不正アクセスによるIDとパスワードの漏洩を受けて、MD5によるハッシュ化について話題になっていました。システムを作る上で、パスワードの管理や認証はどう設計すべきかを考えるために、少し整理をしてみます。もし事実誤認があれば、どしどしご指摘ください。
== 2023/8/21追記 ==
この記事は、ハッシュの保存の仕方一つとっても、沢山の対策方法が必要であるということをお伝えするために記載しています。そして、これから紹介する手法を取れば安全とお勧めしている訳ではないので、その点をご留意いただければと思います。攻撃手法に応じての対応策の変遷を知っていただくことで、セキュリティ対策は一度行えば安全というものではないことを知って頂くキッカケになれば幸いです。
== 追記終わり ==
パスワードのハッシュ化
まず最初にパスワードの保存方法です。何も加工しないで平文で保存するのは駄目というのは、だいぶ認知されるようになっていると思われます。ではどうするのか?ハッシュ化して保存するのが一般的です。そして、ここからが本題ですが、パスワードをただハッシュ化しても、今ではあまり意味がなくなりつつあります。
パスワードのハッシュ化とは?
まずハッシュ化です。ハッシュ化とは、データを不規則な文字列に変換する手法の総称です。どのような値に変換されるかは、ハッシュ化のアルゴリズム次第です。代表的なアルゴリズムとしては、MD5やSHA-1、SHA-256などがあります。同じ文字列を同一のアルゴリズムでハッシュ化すると、必ず同じハッシュ値となります。違う文字列から同一のハッシュ値に変換されることもあり衝突(コリジョン)と呼ばれます。この衝突は、ごく低い確率で自然発生もしますし、アルゴリズムの問題で故意に起こすことが可能な場合もあります。衝突はハッシュの信頼性の肝なのですが、ここでは割愛します。詳細は、こちらのブログをご参考ください。
ハッシュ値から元のパスワードを割り出す手法
では、このハッシュ値から元のパスワードを計算できるのか?ハッシュは不可逆という特性があるので、原則的には無理です。一方で、元のパスワードを割り出すこと自体は可能です。極端な例でいうと、元の文字列種が数字のみで1桁のみの文字列であれば、文字列もそこから変換されるハッシュ値もパターンは10通りです。すべて計算しておけば、ハッシュ値から元の文字列が割り出せますね。
この考え方を利用して、ハッシュ値から元のパスワードを割り出す手法の一つがレインボーテーブルです。== 2023/8/21追記 ==レインボーテーブルの詳しい説明は省略しますが、ハッシュ関数と還元関数を使い別のハッシュ値を解析する際にも利用できるようにする手法です。これを使うと比較的効率的に大量のパスワードを解析できます。== 追記終わり ==
ハッシュ値の計算はGPUを使った並列処理が可能です。今現在では、GPUの性能が非常に高くなっていて、秒間で何千億回の計算が可能となっています。この有り余る計算リソースを使って、ハッシュ値から元のパスワードを割り出すのが総当り攻撃(ブルートフォース攻撃)です。対象の文字列が8桁英数字だったとしたら、その組み合わせは約220兆パターンです。とんでもない量と思えますが、今のGPUであれば数十分程度で全ての組み合わせを計算できます。桁数が増えるごとに、計算量は飛躍的に増えます。長いパスワード長が推奨されるのは、こういった理由からです。
また、元の文字列が同じであればハッシュ値も同じなので、よく使われる単純なパスワードが特に危険になります。
ハッシュアルゴリズムの選択
ハッシュの説明の冒頭で、代表的なアルゴリズムとしてMD5やSHA-1、SHA-256があると説明しました。しかしパスワードのハッシュ化にあたって、どのハッシュを使っても良いという訳ではありません。MD5やSHA-1は、既に非推奨となっています。例えば、MD5であれば出力されるハッシュ値のビット長128ビットで32文字となります。SHA256はビット長256ビットで64文字分なので、随分小さいのが解ります。また、ハッシュ値を計算するコストも大きい・小さいがあります。総当たり攻撃(ブルートフォース攻撃)をする側にとっては、計算コストが小さい方が短い時間で割り出せます。MD5は、この計算コストが非常に小さいのが特徴です。一般的な利用目的では計算コストが小さいのはコンピューターリソースの消費が少なくメリットとなるのですが、パスワードのハッシュ化として利用する場合にはそこがデメリットとなります。それ以外にもMD5のハッシュ辞典のようなものが出回っているので、簡単に辞書攻撃されるというデメリットもあります。
では、どのハッシュアルゴリズムを使えばよいのでしょうか?一概に言うのは難しく、要件によっては業界で定められている規制・ガイドラインもあります。どれに準拠するかで、求められるものが違う場合があります。Webアプリケーションのセキュリティ分野のコミュニティであるOWASPでは、Password Storage Cheat Sheetという形でパスワード保護の考え方を公開していますので、参考にすると良いでしょう。
少なくとも非推奨になっているものは選ばないようにしましょう。
ソルトとペッパー、ストレッチング
パスワードから単純にハッシュ値を算出して保存するだけでは駄目というのが、何となく解ってきたと思います。では、どうすればいいのでしょうか?代表的な対処法としては、ソルトの利用です。ソルトとは、元の文字列にソルトと呼ばれる文字列を追加した上でハッシュ化する手法です。ソルト付きのハッシュ値から割り出しを行っても、割り出された文字列は元の文字列+ソルトの文字列になります。ここから元の文字列を割り出すには、さらに一手間かかります。
同一のソルトを利用すると?
一方で、ただソルトを使えば良いというものではありません。全てのパスワードに同じソルトを使えば、どうなるでしょうか?
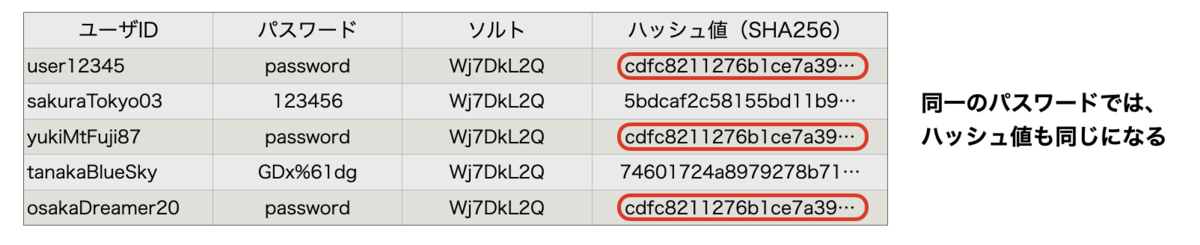
同一ソルトであれば、同じパスワードに対して同じハッシュ値に変換されます。現実的には、「123456」、「password」といったよく使われるパスワードというのが存在するので、同一のソルトでよく使われるパスワードであれば、攻撃者側は割り出しやすくなります。
パスワード毎のソルト
対処策としては、パスワード毎にソルトを用意することです。これにより、同じパスワードに対しても、異なったハッシュ値が算出されるようになります。

== 2023/8/21追記 ==
ソルトについては、パスワード毎と表記する方が適切なので変更しました。
== 追記終わり ==
ペッパー
ユーザー毎のソルトを用意するとして、それをどこに保存するのでしょうか?現実的な選択肢として、データベースが出てくると思います。そうすると、データベースに侵入された時点で、IDとハッシュ化されたパスワード、ソルトの組み合わせが一緒に漏洩することになります。これでいいのでしょうか?ここは議論が別れると思うのですが、半分良くて半分良くないです。(データベースに侵入されている時点で、良くないのですが)
まず半分良くての部分です。ソルトの目的は、究極的には元のパスワードを割り出し難くすることです。その目的から照らし合わせると、パスワード毎のソルトを利用することにより、パスワード毎に計算する必要が出てきます。つまり計算量が物凄く増えるので、元のパスワードの割り出しが困難になります。これが半分良いの理由です。
一方で、やはりソルト流出に対して耐性を強める必要が求められるケースがあります。そこで考えられたのが、ペッパーです。シークレットソルトとも呼ばれる事もあるようです。ペッパーは、ハッシュ値やソルトと別の場所に保存します。一般的には、HSMなどの機密性を高めたストレージ保存して、利用時に渡すといったことが多いです。AWSを利用するなら、パラメータストアやシークレットマネージャに保存するのもいいでしょう。このペッパーは、パスワード毎ではなく共通のケースが多いです。なぜ共通で良いのかは、ソルト自体がユニークであるためにパスワード毎に計算必要ということが保証されているからです。もしパスワード毎にペッパーを用意したとしても、攻撃者の計算回数は共通の場合と同じです。そのため、ソルトと一緒に流出する可能性を低減できれば充分だからです。
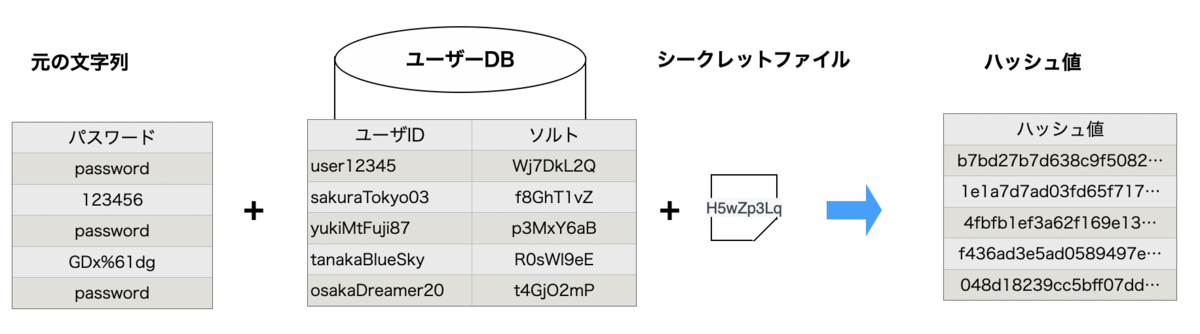
一方でDBまで侵入されているのであれば、ペッパーまで取得される可能性は高いという問題もあります。これについては、その通りだと思います。結局のところソルトやペッパーは、パスワード解析をできるだけ遅くし被害を低減するという考えに基づいています。ソルトとペッパーを同時に流出する可能性はゼロにはできないですが、分離することで対策はしやすくなります。またこれとは別に、ソルトに充分な長さが確保されているのであれば、そもそもペッパーが不要という考え方もあるようです。
ストレッチング
ペッパーとは別の観点で、攻撃者側の計算量を増やす緩和策があります。それがストレッチングです。ストレッチングとは、何度も繰り返しハッシュ化し元のデータの推測を困難にする手法です。ストレッチングの回数を増やせば増やすほど、元のパスワードの割り出しが困難になります。そのため、場合によっては数千~数万回のストレッチングがされることもあるそうです。一方で、システム側の負荷も高まるので、どれくらいのストレッチングをするのか、バランスを考える必要があります。

サイトをまたがった同一ID/パスワードの使いまわし
ここまでが、システム運用者側が考えられる対策です。一方で、システム運用者側では、どうしようも無いことがあります。それは、利用者がサイトをまたがって同一ID/パスワードを使い回すケースです。自分のサイトでは考えうる防御策を講じていても、他社が運用する弱いサイトからID/パスワードが漏洩して、それを利用してパスワードリスト攻撃される可能性があります。
そもそも攻撃者側としては、データベースに侵入した時点で、必要な情報は全て得られている可能性が高いです。その上で、更に手間を掛けてパスワードを割り出そうとするのは、他のより強固なシステムに対してのパスワードリスト攻撃を仕掛ける意図がある可能性が高いです。
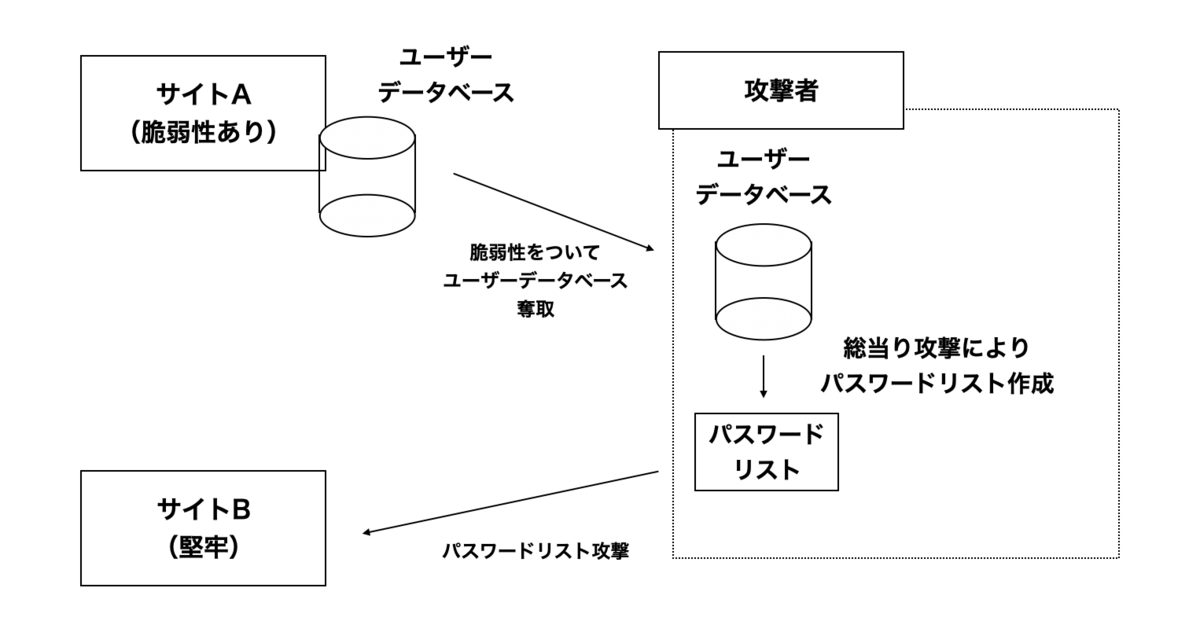
サイトをまたがったパスワードリスト攻撃の対策
では、パスワードリスト攻撃への対策はどうしたら良いのでしょうか?任意のログインIDを使わせないという方法も考えられますが、ユーザーの利便性を考えると取りづらい対策です。今主流の方法としては、二要素認証でしょう。IDとパスワード以外に、SMSやワンタイムパスワードなど、もう一つの認証要素を加える方法です。これだと、例えユーザーがID・パスワードを使いまわししても問題になる可能性は小さくなります。
これ以外でも、最近ではIDaaSと呼ばれる認証サービスなどを中心に、ログインを試みた側の総合的な情報をもとに怪しい振る舞いを検知して遮断するといった高度な防御策があります。例えば同一IPから何度も試行されているであったり、サービス利用の対象外であると思われる海外からのアクセスなどですね。具体的な検知方法の詳細は表に出てこないとは思いますが、AIによる検知などといったらこの手の手法が多いようです。
まとめ
MD5によるハッシュ化を起点に攻撃手法と対応策の変遷をお伝えし、セキュリティをとりまく難しさについてお伝えしました。パスワード一つをとっても、これだけの対策が必要になってきています。また、取るべき対策は年々増えていきます。これらに自前で追随し実装するのは、非常に大変だと思います。なので基本的には、認証部分は実績があり信頼性が高いモジュールや製品・サービスを使うことから考えていくくらいで良いと思います。大規模なシステムで膨大なユーザー数の場合は、自前で実装するという手段も考えられますが、それは専任のチームを作るぐらいの覚悟が必要くらいの難易度になりつつあるのではと考えています。いろいろな考え方があるとは思いますが一つの参考になれば幸いです。
