はじめに
こんにちは。2年目の大林です。 本ブログでは前回のブログ(Amazon CloudFrontのアクセスログ保存パスをAthena用に最適化してみた~part1~)の続きを書いていきたいと思います。 前回のブログでは、S3バケットに新規でアップロードされたログファイルに対してパス最適化処理を行う方法を紹介しました。 今回は、既にS3バケットにアップロードされているログファイルに対してパス最適化処理を行う方法を紹介したいと思います。
想定しているケース
ケース1
・CloudFrontのアクセスログが有効になっていて、既にS3バケットにログファイルが保存されている場合
・単一のS3バケットを使用したパス最適化を実施したい
ケース2
・CloudFrontのアクセスログが有効になっていて、既にS3バケットにログファイルが保存されている場合
・パス最適化処理の途中でエラーが起きた場合でもログファイルを消失したくない場合
ケース1
ケース1の設計と処理の流れ
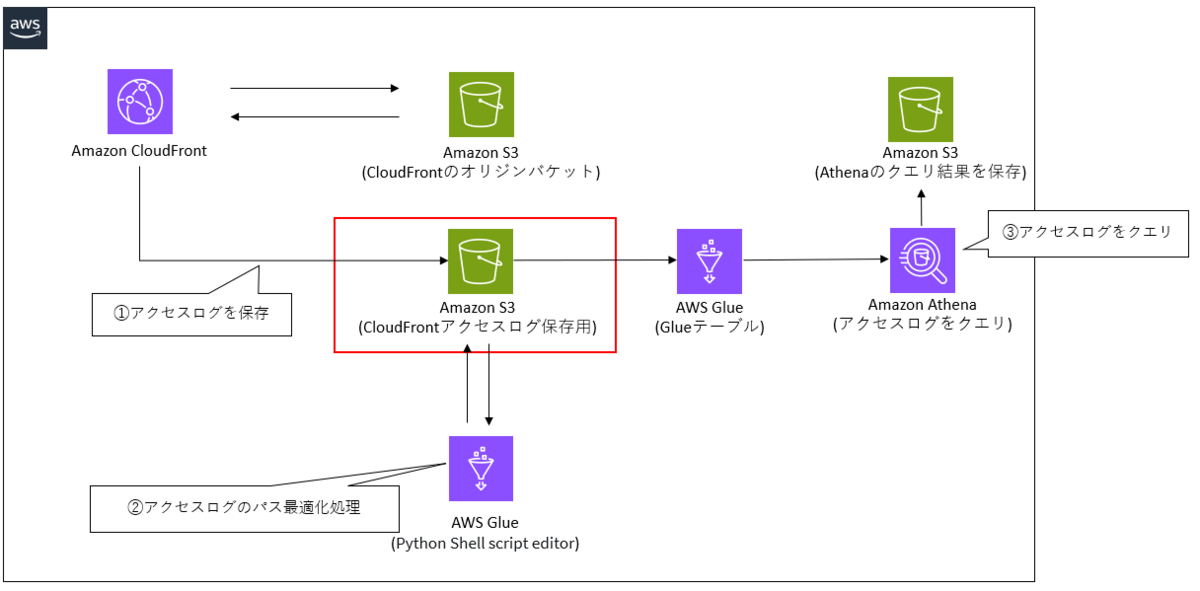
①Amazon CloudFrontのアクセスログがS3バケットに保存されている
②Glueを使用して、アクセスログ保存のパスを最適化する
・ログファイルをパス(ディストリビューション名/yyyy/mm/dd)を指定してコピーします。
・上記の処理が終了した時点で、パス最適化前と最適化後のログファイルが存在することになるのでパスが最適化できていないほうを削除します。
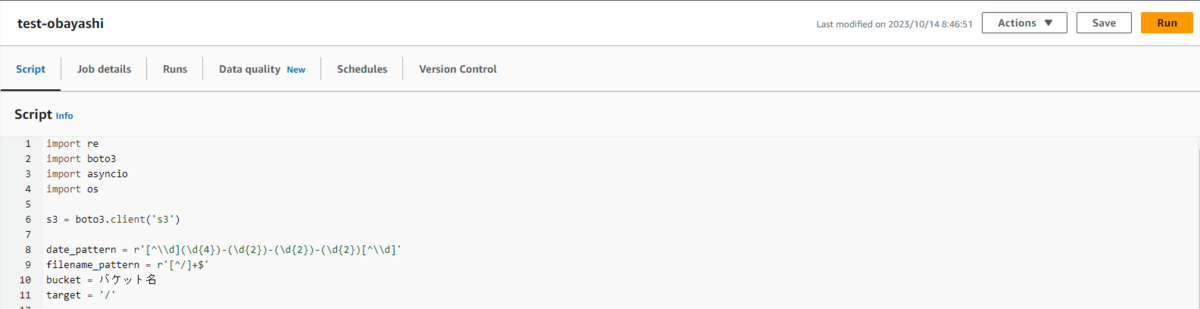
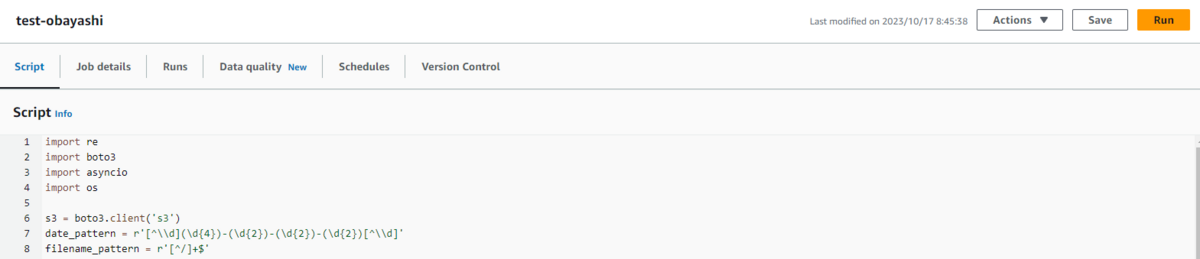
使用するスクリプトは以下です。
import re
import boto3
import asyncio
import os
s3 = boto3.client('s3')
date_pattern = r'[^\\d](\d{4})-(\d{2})-(\d{2})-(\d{2})[^\\d]'
filename_pattern = r'[^/]+$'
bucket = ログファイルが格納されているS3バケット
target = '/'
client = boto3.client('s3')
obj = client.list_objects(Bucket=bucket)
obj_list = obj['ResponseMetadata']
data = obj['Contents']
keys = [item['Key'] for item in data if not item['Key'].endswith('/')]
for source_key in keys:
target_find = source_key.find(target)
target_key_prefix = source_key[:target_find]
source_regex = re.compile(date_pattern)
match = source_regex.search(source_key)
if match is None:
print('ファイルが見つかりませんでした。')
else:
year, month, day, hour = match.groups()
filename_regex = re.compile(filename_pattern)
filename = filename_regex.search(source_key).group(0)
target_key = target_key_prefix + '/' + year + '/' + month + '/' + day + '/' + filename
print(str(source_key) + ' to ' + str(target_key))
copy_result =s3.copy_object(Bucket=bucket, Key=target_key,
CopySource={'Bucket': bucket, 'Key': source_key})
print(copy_result)
delete_result = s3.delete_object(Bucket=bucket, Key=source_key)
print(delete_result)
③Amazon Athenaでアクセスログをクエリする
分析用のテンプレートは以下です。
AWSTemplateFormatVersion: "2010-09-09"
#----------------------------------------------------------------------#
# Athenaを利用したCloudFrontのアクセスログ分析用テンプレート
# 作成されるリソース:Glue:Database, Glue:Table, S3bucket, Athenaワークグループ
#----------------------------------------------------------------------#
Parameters:
#アカウントIDを入力
AccountId:
Description: "input Account Id "
Type: String
#環境名を入力
Env:
Description: dev or prod
Type: String
#システム名を入力
SystemName:
Description: System name
Type: String
#CloudFrontのアクセスログが保存されているS3バケットを指定する
S3bucketCloudFrontLogs:
Type: String
#オブジェクトの有効期限を入力
ExpirationInDays:
Type: String
Default: 1825
#Glueテーブルのパーティションに設定するCloudFrontディストリビューションを入力
distributions:
Description: "enter distribution name by Comma Delimiter list (XXXXXXXXXXXX,XXXXXXXXXXXX...)"
Type: String
Resources:
#------------------------------------------------------------#
# Glue
# アクセスログ用のデータベースとテーブルを作成する
#------------------------------------------------------------#
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Sub '${Env}_${SystemName}_cloudfront_database'
#CloudFrontアクセスログのGlueテーブル
GlueTableCloudFrontLogs:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref GlueDatabase
TableInput:
Name: !Sub '${Env}_${SystemName}_cloudfront_table'
TableType: EXTERNAL_TABLE
Parameters:
EXTERNAL: true
projection.enabled: true
projection.distribution.type: enum
projection.distribution.values: !Sub '${distributions}'
projection.datetime.type: date
projection.datetime.format: yyyy/MM/dd
projection.datetime.range: 2023/01/01,NOW
storage.location.template: !Sub 's3://${S3bucketCloudFrontLogs}/${!distribution}/${!datetime}'
skip.header.line.count: '2'
serialization.encoding: utf-8
PartitionKeys:
- Name: distribution
Type: string
- Name: datetime
Type: string
StorageDescriptor:
Columns:
- Name: date
Type: date
- Name: time
Type: string
- Name: location
Type: string
- Name: bytes
Type: bigint
- Name: requestip
Type: string
- Name: method
Type: string
- Name: host
Type: string
- Name: uri
Type: string
- Name: status
Type: int
- Name: referrer
Type: string
- Name: useragent
Type: string
- Name: querystring
Type: string
- Name: cookie
Type: string
- Name: resulttype
Type: string
- Name: requestid
Type: string
- Name: hostheader
Type: string
- Name: requestprotocol
Type: string
- Name: requestbytes
Type: bigint
- Name: timetaken
Type: float
- Name: xforwardedfor
Type: string
- Name: sslprotocol
Type: string
- Name: sslcipher
Type: string
- Name: responseresulttype
Type: string
- Name: httpversion
Type: string
- Name: filestatus
Type: string
- Name: encryptedfields
Type: int
- Name: cPort
Type: string
- Name: timeToFirstByte
Type: string
- Name: xEdgeDetailedResultType
Type: string
- Name: scContentType
Type: string
- Name: scContentLen
Type: string
- Name: scRangeStart
Type: string
- Name: scRangeEnd
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Location: !Sub 's3://${S3bucketCloudFrontLogs}/'
SerdeInfo:
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Parameters:
serialization.format: "\t"
#------------------------------------------------------------#
# Athena
#------------------------------------------------------------#
AthenaWorkGroup:
Type: AWS::Athena::WorkGroup
Properties:
Name: !Sub "${Env}-athena-work-group"
WorkGroupConfiguration:
ResultConfiguration:
OutputLocation: !Sub "s3://${AthenaQueryResultBucket}/data"
EnforceWorkGroupConfiguration: true
PublishCloudWatchMetricsEnabled: true
#------------------------------------------------------------#
# S3 Backet
# Athenaでクエリを実行した結果が格納されるS3バケットを作成する
#------------------------------------------------------------#
AthenaQueryResultBucket:
Type: AWS::S3::Bucket
DeletionPolicy: 'Retain'
Properties:
BucketName: !Sub '${Env}-${SystemName}-cloudfront-athena-result'
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
LifecycleConfiguration:
Rules:
- Id: life-cycle-rule
Status: Enabled
ExpirationInDays: !Sub '${ExpirationInDays}'
BucketEncryption:
ServerSideEncryptionConfiguration:
-
ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
ケース1のデモ
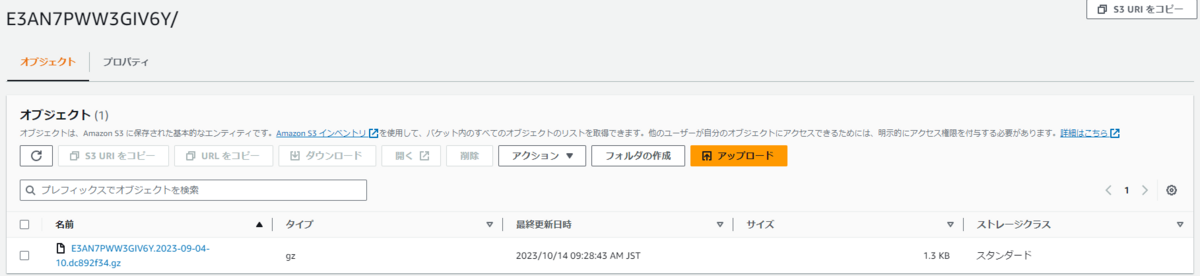
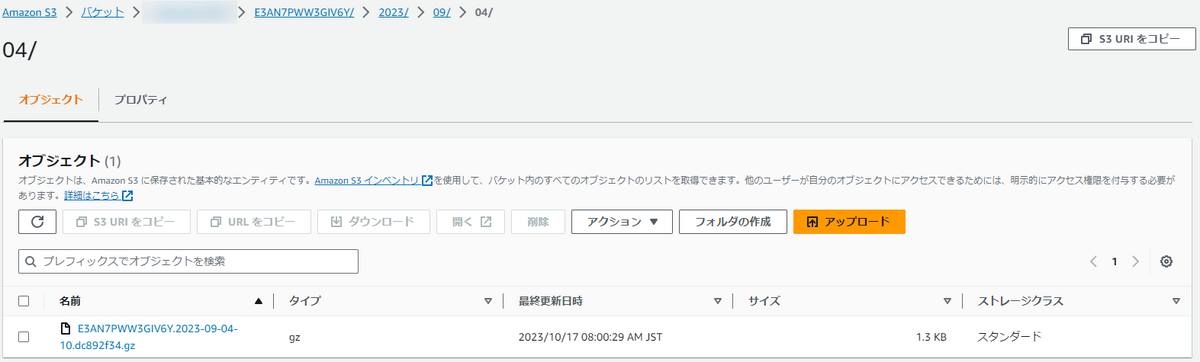
添付画像の通り、すでに指定したプレフィックス名のフォルダ配下にログがS3バケットにアップロードされています。
上記のスクリプトの9行目で処理対象のS3バケットを指定して、ジョブを実行します。
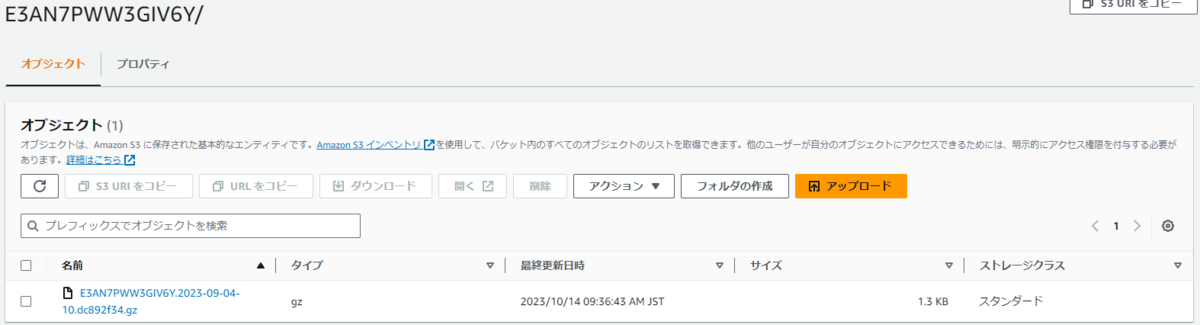 実行結果は以下の添付画像の通りです。
実行結果は以下の添付画像の通りです。
意図した通り、「バケット名/ディストリビューション名/yyyy/mm/dd」というパスにログファイルが保存されています。
ケース2
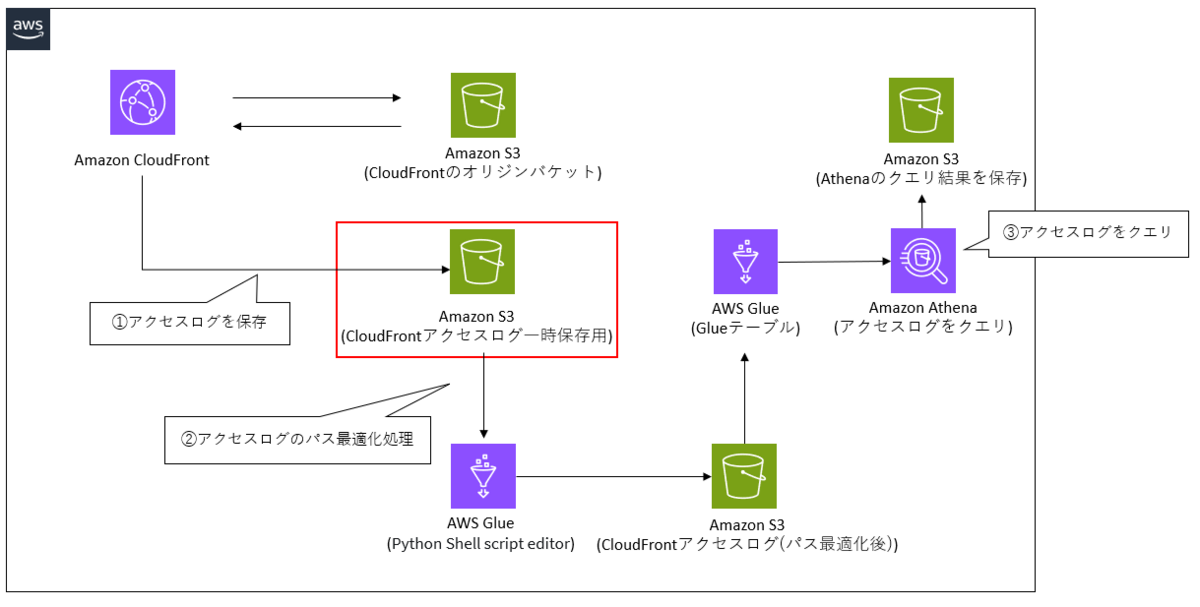
ケース2の設計と処理の流れ
ケース2では、パス最適化処理中にエラーが発生した場合でもログファイルが消失してしまうリスクを抑えた構成になっています。
一方で、S3バケットを2つ使用するためその分コストがかかってしまいます。
そのため、ライフサイクルポリシーを使用するなどコストを抑える対策を取る必要があります。
①Amazon CloudFrontのアクセスログがS3バケットに保存されている
②Glueを使用して、アクセスログ保存のパスを最適化する
・ログファイルをパス(ディストリビューション名/yyyy/mm/dd)を指定してコピーします。
・上記の処理が終了した時点で、パス最適化前と最適化後のログファイルが存在することになるのでパスが最適化できていないほうを削除します。
 パス(ディストリビューション名/yyyy/mm/dd)を指定してログファイルを別のS3バケットにコピーします。
パス(ディストリビューション名/yyyy/mm/dd)を指定してログファイルを別のS3バケットにコピーします。
使用するスクリプトは以下です。
import re
import boto3
import asyncio
import os
s3 = boto3.client('s3')
date_pattern = r'[^\\d](\d{4})-(\d{2})-(\d{2})-(\d{2})[^\\d]'
filename_pattern = r'[^/]+$'
bucket = ログファイルが格納されているS3バケット
destination_bucket = ログファイルのコピー先S3バケット
target = '/'
client = boto3.client('s3')
obj = client.list_objects(Bucket='y-obayashi-0910')
obj_list = obj['ResponseMetadata']
data = obj['Contents']
keys = [item['Key'] for item in data if not item['Key'].endswith('/')]
for source_key in keys:
target_find = source_key.find(target)
target_key_prefix = source_key[:target_find]
source_regex = re.compile(date_pattern)
match = source_regex.search(source_key)
if match is None:
print('ファイルが見つかりませんでした。')
else:
year, month, day, hour = match.groups()
filename_regex = re.compile(filename_pattern)
filename = filename_regex.search(source_key).group(0)
target_key = target_key_prefix + '/' + year + '/' + month + '/' + day + '/' + filename
print(str(source_key) + ' to ' + str(target_key))
copy_result =s3.copy_object(Bucket=destination_bucket, Key=target_key,
CopySource={'Bucket': bucket, 'Key': source_key})
print(copy_result)
③Amazon Athenaでアクセスログをクエリする
分析用のテンプレートはケース1と同様のものを使用します。
ケース2のデモ
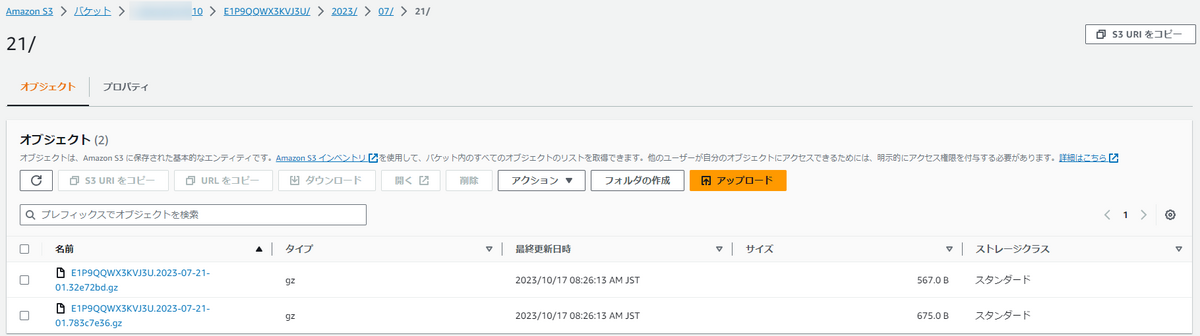
添付画像の通り、すでに指定したプレフィックス名のフォルダ配下にログがS3バケットにアップロードされています。
上記のスクリプトの9行目でログファイルが格納されているS3バケット、10行目でログファイルのコピー先S3バケット指定して、ジョブを実行します。
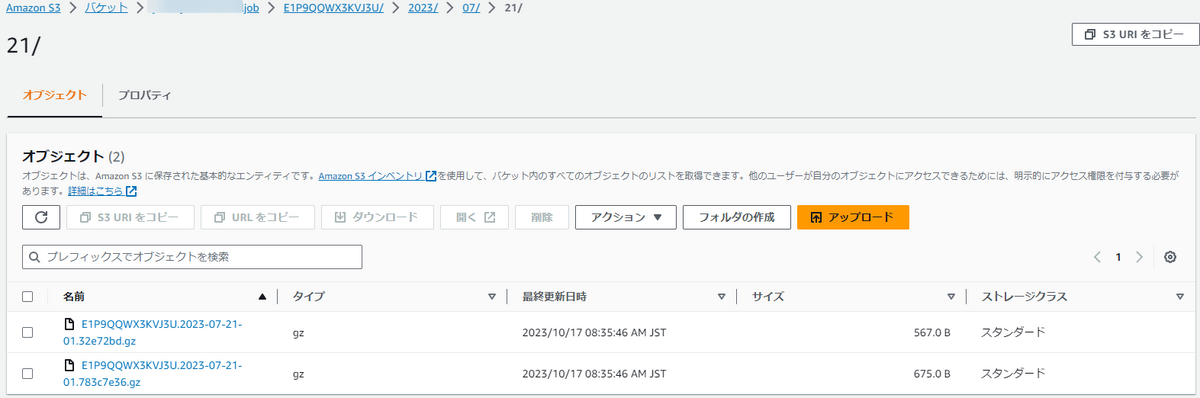
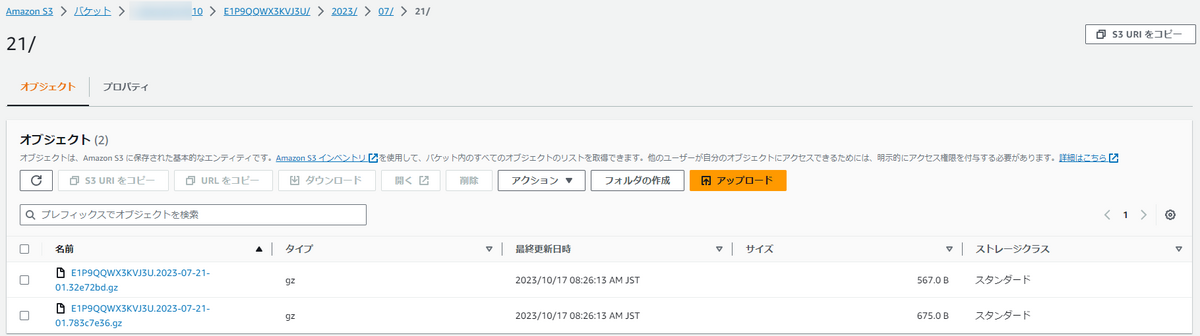 実行結果は以下の添付画像の通りです。
実行結果は以下の添付画像の通りです。
意図した通り、別のS3バケットに「バケット名/ディストリビューション名/yyyy/mm/dd」というパスにログファイルが保存されています。
さいごに
今回は、既にS3バケットにアップロードされているログファイルに対してパス最適化処理を行う方法を紹介しました。
本ブログでは「ディストリビューション名/yyyy/mm/dd」といったパスでログファイルを保存するようにしましたが、どういったパスにログファイルを保存するかはケースによって異なってくると思うので状況を見て判断する必要があると考えています。
この検証を通して、細かくパーティションを切っていけばいいという単純なものではないことを学びました。
パーティション設定…奥が深いです…。
