本記事は
【Advent Calendar 2023】
7日目の記事です。
🎄
6日目
▶▶ 本記事 ▶▶
8日目
🎅
こんにちは堤です。先週開催されたre:Invent@ラスベガスに現地参加してきました。その中で『Innovate on enterprise data with generative AI & Amazon Q』というAmazon Qを企業内でどう利活用できるかを体験できるワークショップに参加したので内容をまとめます。
Amazon Qとは?
そもそもAmazon Qって何?って方のために簡単な概要を説明します。
Amazon Qは、Amazon Bedrockで構築された生成AIを搭載した企業用チャットアシスタントです。大きく分けてBusiness Use(ビジネス用途)とAWS Builder Use(開発者用途)で分かれています。Business Useでは質問の回答、メールメッセージの作成、テキストの要約、ドキュメントのアウトラインの作成、アイデアのブレインストーミングなど、従業員の生産性を向上させるタスクをサポートし、AWS Builder UseではAWSアプリケーションの構築、運用をサポートし、AWSに関する質問(サポート、アーキテクチャ、ベストプラクティス、ドキュメントなど)に回答してくれます。
他のAWSサービスとも連携しており、現時点では
- Amazon Q in AWS Chatbot
- Amazon Q in Amazon CodeCatalyst
- Amazon Q in Amazon Connect
- Amazon Q in Amazon QuickSight
- Amazon Q in Reachability Analyzer
これらのサービスと連携しています。今後もどんどん他のAWSサービスと連携が進んでいくんだろうなと考えています。
今回はこの中でもBusiness Useに焦点を当てたワークショップとなっています。
参加前
このセッションは予約できていなかったのでWalk Up(先着順)での参加となり、注目度が高く参加者が多いだろうなーと思ったので早めにいって並ぶことにしました。1時間半前から並んだときにはすでに10名くらいの方が並んでいました。その後もどんどん人が増えていき、最終的には写真のように大量の人が並んでいました。自分は早めに並んでいたこともあり無事参加することができました。


ワークショップの概要
ワークショップ説明文の日本語訳です。
多くの企業が急速な技術革新に直面しています。このワークショップでは、Amazon Qを使用して、従業員の生産性を向上させるカスタム生成AIアプリケーションを安全に構築する方法を学びます。Amazon Qを使用すると、セキュアなコネクターを通じて独自のデータを取り込み、アクセスポリシーを定義して、アプリケーションはユーザーが見ることを許可された情報でのみ応答し、応答はユーザーがアクセスすることを許可されたコンテンツのみが使用されていることを確認できます。参加にはノートパソコンが必要です。
ワークショップの内容
Amazon Qの概要
まずはAmazon Qの概要の説明がありました。今回は企業内での生産性向上に焦点があてられており、それらの活用例等の紹介がありました。

作成するアプリケーション
今回は以下のような構成のアプリケーションを作成していきます。
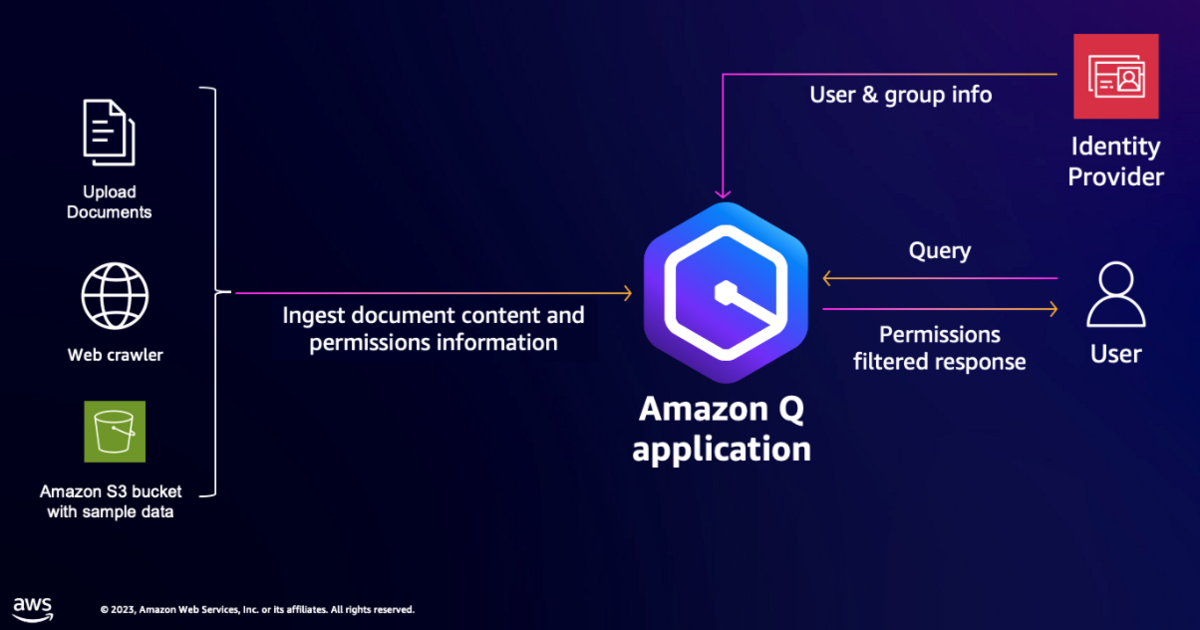
アップロードしたドキュメント、Webクローラーしたコンテンツ、S3上のファイルといった異なるデータソースのデータについてAmazon Qが回答を行い、さらにIdentity Providerによってユーザーごとに閲覧するデータを制限できるといったアプリになります。
Amazon Q アプリケーションの作成
まずはAmazon Q アプリケーションの作成を行います。 最初にアプリケーションの名前やロールの設定をしていきます。

その後Retrieverの設定を行います。今回は『Use native retriever』を選択しましたが、Kendraを使った既存のRetrieverも選択することができるようです。

最後にデータソースの設定を行います。画像のように多くのデータソースから選択する事ができます。
自分でファイルをアップロードすることもできますが、その場合はRetrieverができるまで少し待つ必要があるようです。

今回は保険会社という設定だったので保険会社のホームページのようなHTMLファイルをいくつかアップロードして回答してもらいます。こんな感じのファイルです。

アップロードします。
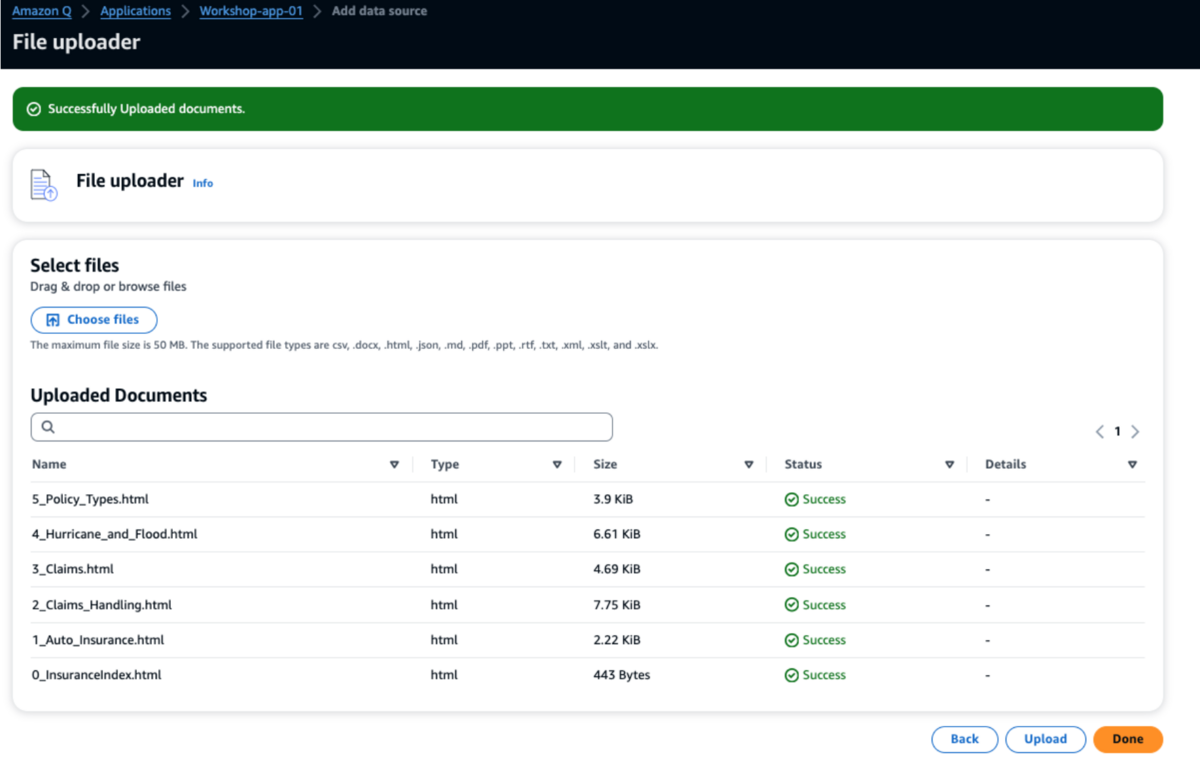
アプリケーションの設定から6つのファイルがアップロードされていることが確認できます。

チャットする
これで準備完了です。『Preview web experience』というところからWeb上でチャットすることができます。

今回はアップロードしたファイルについて、『What should a client do to file an insurance claim due to flood damage?』と質問してみます。
....がエラーになってしまいました。。

サポートの方曰く、キャパシティが足りていないためにエラーが起きているようで、他の参加者も皆エラーが起きてチャットできていないようでした。
ということでここからは残念ながらデモ動画を流しながらの説明となってしまい、実際にハンズオンを行うことはできませんでしたが、どのような機能が紹介されていたかを軽く紹介したいと思います。
ちなみに先程の質問は以下のような回答になるようです。回答の根拠となる文書も示してくれます。

Webクローラーデータの取り込み
Webクローラーデータの取り込みも同様にデータソースの設定から行います。URLを指定してソースの指定を行います。今回はヨセミテ国立公園のWikipediaページを指定していました。
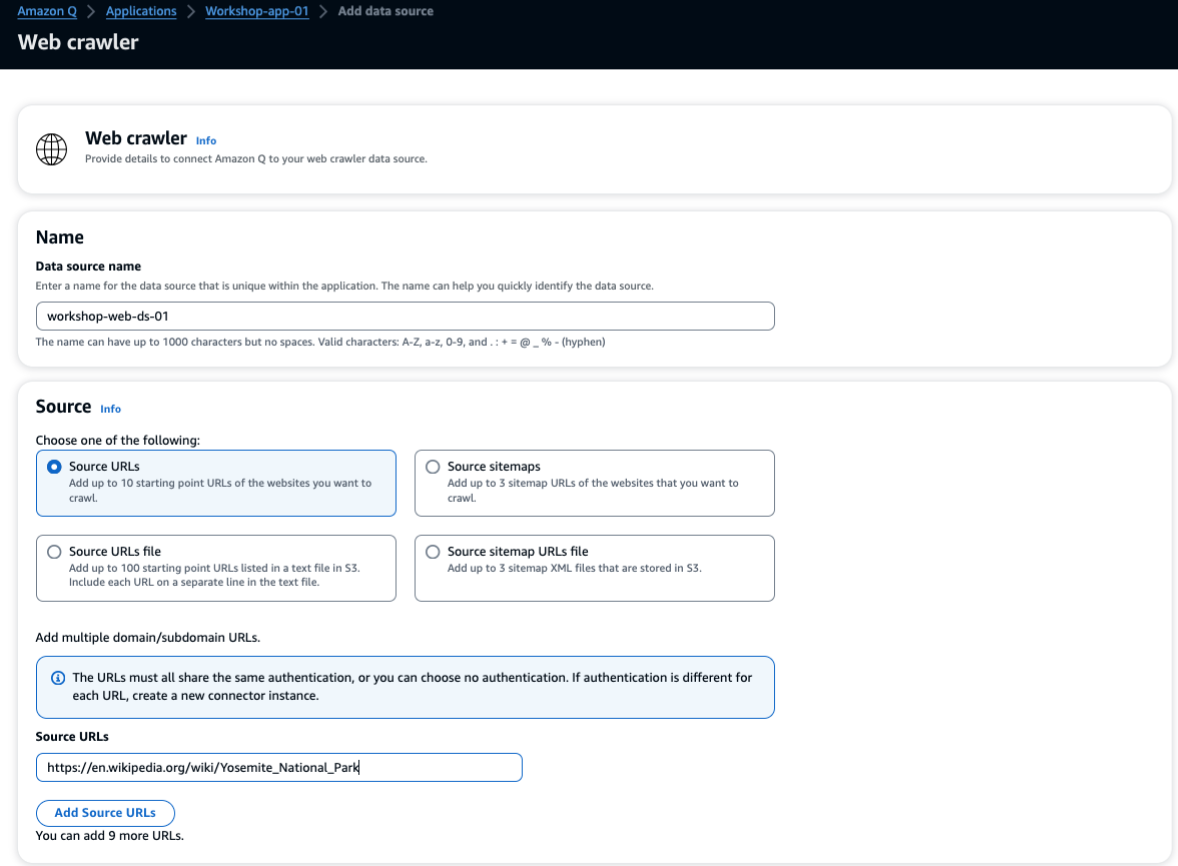
『Sync scope』では同期するドメインの範囲やどのくらいの階層までクローリングするかといった設定を行います。

『Sync run schedule』ではクローリングする頻度を選択できます。
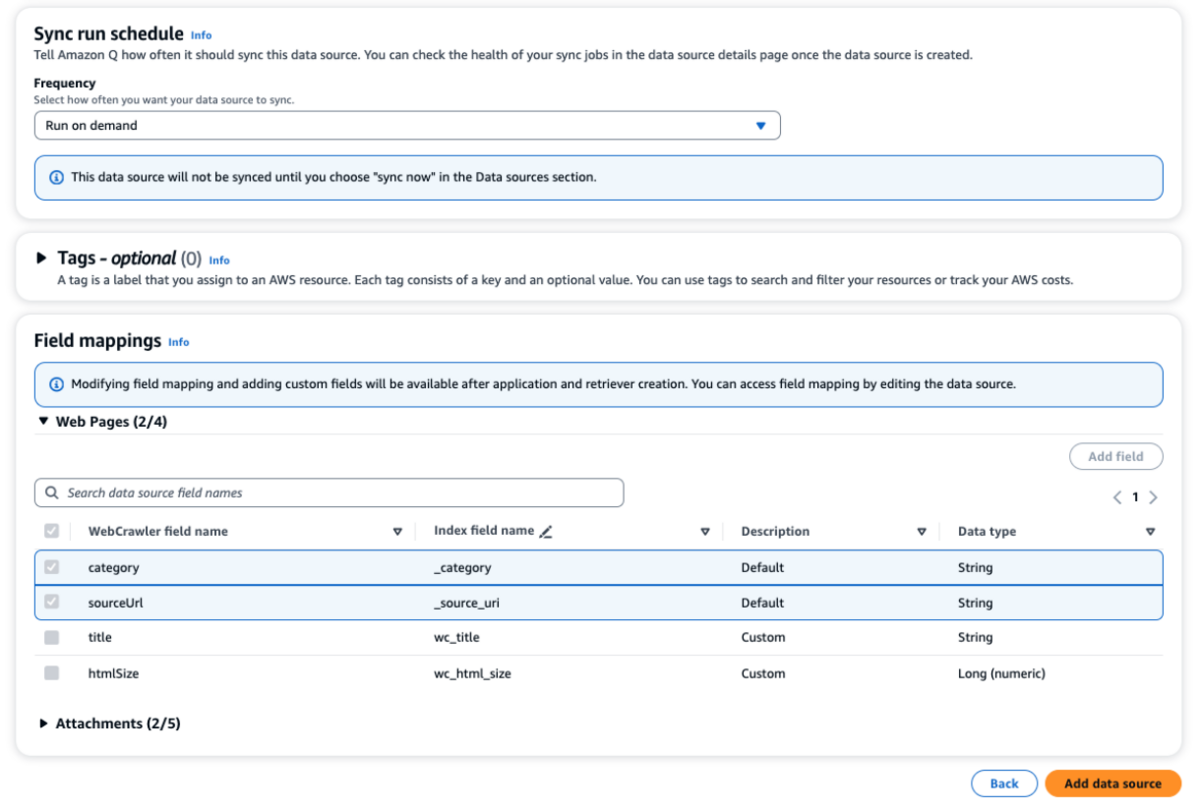
これも同期が完了するとチャットできるようになります。クローリングしたデータから回答を導きだしていることがわかります。

データソースのアクセスコントロール
同じ社内でも役職や部署によってデータの参照先を制限したいケースがあるかと思います。Amazon QではIdentity Providerを使ってユーザーごとのデータアクセスコントロールの設定ができます。
ユーザー
今回のワークショップでは以下のようなユーザーがいる想定となっています。
- pat_candella: ソリューションアーキテクトグループのメンバー。
- mateo_jackson: データベース分野の専門家であるソリューションアーキテクトグループのメンバー。
- john_doe: 機械学習分野の専門家であるソリューションアーキテクトグループのメンバー。
- mary_major: これらのグループには属していない。
- martha_rivera: 管理者グループのメンバー。
使用するデータ
今回はS3上のファイルを用います。使用しているS3バケットは、データソースとしてすべてのサンプルデータを「Data/」というフォルダに保管しており、サブフォルダーには「Best_Practices」、「General」、「Security」、「Well_Architected」、「Machine_Learning」、「Databases」という名前があります。
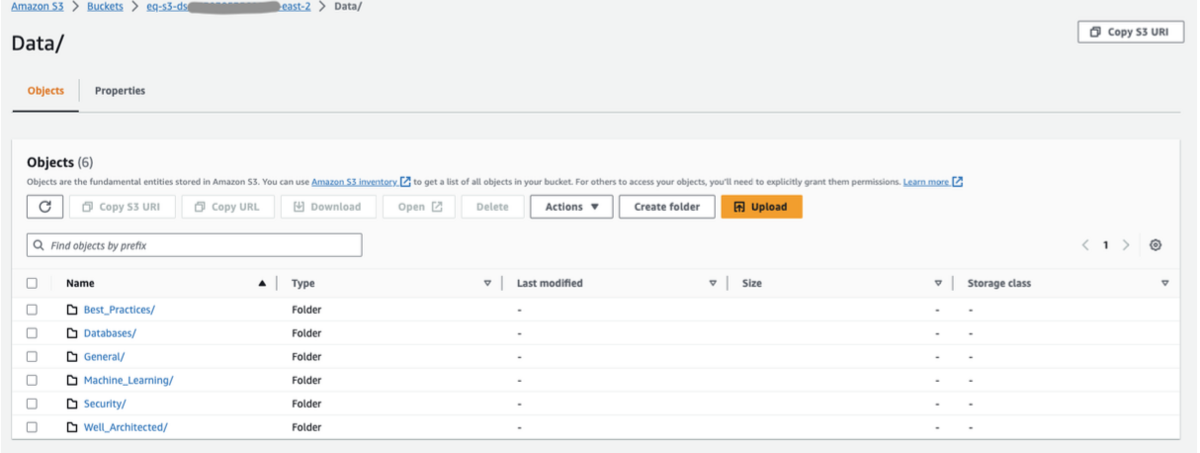
設定するACLファイル
ユーザーは所属するグループに基づいて異なるアクセス権限を持っており、そのためアクセスコントロールリスト(ACL)は以下のように設定されています。
- すべてのユーザーが「Best_Practices」と「General」のドキュメントにアクセスできます。
- ソリューションアーキテクト(SA)グループのメンバーは、「Best_Practices」、「General」、「Security」、「Well_Architected」のドキュメントにアクセスできます。
- データベース分野の専門家であるソリューションアーキテクト(DB_SME_SA)グループのメンバーは、「Best_Practices」、「General」、「Security」、「Well_Architected」、「Databases」のドキュメントにアクセスできます。
- 管理者(Admins)グループのメンバーは、すべてのドキュメントにアクセスできます。
上記のような設定はACLファイルで以下のように記述できます。
[ { "keyPrefix": "s3://NAME-OF-DATASOURCE-S3-BUCKET/Data/Security/", "aclEntries": [ { "Name": "SA", "Type": "GROUP", "Access": "ALLOW" }, { "Name": "DB_SME_SA", "Type": "GROUP", "Access": "ALLOW" } ] }, { "keyPrefix": "s3://NAME-OF-DATASOURCE-S3-BUCKET/Data/Well_Architected/", "aclEntries": [ { "Name": "SA", "Type": "GROUP", "Access": "ALLOW" }, { "Name": "DB_SME_SA", "Type": "GROUP", "Access": "ALLOW" }, { "Name": "ML_SME_SA", "Type": "GROUP", "Access": "ALLOW" }, { "Name": "Admins", "Type": "GROUP", "Access": "ALLOW" } ] }, { "keyPrefix": "s3://NAME-OF-DATASOURCE-S3-BUCKET/Data/Databases/", "aclEntries": [ { "Name": "DB_SME_SA", "Type": "GROUP", "Access": "ALLOW" }, { "Name": "Admins", "Type": "GROUP", "Access": "ALLOW" } ] }, { "keyPrefix": "s3://NAME-OF-DATASOURCE-S3-BUCKET/Data/Machine_Learning/", "aclEntries": [ { "Name": "ML_SME_SA", "Type": "GROUP", "Access": "ALLOW" } ] } ]
ユーザーごとの回答の違い
今回は『How to develop a well architected serverless application on AWS?』と同じ質問をしてユーザーごとの振る舞いの違いを確認していきます。
どのグループにも所属していないユーザー
どのグループにも所属していないmary_major@example.comの場合は以下のような回答になります。
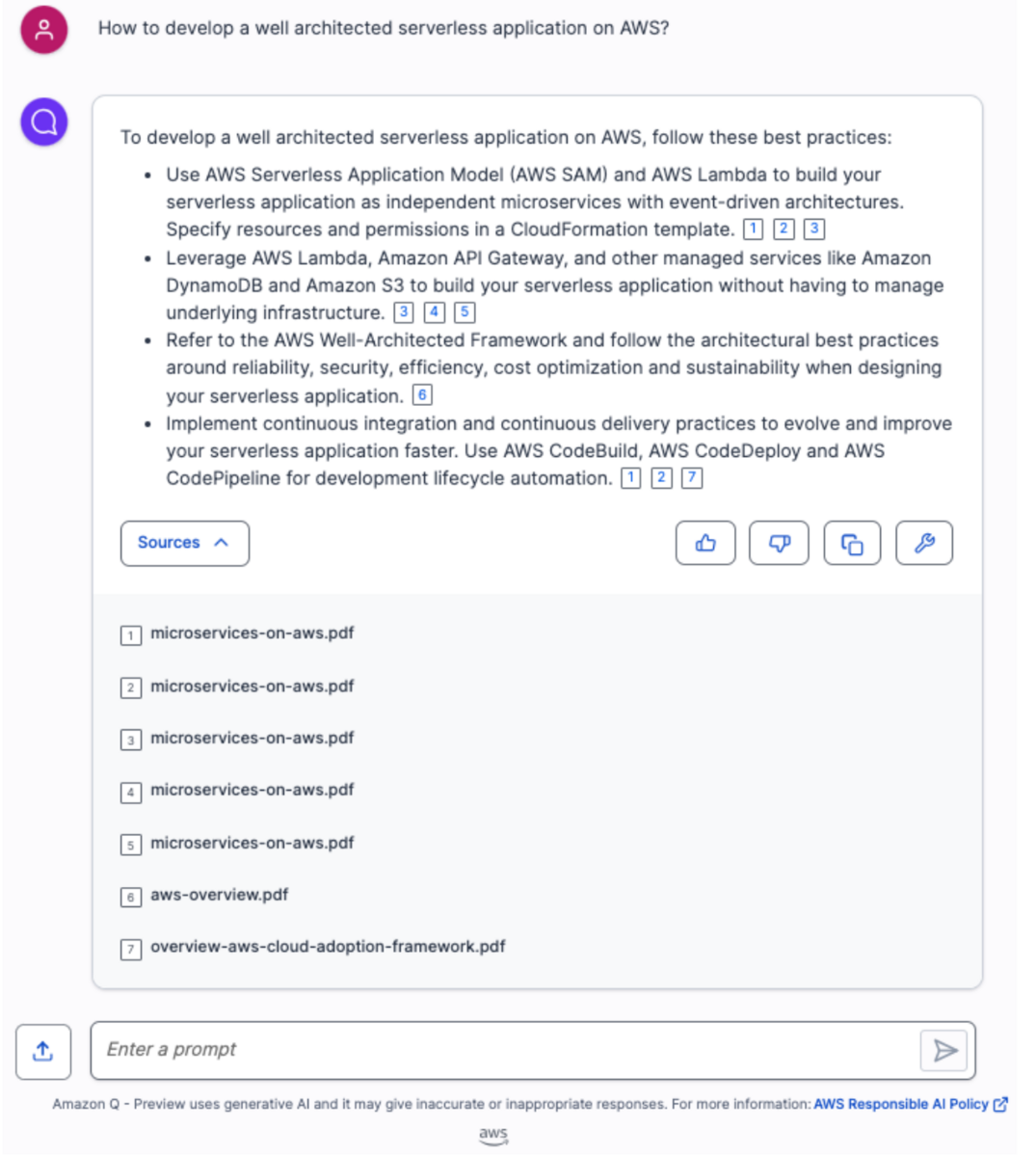
誰にでもアクセスできる「Best_Practices」と「General」のドキュメントに基づいて回答を行っています。
SAグループのユーザー
SAグループのユーザーpat_candella@example.comが同じ質問をした際の回答です。

今度は先程のユーザーとは異なり、SAのグループがアクセスできる「Well_Architected」のドキュメントを基に回答していることがわかります。
このようにACLでアクセス制御を行うことで、ユーザーごとに参照データを制限できることが確認できます。
まとめ
今回はトラブルによりすべての機能を体験することは残念ながらできませんでしたが、RAGなどを作り込む必要なく、社内チャットボットを簡単に作る事ができる手軽さは体感することができました。もう社内チャットボットは全部これでいい感がありますね。今後は実際のデータを使って回答精度などの検証ができたらなと考えています。