthropic Claude'.
※どうしてこうなったw いや、これこそ望んでいた意外性だ。。。おそらく、サービス名やプロバイダー名である「Bedrock」「Diffusion」「Anthropic」あたりを直訳して総合的にイメージ化したのだと予想されます。
参考:
Anthropic Claude models - Inference parameters for foundation models - Amazon Bedrock
Stability.ai Diffusion models - Inference parameters for foundation models - Amazon Bedrock
Tech Blog with related articles referenced
まとめ
今回はAmazon BedrockのAnthropic Claudeで日本語のテキストを英訳してPromptを作成し、Stability AI Stable Diffusion XL(SDXL)で画像を生成する例を通して、ClaudeとSDXLの基本的な使い方について紹介しました。
実際に実装してみた所感としては、各モデルに指定するパラメータとPromptを工夫する余地がまだまだあると感じました。
上記の例ではSDXLのseedをランダムにしていたので毎回異なる画像が出力される傾向にありましたが、seedを固定した場合もモデルのパラメータやPromptの多少の変化で出力の内容が変化し、自分が予想もしない出力が得られることもありました。
ただ、その予想外の出力が自分の中では良いものだと感じるものも多くあったため、意外性も含めて自分が納得のいく出力が得られるようにモデルをコントロールできるようになれるとより実用性が高まるのだろうと思います。
このようにPrompt Engineeringの重要性を身を持って体験したので、各モデルに合わせたパラメータやPromptの工夫やコントロールについてさらに調査していきたいと考えています。
そして、このようなClaudeとSDXLなどの複数モデルの組み合わせを、AWS IAMを使用した認証やAWS SDKといった従来のAWSリソースと同様の枠組みで柔軟かつセキュアに実行できることがAmazon Bedrockの利点です。
これからも今回のようにAmazon Bedrockをアップデート、実装方法、他のサービスとの組み合わせなどの観点でウォッチしていきたいと思います。
