こんにちは、上野です。
Amazon SageMaker Studio Labがre:Invent 2021で発表されましたね!
学習に良さそうなサービスなので実際に触ってみました。
Amazon SageMaker Studio Labとは
JupyterLabと呼ばれる機械学習の環境を、無料で利用できるサービスです。もう一度、無料です!!
以下のような特徴があります。
- AWSアカウントとは別で管理されており、クレジットカード情報も不要
- GPUも使用可能
- 15 GBのストレージ付き
機械学習を勉強するにしても、環境設定やコストが懸念だよね。と動画で紹介されていました。
そんな懸念点を解決してくれるサービスです!AWSアカウントとまったく関係ないところで動くので、普通のAWSサービスとはちょっと違った感覚ですね。
申し込んでみる
コチラから申込可能です!

Request Accountを押して、メールアドレスや氏名等の情報をしてリクエストを送信します。
メールを受信するので、忘れずにVerify your emailをクリックしておきます。クリックすると以下のように表示されます。
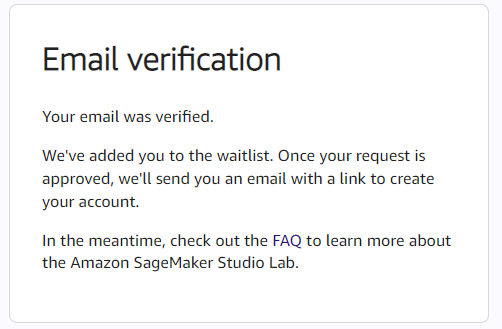
後はAWS側の承認待ちです。
承認、アカウント作成
2営業日後に、承認メールが来ました。7日間で承認リンクが切れるので、忘れずにクリックしてアカウントを作成しましょう。
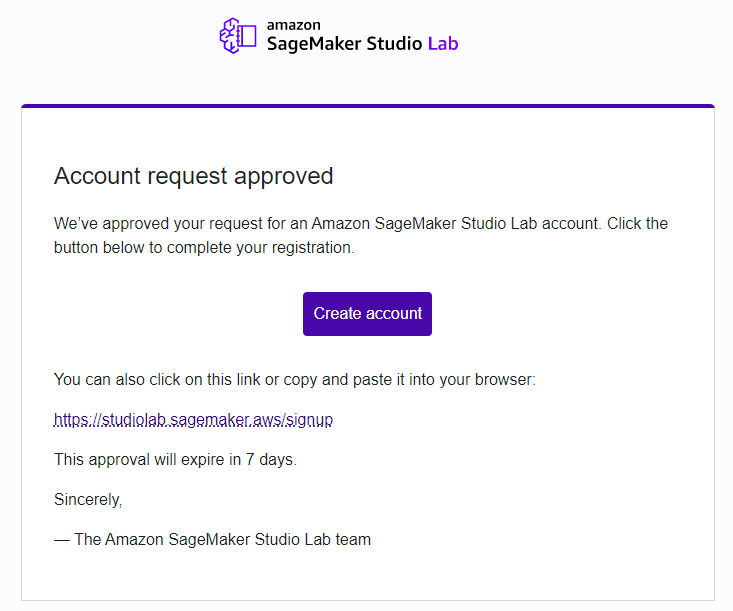
必要情報を入力し、Create Accountします。
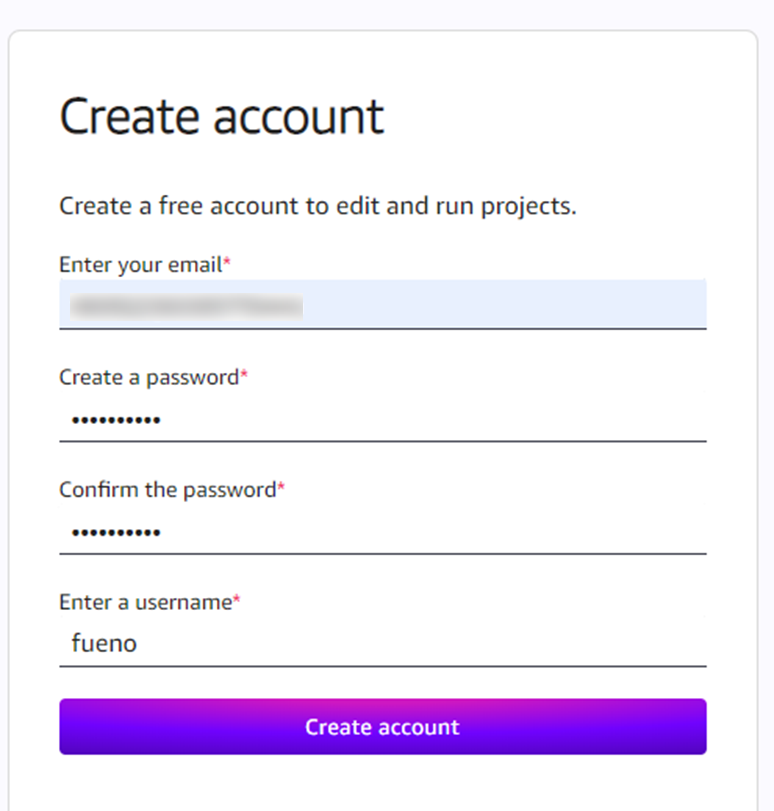
もう一度確認メールが飛ぶので、メールのリンクをクリックします。(申込から3回ほどメール確認している気がします・・)
やっとSign inです。
入れた!画面下部には、お勉強用の参考ページなどの情報が表示されています。
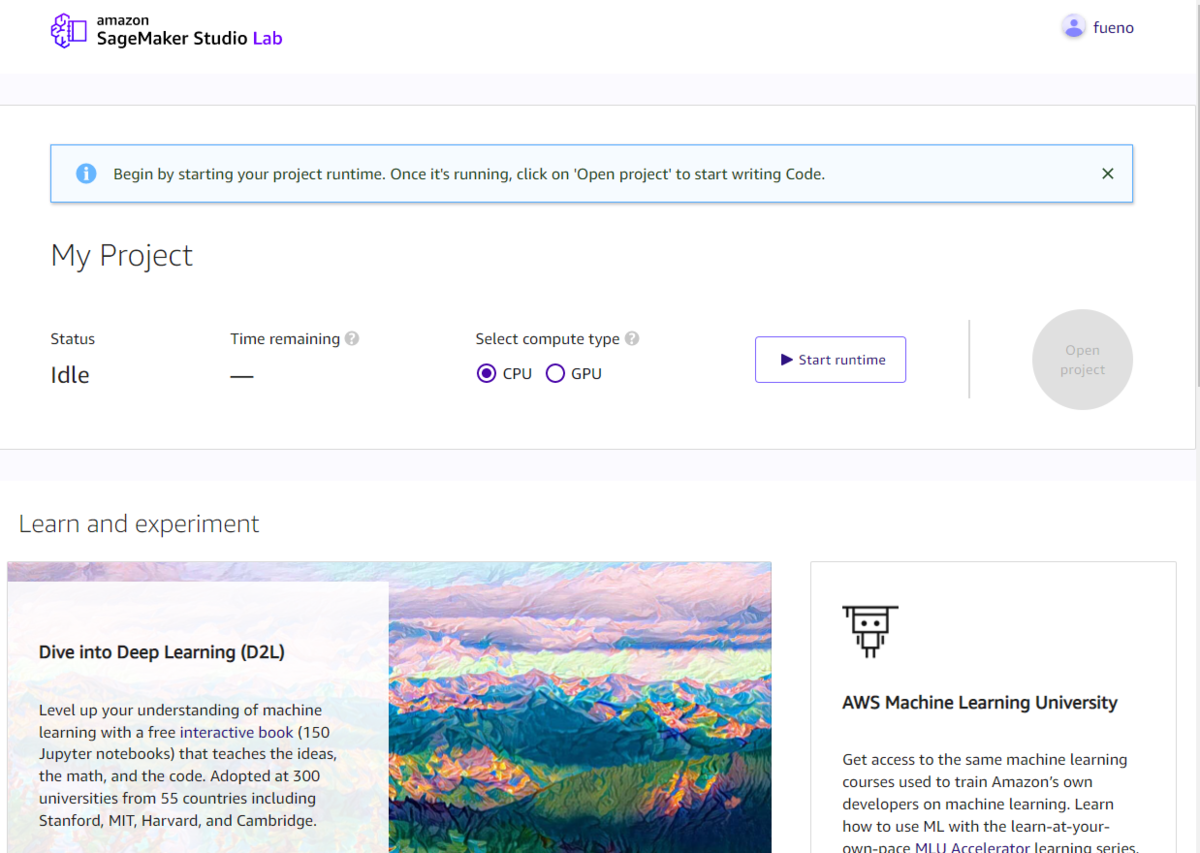
プロジェクトの開始
プロジェクトをStartしてみます。CPUまたはGPUを選べます。CPUは12時間で自動停止、GPUは4時間で自動停止という仕様になっています。
なお、停止後で手動再起動、再利用は可能で、データも残ります。月あたりの利用時間といった制約は無いようです。ただし、毎回起動が保証されているという訳でもありません。(FAQより)
特にGPUの必要性はないのでCPUで起動してみます。

起動して、残り時間が表示されます。Open Projectをクリックします。

Jupyter Notebook環境が表示されました!最初はGetting Startedのノートブックが1つあるだけでした。
学習プログラムを書いてみる
せっかくなので機械学習モデルを作ってみたいと思います。ここはSageMaker Studio LabというよりはJupyterLabの機能紹介がメインになります。
今回はPyTorchのチュートリアルを参考に、MNISTのモデルを作ってみます。PyTorchはPythonのオープンソースの機械学習ライブラリです。
(参考)MNISTとは
手書き数字の大規模なデータで、今回のように勉強用途等で、画像から数字を予測するモデルを構築する場合に広く使われています。
それではやっていきます。まずは新規のノートブックを作成します。

チュートリアルのノートブックを見たい場合は、ターミナルをJupyter Notebook上で開いて以下のコマンドでダウンロードできます。
$ cd sagemaker-studiolab-notebooks/
$ wget https://pytorch.org/tutorials/_downloads/5ddab57bb7482fbcc76722617dd47324/nn_tutorial.ipynb
ダウンロードしたノートブックを左のメニューから選択することで内容確認できます。
ダウンロードしたノートブックを参考に、モデル作成に最低限必要なコードを自分のノートブックに実装していきます。
※PyTorchのコードにあまり興味が無い方は読み飛ばしてください※
全体のソースコードは以下のようになりました。
# ライブラリインストール %pip install requests %pip install matplotlib %pip install torch # モジュールimport from pathlib import Path import requests import pickle import gzip from matplotlib import pyplot import numpy as np import torch from torch import nn from torch import optim from torch.utils.data import DataLoader from torch.utils.data import TensorDataset import torch.nn.functional as F # MNISTデータダウンロード、読込 DATA_PATH = Path("data") PATH = DATA_PATH / "mnist" PATH.mkdir(parents=True, exist_ok=True) URL = "https://github.com/pytorch/tutorials/raw/master/_static/" FILENAME = "mnist.pkl.gz" if not (PATH / FILENAME).exists(): content = requests.get(URL + FILENAME).content (PATH / FILENAME).open("wb").write(content) with gzip.open((PATH / FILENAME).as_posix(), "rb") as f: ((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1") # 画像の確認(1枚目) pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray") print(x_train.shape) # Torch形式にデータを変換 x_train, y_train, x_valid, y_valid = map( torch.tensor, (x_train, y_train, x_valid, y_valid) ) n, c = x_train.shape # Dataloaderの使用 bs = 64 train_ds = TensorDataset(x_train, y_train) train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True) valid_ds = TensorDataset(x_valid, y_valid) valid_dl = DataLoader(valid_ds, batch_size=bs * 2) # nn.Sequentialモデルの実装 #https://pytorch.org/tutorials/beginner/nn_tutorial.html#nn-sequential lr = 0.1 #学習率 epochs = 10 #エポック数 class Lambda(nn.Module): def __init__(self, func): super().__init__() self.func = func def forward(self, x): return self.func(x) def preprocess(x): return x.view(-1, 1, 28, 28) def fit(epochs, model, loss_func, opt, train_dl, valid_dl): for epoch in range(epochs): model.train() for xb, yb in train_dl: loss_batch(model, loss_func, xb, yb, opt) model.eval() with torch.no_grad(): losses, nums = zip( *[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl] ) val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) print(epoch, val_loss) def loss_batch(model, loss_func, xb, yb, opt=None): loss = loss_func(model(xb), yb) if opt is not None: loss.backward() opt.step() opt.zero_grad() return loss.item(), len(xb) model = nn.Sequential( Lambda(preprocess), nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.AvgPool2d(4), Lambda(lambda x: x.view(x.size(0), -1)), ) opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9) loss_func = F.cross_entropy fit(epochs, model, loss_func, opt, train_dl, valid_dl) # 画像とその予測結果を表示 data = x_valid[0] preds = model(data) # predictions print(torch.argmax(preds)) pyplot.imshow(data.reshape((28, 28)), cmap="gray")
ノートブックでは随時次のように実行結果を確認しながら進めることができます。
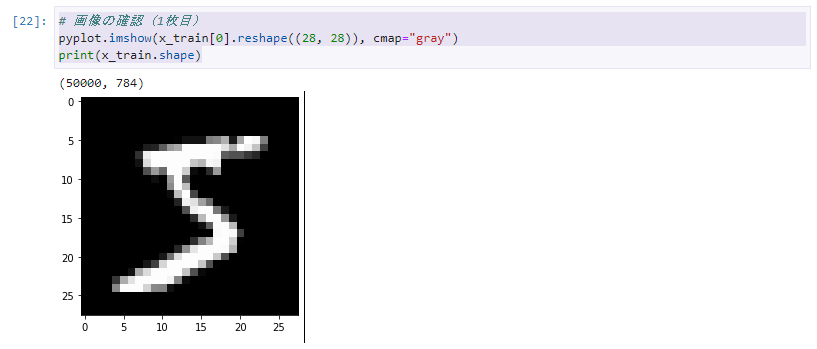
学習データの画像を表示したり、
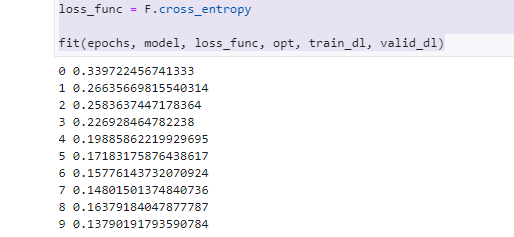
損失の状況を確認したり(良い感じに減って学習できています)、
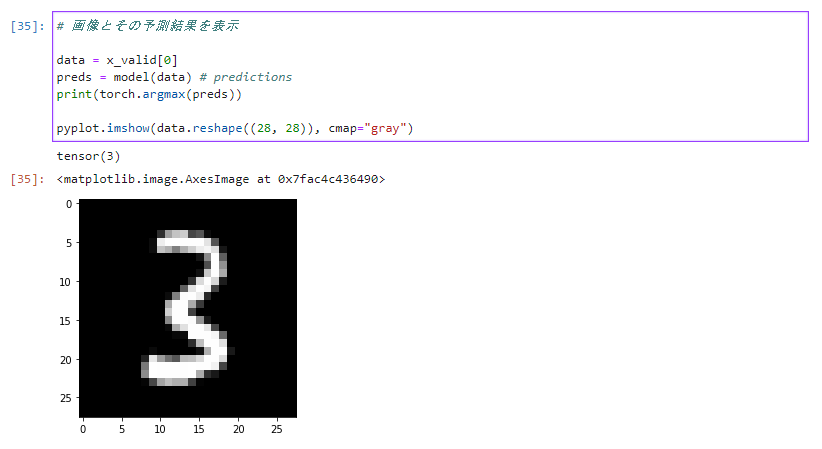
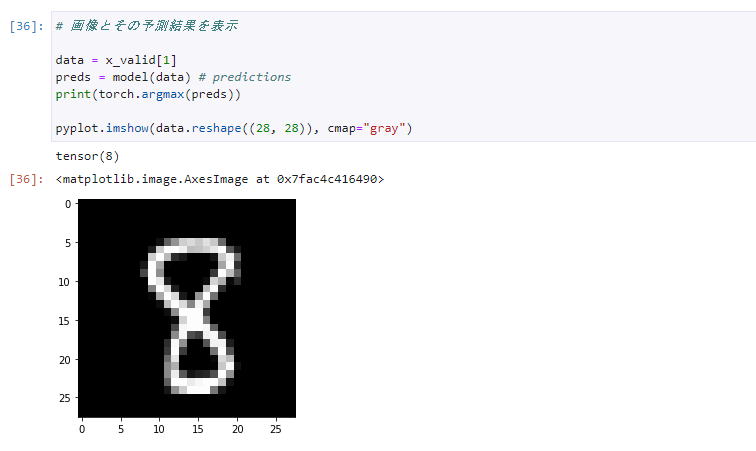
作成したモデルの予測も確認できます。tensor()の()内の数字が予測結果で、表示されている画像が予測対象の画像です。
いくつか(検証データで)試しましたが良い感じで予測できています。
3
 8
8
 6
6

検証は以上です。
まとめ
Amazon SageMaker Studio Labはパブリックプレビュー状態ですが、勉強、検証用途のサービスになりますので、積極的に使ってみてはいかがでしょうか。繰り返しになりますが無料なのが最高ですね。
AWSアカウント上でJupyterノートブックや、Cloud9などのIDEを使っている場合、心のどこかに「あぁ、今起動してるから料金発生しているな・・」という気持ちが残ります。そういったことを気にせず学習できるのは素晴らしいですね。GPUも使用できるので、それなりに大規模なデータ、複雑なニューラルネットワークなども実装できそうです。
また、ここで作成したプロジェクトをAWSアカウントのSageMaker Studioにも持っていけるようです。(FAQより)
PoC的にAWSアカウントもお金も不要のLabで試して、うまくいったらAWSアカウントを作成して本格構築という進め方もできそうですね。
GoogleにはColaboratoryという似たサービスがあるので、そことどう違いが出てくるのか今後も気になるところです。
それでは!
