本記事は
AWSアワード記念!夏のアドベントカレンダー
19日目の記事です。
🎆🏆
18日目
▶▶ 本記事 ▶▶
20日目
🏆🎆
こんにちは、堤です。
現在、AWSアワード記念!夏のアドベントカレンダーと題しまして日々記事が投稿されています。 毎日面白い記事が投稿されるので、読むのが楽しみです。 そんなネットコムブログも2024年7月29日現在で669本ものブログ記事があり、とてもそのすべての記事を追いきれなくなってきました。 今回はそんな自分のために、Embeddingモデルを使ったブログ検索システムを作成してみました。
Embeddingとは
そもそもEmbedding(埋め込み表現)とは何かについて簡単に説明します。
Embeddingとは、テキストデータや画像データなどを数値のベクトルデータに変換を行うことです。Embeddingを行うことで、データ間の関係や類似性を定量的に把握することができます。
例として、「フランス」、「パリオリンピック」、「日本」、「東京オリンピック」という単語のEmbeddingが以下のように2次元で表されるとします。

この時、「東京オリンピック」- 「日本」+ 「フランス」 = 「パリオリンピック」 という数値的な計算を行うことができ、それが意味的な演算と一致するのがEmbeddingの特徴です。
今回はAmazon BedrockのEmbeddingモデルを使っていきたいと思います。その中でも今回は、Amazonが提供するモデルであるAmazon Titan Text Embedding V2を使用していきます。
検索システム
では検索システムを作成していきます。今回はユーザーがクエリを入力するとそれに近いタイトルの記事を持ってきてくれるような仕組みにしたいと思います。
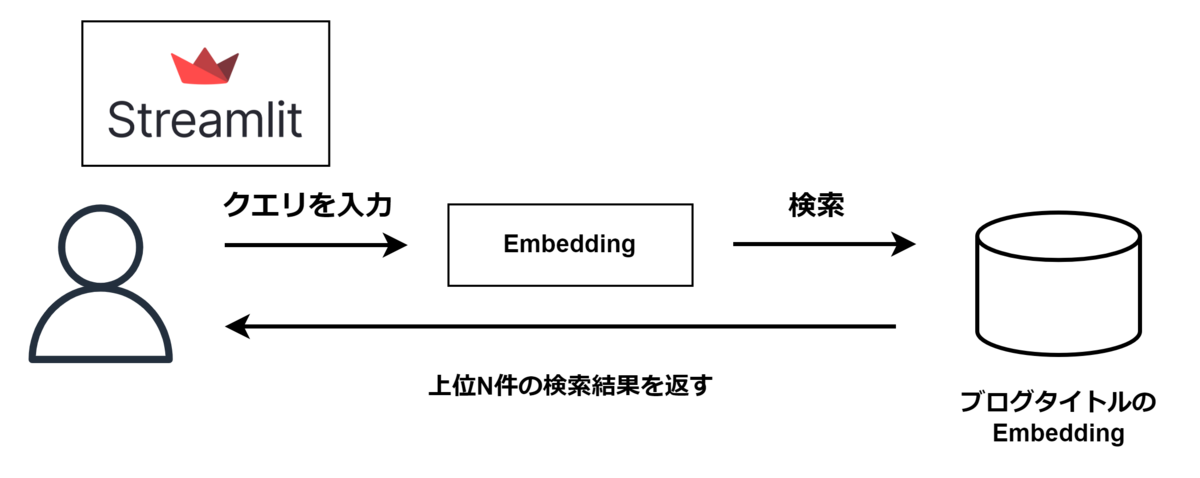
Embeddingの作成
Amazon Titan Text Embedding V2を使ってベクトル化していきます。今回はブログのタイトルのEmbeddingを取得していきたいと思います。
使用したコードは以下です。
import json import boto3 bedrock_client = boto3.client('bedrock-runtime', region_name="us-east-1") def get_embeddings(input_str: str): input_body = { "inputText": input_str } input_body_bytes = json.dumps(input_body).encode('utf-8') response = bedrock_client.invoke_model( accept="*/*", modelId="amazon.titan-embed-text-v2:0", body= input_body_bytes, contentType="application/json", ) embeddings = json.loads(response.get("body").read()).get("embedding") return embeddings # 利用例 embeddings = [ get_embeddings(title) for title in titles]
modelIdには使用するEmbeddingモデルのidを入力します。今回はAmazon Titan Text Embedding V2を使いたいので、amazon.titan-embed-text-v2:0と入力しました。
こちらを別途取得したすべてのブログタイトルについて適用し、それぞれのタイトルのEmbeddingを取得します。
可視化してみる
取得したEmbedingを確かめてみましょう。
print(embeddings[0])
出力
[-0.049021535, 0.004446832, -0.00035372525, -0.039319355, 0.011234102, 0.027744826, 0.030808672, 0.019149037, -0.00872345, 0.010893674, -0.0013404326, 0.0548088, -0.026383117, 0.0030425692, .....
はい。当たり前ですがただの数字の羅列なので人間には解釈することができません。Amazon Titan Text Embedding V2ではデフォルトで1024次元のベクトルが生成されます。人間が解釈できる形にするには、このベクトルの次元を削減し、2次元または3次元空間にしてあげる必要があります。
次元削減手法にはPCA(主成分分析)やt-SNEなどの手法があります。これらの詳細な説明には踏み込みませんが、今回はその中でもPCA(主成分分析)を使って2次元に次元削減を行い、データの可視化を行ってみたいと思います。
Pythonであればこれらはライブラリで実装されているので、比較的簡単に行えます。
from sklearn.decomposition import PCA # PCAで2次元に圧縮 pca = PCA(n_components=2) reduced_embeddings = pca.fit_transform(embeddings) # 結果の確認 print(reduced_embeddings[:5])
結果
array([[-0.14040512, 0.00833408],
[ 0.05104811, -0.15738875],
[-0.11406036, -0.06297843],
[ 0.02934804, -0.12272311],
[ 0.00392865, -0.09417768]])
結果を見てわかる通り、もとは1024次元あったベクトルが2次元の配列になっていることが分かります。
では可視化してみます。
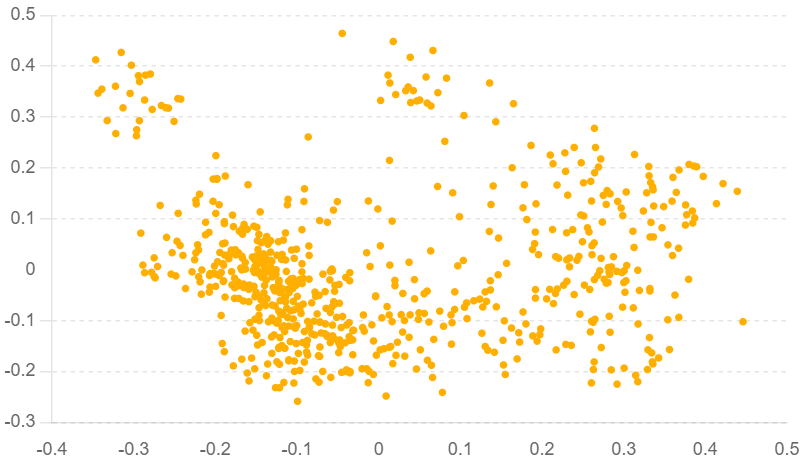
可視化するとなんとなく4つのグループに分かれていることが分かります。実際にデータを確かめてみると
- 左上のグループ
- ブログイベント告知の記事
- 右上のグループ
- 勉強会告知の記事
- 左下のグループ
- AWS以外の技術ブログ
- 右下のブログ
- AWS関連の技術ブログ
のようになっていることが分かりました。
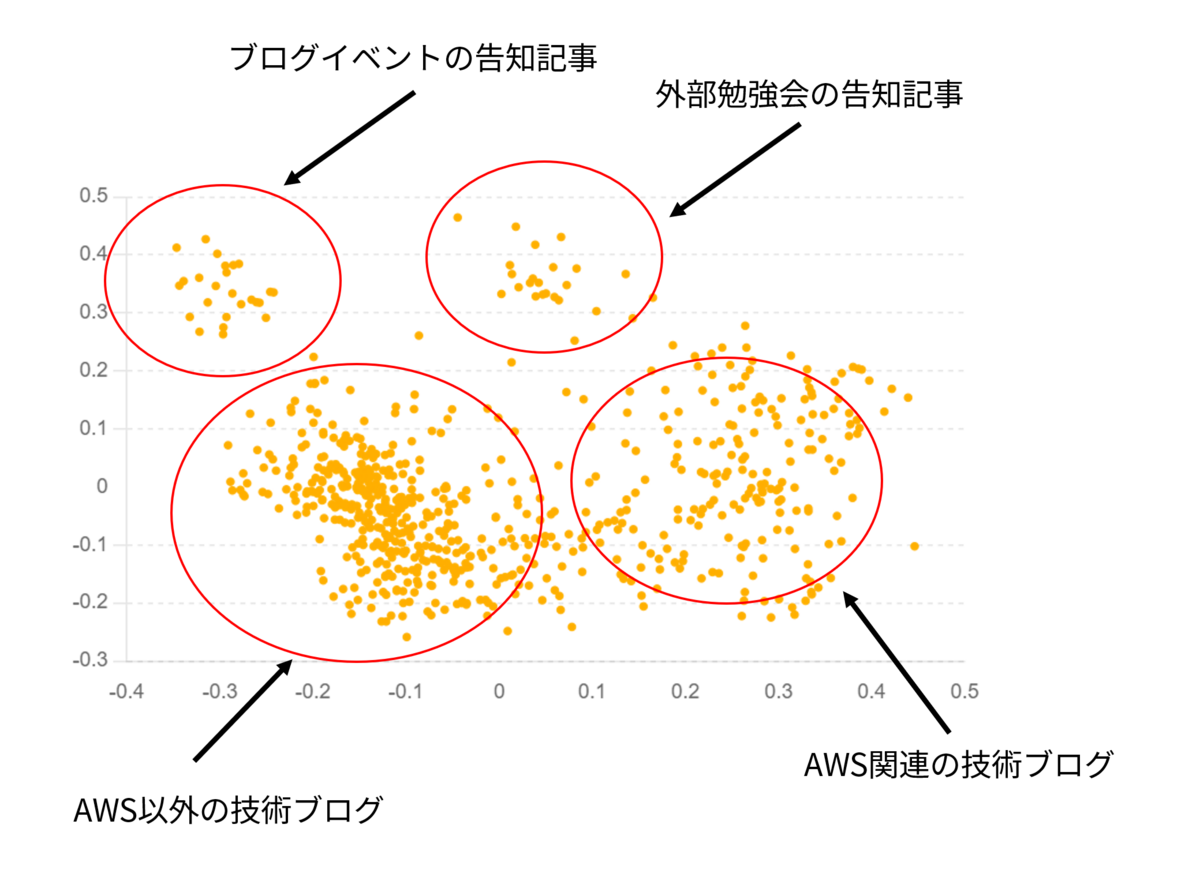
このことから、Embeddingがタイトルの意味を解釈できていることがなんとなくですがわかります。
検索
Embeddingの検索にはコサイン類似度がよく使われるのでこちらを使用します。簡単にPythonで書くと以下のような処理になります。
import numpy as np def cosine_similarity(vec1, vec2): dot_product = np.dot(vec1, vec2) norm_vec1 = np.linalg.norm(vec1) norm_vec2 = np.linalg.norm(vec2) return dot_product / (norm_vec1 * norm_vec2)
今回は画面もStreamlitを使って作ってみました。 コードは以下です。
コード全文
import json import os import boto3 import pandas as pd import numpy as np from sklearn.metrics.pairwise import cosine_similarity import streamlit as st bedrock_client = boto3.client('bedrock-runtime', region_name="us-east-1", verify=False) def get_embeddings(input_str: str): input_body = { "inputText": input_str } input_body_bytes = json.dumps(input_body).encode('utf-8') response = bedrock_client.invoke_model( accept="*/*", body= input_body_bytes, contentType="application/json", modelId="amazon.titan-embed-text-v2:0", ) embeddings = json.loads(response.get("body").read()).get("embedding") return embeddings def find_similar_titles(query, title_vectors, titles, urls, top_n=5): # クエリをベクトル化 query_vector = np.array(get_embeddings(query)).reshape(1, -1) # コサイン類似度を計算 similarities = cosine_similarity(query_vector, title_vectors).flatten() # 類似度の高いタイトルを取得 similar_indices = similarities.argsort()[-top_n:][::-1] similar_titles = [(titles[i], urls[i], similarities[i]) for i in similar_indices] return similar_titles # Streamlitアプリケーションの設定 st.title("タイトル検索アプリ") st.write("クエリを入力すると、それに近いブログ記事を検索します") # クエリの入力 query = st.text_input("クエリを入力してください") if query: # 類似するタイトルの検索 similar_titles = find_similar_titles(query, embeddings_array, titles, urls) # 結果の表示 st.write("検索結果:") for title, url, similarity in similar_titles: st.write(f"**Title**: {title}") st.write(f"**URL**: {url}") st.write(f"**Similarity**: {similarity}") st.write("---")
使ってみる
Streamlitを起動して使ってみます。
「AWSのアカウント管理についての解説記事」を読みたいので聞いてみました。

どの記事もAWSのアカウントについての内容で、まずまずの精度です。
今度は自分が苦手な「AWSのネットワーク系の記事」を探してみます。
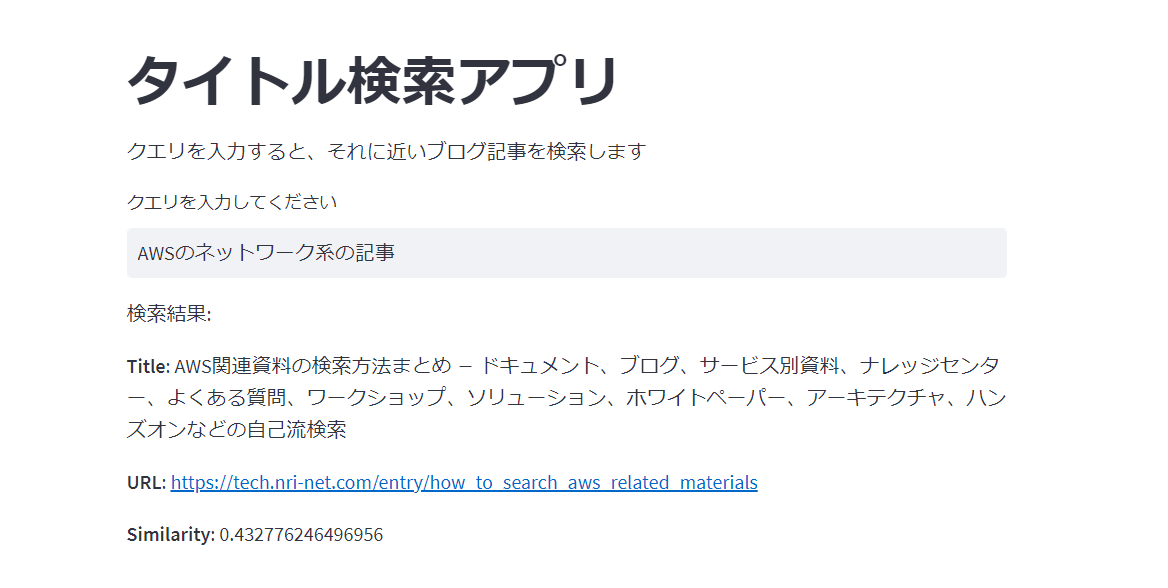
今度はあまり関係のない記事が続いています。1番目で表示されたのは小西さんのAWS関連資料の調べ方に関する記事です。この記事を使って自分で調べろということでしょうか?
というのは置いておいて、うまく検索できるような場合もあれば、あまり関連性のない記事が出てきてしまうというケースもあることが分かりました。これらの精度を向上させる手法を考えてみます。
精度向上のために
1. 記事の中身の内容も使う
今回はタイトルのみの情報を用いてEmbeddingを行いました。しかし、タイトルだけでは記事の内容をすべて反映しているとはいえません。より正確に記事の内容を反映するにはやはり本文の内容をEmbeddingする必要がありそうです。具体的には記事本文の内容をLLMで要約→その内容をEmbeddingするなどが考えられそうです。
2. ハイブリッド検索
お気づきの方もいらっしゃると思いますが、わざわざEmbeddingを使った検索をしなくてもキーワード検索でも十分に機能するケースも多いかと思います。しかし、文書自体の意味を把握して表記ゆれなどに強いEmbeddingを使ったセマンティック検索も多くの利点があります。これらのキーワード検索とセマンティック検索を組み合わせた手法を用いることで、さらに精度が向上するのではないかと考えています。
おわりに
今回はBedrockで使えるEmbeddingモデルを使ってみました。BedrockといえばLLM!みたいな感じですが、こちらも色々な用途に使えて面白そうです。今回は使用しませんでしたが、Amazon Titan Multimodal Embeddings G1モデルを使うと画像を含めたマルチモーダルな埋め込みを作成できるので、こちらも試してみたいです。
