小西秀和です。
以前の記事では、Anthropic Claude 3.5 Sonnetの画像理解・分析機能を活用して、Stability AI Stable Diffusion XL(SDXL)で生成した画像を検証・再生成するAmazon Bedrockの使用例を紹介しました。
本記事では、Anthropic Claude 3.5 Sonnetの画像理解・分析機能を活用して、Amazon Titan Image Generator G1で生成した画像を検証・再生成するAmazon Bedrockの使用例をご紹介します。
この試みは、前述の記事同様に生成画像の要件充足を自動的に判定することで、人間による目視確認の作業量削減も目指しています。
※本記事および当執筆者のその他の記事で掲載されているソースコードは自主研究活動の一貫として作成したものであり、動作を保証するものではありません。使用する場合は自己責任でお願い致します。また、予告なく修正することもありますのでご了承ください。
※本記事執筆にあたっては個人でユーザー登録したAWSアカウント上でAWSサービスを使用しています。
※本記事執筆にあたって使用したAmazon Bedrockの各Modelは2024-07-23(JST)に実行し、その時点における次のEnd user license agreement (EULA)に基づいています。
Anthropic Claude 3.5 Sonnet(anthropic.claude-3-5-sonnet-20240620-v1:0): Anthropic on Bedrock - Commercial Terms
of Service(Effective: January 2, 2024)
Amazon Titan Image Generator G1(amazon.titan-image-generator-v1): End user license agreement (EULA) (AWS Customer Agreement and Service Terms)
構成図と処理フロー
今回のテーマを実現する構成図は次のようになります。
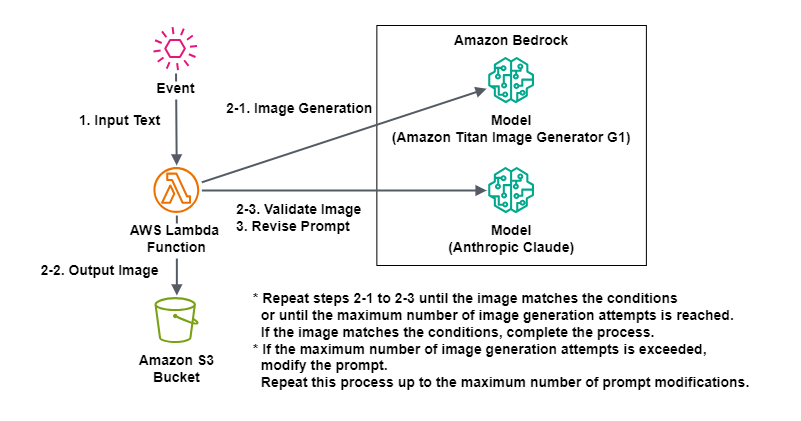
この処理フローについて詳細を説明します。
1. プロンプトやパラメータを含むイベントを入力します。
2-1. 入力した画像作成を指示するプロンプトでAmazon BedrockでTitan Image Generator G1モデルを実行します。
2-2. 生成された画像をAmazon S3に保存します。
2-3. Amazon S3に保存された画像に対してAmazon BedrockでClaude 3.5 Sonnetモデルを実行し、画像作成を指示したプロンプトの要件にふさわしいかを検証します。
* 画像作成を指示したプロンプトの要件にふさわしいと判断されなければ、2-1.から2-3.の処理を指定した同一プロンプト実行回数だけ繰り返します。
* 画像作成を指示したプロンプトの要件にふさわしいと判断されれば、その画像を出力結果とします。
3. 修正プロンプト実行回数を超えておらず、画像作成を指示したプロンプトの要件にふさわしいと判断されない回数が同一プロンプト実行回数を超えた場合、Amazon BedrockでClaude 3.5 Sonnetモデルを実行し、画像作成を指示するプロンプトを要件が満たされる可能性が高いものに修正します。この新しい画像作成を指示するプロンプトで2-1.から処理をやり直します。
* 修正プロンプト実行回数を超えた場合、エラーとして処理を終了します。
この処理フローでポイントとなるのはClaude 3.5 Sonnetモデルによる画像作成を指示するプロンプトの修正です。
画像作成を指示するプロンプトがAIにとって理解しやすいものであれば、要件を満たす画像は何回か実行すれば出力される可能性が高いでしょう。
ただ、画像作成を指示するプロンプトがAIにとって理解しにくいものであれば、要件を満たす画像の出力がされない事も考えられます。
そのため、指定した同一プロンプト実行回数を超えた場合には、Amazon BedrockでClaude 3.5 Sonnetモデルを実行し、画像作成を指示するプロンプトを最適化したものに修正する処理を入れました。
実装例
入力するイベントのフォーマット
{ "prompt": "[画像生成のための初期プロンプト]", "max_retry_attempts": [各プロンプトで画像生成を試行する最大回数], "max_prompt_revisions": [プロンプトを修正する最大回数], "output_s3_bucket_name": "[生成された画像を保存するS3バケットの名前]", "output_s3_key_prefix": "[生成された画像のS3キーのプレフィックス]", "claude_validate_temperature": [画像検証時のClaudeモデルのtemperatureパラメータ(0.0〜1.0)], "claude_validate_top_p": [画像検証時のClaudeモデルのtop-pパラメータ(0.0〜1.0)], "claude_validate_top_k": [画像検証時のClaudeモデルのtop-kパラメータ], "claude_validate_max_tokens": [画像検証時のClaudeモデルが生成する最大トークン数], "claude_revise_temperature": [プロンプト修正時のClaudeモデルのtemperatureパラメータ(0.0〜1.0)], "claude_revise_top_p": [プロンプト修正時のClaudeモデルのtop-pパラメータ(0.0〜1.0)], "claude_revise_top_k": [プロンプト修正時のClaudeモデルのtop-kパラメータ], "claude_revise_max_tokens": [プロンプト修正時のClaudeモデルが生成する最大トークン数], "titan_img_cfg_scale": [Titan Image Generator G1モデルのCFGスケール], "titan_img_width": [Titan Image Generator G1モデルで生成する画像の幅(ピクセル単位)], "titan_img_height": [Titan Image Generator G1モデルで生成する画像の高さ(ピクセル単位)], "titan_img_number_of_images": [Titan Image Generator G1モデルで生成する画像の数], "titan_img_seed": [Titan Image Generator G1モデルで使用する乱数シード値(再現性のために使用、指定しない場合はランダム)] }
入力するイベントの例
{ "prompt": "A serene landscape with mountains and a lake", "max_retry_attempts": 5, "max_prompt_revisions": 3, "output_s3_bucket_name": "your-output-bucket-name", "output_s3_key_prefix": "generated-images-taitan", "claude_validate_temperature": 1.0, "claude_validate_top_p": 0.999, "claude_validate_top_k": 250, "claude_validate_max_tokens": 4096, "claude_revise_temperature": 1.0, "claude_revise_top_p": 0.999, "claude_revise_top_k": 250, "claude_revise_max_tokens": 4096, "titan_img_cfg_scale": 10.0, "titan_img_width": 1024, "titan_img_height": 1024, "titan_img_number_of_images": 1, "titan_img_seed": 0 }
ソースコード
今回、実装したソースコードは次のようになります。
# #Event Sample # { # "prompt": "A serene landscape with mountains and a lake", # "max_retry_attempts": 5, # "max_prompt_revisions": 3, # "output_s3_bucket_name": "your-output-bucket-name", # "output_s3_key_prefix": "generated-images-taitan", # "claude_validate_temperature": 1.0, # "claude_validate_top_p": 0.999, # "claude_validate_top_k": 250, # "claude_validate_max_tokens": 4096, # "claude_revise_temperature": 1.0, # "claude_revise_top_p": 0.999, # "claude_revise_top_k": 250, # "claude_revise_max_tokens": 4096, # "titan_img_cfg_scale": 10.0, # "titan_img_width": 1024, # "titan_img_height": 1024, # "titan_img_number_of_images": 1, # "titan_img_seed": 0 # } import boto3 import json import base64 import os import sys from io import BytesIO import datetime import random region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) s3_client = boto3.client('s3', region_name=region) def claude3_5_invoke_model(input_prompt, image_media_type=None, image_data_base64=None, model_params={}): messages = [ { "role": "user", "content": [ { "type": "text", "text": input_prompt } ] } ] if image_media_type and image_data_base64: messages[0]["content"].insert(0, { "type": "image", "source": { "type": "base64", "media_type": image_media_type, "data": image_data_base64 } }) body = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": model_params.get('max_tokens', 4096), "messages": messages, "temperature": model_params.get('temperature', 1.0), "top_p": model_params.get('top_p', 0.999), "top_k": model_params.get('top_k', 250), "stop_sequences": ["\n\nHuman:"] } response = bedrock_runtime_client.invoke_model( modelId='anthropic.claude-3-5-sonnet-20240620-v1:0', contentType='application/json', accept='application/json', body=json.dumps(body) ) response_body = json.loads(response.get('body').read()) response_text = response_body["content"][0]["text"] return response_text def titan_img_invoke_model(prompt, model_params={}): seed = model_params.get('seed', 0) if seed == 0: seed = random.randint(0, 2147483646) optimized_prompt = truncate_to_512(prompt) body = { "taskType": "TEXT_IMAGE", "textToImageParams": { "text": optimized_prompt }, "imageGenerationConfig": { "numberOfImages": model_params.get('img_number_of_images', 1), "height": model_params.get('height', 1024), "width": model_params.get('width', 1024), "cfgScale": model_params.get('cfg_scale', 8), "seed": seed } } print(f"Titan Image Generator G1 model parameters: {body}") response = bedrock_runtime_client.invoke_model( body=json.dumps(body), modelId="amazon.titan-image-generator-v1", contentType="application/json", accept="application/json" ) response_body = json.loads(response['body'].read()) image_data = base64.b64decode(response_body.get("images")[0].encode('ascii')) finish_reason = response_body.get("error") if finish_reason is not None: print(f"Image generation error. Error is {finish_reason}") else: print(f"Image generated successfully with seed: {seed}") return image_data def truncate_to_512(text): if len(text) <= 512: return text truncated = text[:512] last_period = truncated.rfind('.') last_comma = truncated.rfind(',') last_break = max(last_period, last_comma) if last_break > 256: # Only if the last sentence or phrase is not too long return truncated[:last_break + 1] else: return truncated def save_image_to_s3(image_data, bucket, key): s3_client.put_object( Bucket=bucket, Key=key, Body=image_data ) print(f"Image saved to S3: s3://{bucket}/{key}") def validate_image(image_data, prompt, claude_validate_params): image_base64 = base64.b64encode(image_data).decode('utf-8') input_prompt = f"""Does this image match the following prompt? Prompt: {prompt}. Please answer in the following JSON format: {{"result":"<YES or NO>", "reason":"<Reason for your decision>"}} Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure.""" validation_result = claude3_5_invoke_model(input_prompt, "image/png", image_base64, claude_validate_params) try: print(f"validation Result: {validation_result}") parsed_result = json.loads(validation_result) is_valid = parsed_result['result'].upper() == 'YES' print(f"Image validation result: {is_valid}") print(f"Validation reason: {parsed_result['reason']}") return is_valid except json.JSONDecodeError: print(f"Error parsing validation result: {validation_result}") return False def revise_prompt(original_prompt, claude_revise_params): input_prompt = f"""Revise the following image generation prompt to optimize it for Titan Image Generator G1, incorporating best practices: {original_prompt} Please consider the following guidelines in your revision: 1. Start the prompt with "An image of..." and be specific and descriptive, using vivid adjectives and clear nouns. 2. Include detailed descriptions about composition, lighting, style, mood, color, and medium if relevant. 3. Mention specific artists or art styles if relevant, though this is not emphasized in Titan's guidelines. 4. Use descriptive keywords like "highly detailed" if appropriate. While "4k", "8k", or "photorealistic" can be used, they are not specifically emphasized for Titan. 5. Separate different concepts with commas, using them to structure the prompt logically. 6. Place more important elements, especially the main subject, at the beginning of the prompt. 7. Consider using negative prompts to specify what should NOT be included in the image. 8. If the original prompt is not in English, translate it to English. 9. Use double quotes instead of single quotes for any quoted text within the prompt. 10. Provide context or background details to help improve the realism and coherence of the generated image. 11. Ensure the final prompt is no longer than 500 characters. Prioritize the most important elements if you need to shorten the prompt. Your goal is to create a clear, detailed prompt that will result in a high-quality image generation with Titan Image Generator G1, while staying within the 500-character limit. Please provide your response in the following JSON format: {{"revised_prompt":"<Revised Prompt>"}} Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure.""" revised_prompt_json = claude3_5_invoke_model(input_prompt, model_params=claude_revise_params) print(f"Original prompt: {original_prompt}") print(f"Revised prompt JSON: {revised_prompt_json.strip()}") try: parsed_result = json.loads(revised_prompt_json) revised_prompt = parsed_result['revised_prompt'] print(f"Parsed revised prompt: {revised_prompt}") return revised_prompt except json.JSONDecodeError: print(f"Error parsing revised prompt result: {revised_prompt_json}") return original_prompt def lambda_handler(event, context): try: initial_prompt = event['prompt'] prompt = initial_prompt max_retry_attempts = max(0, event.get('max_retry_attempts', 5) - 1) max_prompt_revisions = max(0, event.get('max_prompt_revisions', 3) - 1) output_s3_bucket_name = event['output_s3_bucket_name'] output_s3_key_prefix = event.get('output_s3_key_prefix', 'generated-images') print(f"Initial prompt: {initial_prompt}") print(f"Max retry attempts: {max_retry_attempts}") print(f"Max prompt revisions: {max_prompt_revisions}") # Model parameters claude_validate_params = { 'temperature': event.get('claude_validate_temperature', 1.0), 'top_p': event.get('claude_validate_top_p', 0.999), 'top_k': event.get('claude_validate_top_k', 250), 'max_tokens': event.get('claude_validate_max_tokens', 4096) } claude_revise_params = { 'temperature': event.get('claude_revise_temperature', 1.0), 'top_p': event.get('claude_revise_top_p', 0.999), 'top_k': event.get('claude_revise_top_k', 250), 'max_tokens': event.get('claude_revise_max_tokens', 4096) } titan_img_params = { 'cfg_scale': event.get('titan_img_cfg_scale', 8), "width": event.get('titan_img_width', 1024), "height": event.get('titan_img_height', 1024), 'img_number_of_images': event.get('titan_img_number_of_images', 1), "seed": event.get('titan_img_seed', 0) } print(f"Claude validate params: {claude_validate_params}") print(f"Claude revise params: {claude_revise_params}") print(f"Titan Image Generator G1 params: {titan_img_params}") # Generate start timestamp and S3 key start_timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S") for revision in range(max_prompt_revisions + 1): print(f"Starting revision {revision}") for attempt in range(max_retry_attempts + 1): print(f"Attempt {attempt} for generating image") # Generate image with Titan Image Generator G1 image_data = titan_img_invoke_model(prompt, titan_img_params) image_key = f"{output_s3_key_prefix}-{start_timestamp}-{revision:03d}-{attempt:03d}.png" # Save image to S3 save_image_to_s3(image_data, output_s3_bucket_name, image_key) # Validate image with Claude is_valid = validate_image(image_data, initial_prompt, claude_validate_params) if is_valid: print("Valid image generated successfully") return { 'statusCode': 200, 'body': json.dumps({ 'status': 'SUCCESS', 'message': 'Image generated successfully', 'output_s3_bucket_url': f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}', 'output_s3_object_url': f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&prefix={image_key}' }) } # If max retry attempts reached and not the last revision, revise prompt if revision < max_prompt_revisions: print("Revising prompt") prompt = revise_prompt(initial_prompt, claude_revise_params) print("Failed to generate a valid image after all attempts and revisions") return { 'statusCode': 400, 'body': json.dumps({ 'status': 'FAIL', 'error': 'Failed to generate a valid image after all attempts and revisions' }) } except Exception as ex: print(f'Exception: {ex}') tb = sys.exc_info()[2] err_message = f'Exception: {str(ex.with_traceback(tb))}' print(err_message) return { 'statusCode': 500, 'body': json.dumps({ 'status': 'FAIL', 'error': err_message }) }
このソースコードで工夫した点には以下のものが挙げられます。
- 画像生成と検証のサイクルを自動化し、要件を満たすまで繰り返す仕組みを実装しました。
- Claude 3.5 Sonnetを使用して生成された画像の検証と、プロンプトの修正を行いました。
- Titan Image Generator G1を使用して高品質な画像生成を行いました。
- プロンプトの修正指示には、Amazon Titan Image Generator Prompt Engineering Best Practicesに記載されている推奨事項を取り入れました。
- 画像生成パラメータ(cfg_scale, steps, width, height, seed)をカスタマイズ可能にしました。
- Claude 3.5 Sonnetの呼び出しパラメータ(temperature, top_p, top_k, max_tokens)も調整可能にしました。
- 生成された画像を自動的にS3バケットに保存し、結果のURLを返しました。
- エラーハンドリングとログ出力を適切に実装し、トラブルシューティングを容易にしました。
- JSONフォーマットを使用して、Claudeとの対話を構造化し、結果の解析を容易にしました。
- 最大リトライ回数と最大プロンプト修正回数を設定可能にし、無限ループを防ぎました。
実行内容と結果
実行の一例:入力パラメータ
{ "prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。", "max_retry_attempts": 5, "max_prompt_revisions": 5, "output_s3_bucket_name": "ho2k.com", "output_s3_key_prefix": "generated-images-taitan", "claude_validate_temperature": 1.0, "claude_validate_top_p": 0.999, "claude_validate_top_k": 250, "claude_validate_max_tokens": 4096, "claude_revise_temperature": 1.0, "claude_revise_top_p": 0.999, "claude_revise_top_k": 250, "claude_revise_max_tokens": 4096, "titan_img_cfg_scale": 10.0, "titan_img_width": 1024, "titan_img_height": 1024, "titan_img_number_of_images": 1, "titan_img_seed": 0 }
今回の実行例の入力パラメータには以下の工夫をしています。
max_retry_attemptsを5に設定して、画像生成の成功率を高めました。max_prompt_revisionsが5に設定されており、必要に応じてプロンプトを改善する機会を増やしました。- 画像検証と修正のためのClaudeモデルのパラメータ(temperature, top_p, top_k, max_tokens)を細かく設定しました。
titan_img_cfg_scaleを10に設定し、プロンプトへの忠実度を高めました。- 画像生成に使用する
seedがランダムに設定されるようにし、毎回異なる画像が生成されるようにしました。
実行の一例:結果
生成された画像
今回の試行において最終的にプロンプトの要件を満たして検証をパスした画像は以下です。
この画像は実際に「自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。」という要件をほぼすべて満たしています(地平線の太陽という構図の具現化は弱いですが、月と地平線の太陽という矛盾した情景や流星群と流氷はしっかりと表現されています)。
また、最終的に検証をパスした画像は、最終的に検証をパスするよりも前に生成された他の画像(後述の「生成された画像一覧」参照)と比較しても、指示された要件をより多く満たしていることも確認できました。

今回、試した実行で生成された画像の一覧は以下です。
この「生成された画像一覧」の各行の画像は、それぞれ修正された異なるプロンプトから生成されたものです。
最初に入力された日本語の文章によるプロンプトでは、要件とかけ離れた画像が出力されているのに対し、1回目のプロンプトの修正直後に要件を満たした画像が出力されています。

修正されたプロンプトの変化
上記で掲載した「生成された画像一覧」の各行の画像は、それぞれ修正された異なるプロンプトから生成されています。
具体的には、「生成された画像一覧」の最初の行の画像は、以下の「修正0回目」のプロンプトから生成されたものであり、「生成された画像一覧」の最後の行の画像は、以下の「修正1回目」のプロンプトから生成されたものです。
プロンプトの修正回数ごとに、修正された画像生成プロンプトの内容を見てみましょう。
修正0回目
自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。
修正1回目
An image of a breathtaking nighttime landscape viewed from nature, featuring a vibrant aurora borealis dancing across the sky, accompanied by a luminous full moon and a dazzling meteor shower. In the foreground, a vast, dark sea stretches to the horizon, dotted with floating ice floes. The sun is just beginning to rise at the horizon, casting a warm glow on the icy waters. The scene is devoid of human presence, highly detailed, with a serene and mystical atmosphere.
特に上記で掲載した「生成された画像一覧」と関連付けて見ると、最初に入力された日本語の文章によるプロンプトは画像生成に最適化されていないため、要件とかけ離れた画像が出力されていることがわかります。
一方で、修正1回目にClaude 3.5 Sonnetによって画像生成に最適化されたプロンプトに修正され、その直後の実行によって要件にほぼ一致した画像が出力されています。
このように、プロンプトの修正ごと、生成の実行ごとに画像が変化し、プロンプトの要件を満たす画像が最終的に検証をパスします。
<参考資料>
AWS Documentation(Amazon Bedrock)
Amazon Titan Image Generator Prompt Engineering Best Practices
Tech Blog with related articles referenced
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Haiku
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Sonnet
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Opus
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3.5 Sonnet
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Amazon Nova Pro
Using Amazon Textract for OCR(Optical Character Recognition)
Evaluating OCR Accuracy of Claude on Amazon Bedrock and Amazon Textract Using Similarity Metrics
Using Amazon Nova Pro Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Amazon Nova Canvas
Amazon Bedrock AgentCore Beginner's Guide - AI Agent Development from Basics with Detailed Term Explanations
まとめ
今回は、Anthropic Claude 3.5 Sonnetの画像理解・分析機能を活用して、Amazon Titan Image Generator G1で生成した画像を検証・再生成するAmazon Bedrockの使用例を紹介しました。
この試みを通して、Claude 3.5 Sonnetの画像認識機能が、OCRだけでなく画像の内容や表現も認識し、要件充足の検証に活用できることが確認できました。
さらに、Claude 3.5 SonnetをTitan Image Generator G1用のプロンプト最適化にも利用できること、特に日本語のプロンプトを英語に翻訳し、画像生成に適した形式に修正する能力が高いことも分かりました。
そして何よりも、画像生成と検証のサイクルを自動化することで、人間による目視確認の作業量を大幅に削減できました。
ただ注意するべき点としては、以前のStable Diffusion XLを使用した例や今回のAmazon Titan Image Generator G1を使用した例と同様に、プロンプト修正の指示を各画像生成AIのベストプラクティスに合わせて工夫することが挙げられます。これによって、効果的なプロンプト最適化と画像生成の自動化が他の様々な画像生成AIにも応用できると考えられます。
このように、Claude 3.5 Sonnetは画像生成AI(Titan Image Generator G1やStable Diffusion XLなど)の制御や、これまで自動化が難しかった処理に新たな可能性をもたらします。
今後もAmazon Bedrockが提供するAIモデルの進化と、それらを活用した新しい実装方法に注目し、さらなる応用範囲の拡大を探っていきたいと思います。
- [English Edition] Using Claude 3.5 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Amazon Titan Image Generator G1

