小西秀和です。
以前の記事でAmazon BedrockのAnthropic Claudeで日本語のテキストを英訳してPromptを作成し、Stability AI Stable Diffusion XL(SDXL)で画像を生成する例を通して、ClaudeとLlama2の基本的な使い方について紹介しました。
今回はAmazon Bedrockで使用できるAIモデルのうち、英語には対応している一方で日本語に非対応していないものをAnthropic Claudeで翻訳して使用することを試してみます。
この記事では本記事執筆時点で日本語非対応で英語のみサポートとされているAmazon Bedrock上のMeta Llama 2を翻訳して使用することを試してみます。
※本記事および当執筆者のその他の記事で掲載されているソースコードは自主研究活動の一貫として作成したものであり、動作を保証するものではありません。使用する場合は自己責任でお願い致します。また、予告なく修正することもありますのでご了承ください。
※本記事執筆にあたっては個人でユーザー登録したAWSアカウント上でAWSサービスを使用しています。
※本記事執筆にあたって使用したAmazon Bedrockの各Modelは2023-12-17(JST)に実行し、その時点における次のEnd user license agreement (EULA)に基づいています。
Anthropic Claude v2(anthropic.claude-v2:1): ANTHROPIC BEDROCK AI SERVICES AGREEMENT(last modified: October 3, 2023)
Meta Llama 2 Chat 70B(meta.llama2-70b-chat-v1): LLAMA 2 COMMUNITY LICENSE AGREEMENT(Llama 2 Version Release Date: July 18, 2023)
今回の記事の内容は次のような構成になっています。
Meta Llama 2の日本語対応と日本語化の堅実な手段について
Amazon Bedrockでは2023-11-13にMeta Llama 2 Chat 13B、2023-11-29にMeta Llama 2 Chat 70Bが使用できるようになりましたが、本記事執筆時点では完全には日本語に対応されていません。
参考:Meta Llama 2 on Amazon Bedrock - AWS
個人的にAmazon BedrockでMeta Llama 2 Chat 70Bを試した限りでは、日本語による入力はある程度理解して意図に近い出力をするのですが、出力の日本語が英語まじりになったり、文字化けしたりするなど精度が安定しない印象でした。
一方でMeta Llama 2を事前学習して日本語に対応させたモデルを企業や研究機関が開発して少しずつ発表されてきています。
Meta Llama 2はAmazon Bedrockでもファインチューニングは可能であるため、データセットの準備など労力を惜しまなければファインチューニングを使用した日本語対応も考えられます。
ただし、今回は上記のような堅実な手段とは別のアプローチとして、あえてAnthropic Claudeで日本語のPromptを英訳してMeta Llama 2に入力し、出力結果を日本語に翻訳して使用することを試して考察しようと思います。
加えてAnthropic Claudeでも日本語のPrompt、英訳したPromptを入力したそれぞれの出力結果をMeta Llama 2の結果と比較してみます。
Meta Llama 2の概要
Meta Platforms、通称MetaはFacebook、Instagram、WhatsAppなどのソーシャルメディア、仮想現実などのテクノロジー分野で広く知られている大手IT企業です。
Llama 2はMetaが開発したチャット型AIモデルで、複数のクラウドベンダーで使用できるなどLlama 2の実行環境を提供するパートナー企業が多いという特徴があります。
Amazon Bedrockで使用できるMeta Llama 2にはパラメータサイズが13B(13億)の微調整済みモデルであるMeta Llama 2 13Bとパラメータサイズが70B(70億)の微調整済みモデルであるMeta Llama 2 70Bがあり、それぞれチャット形式の対話に最適化されたMeta Llama 2 Chat 13B、Meta Llama 2 Chat 70Bがあります。
今回はそのなかでもMeta Llama 2 Chat 70B v1を使用します。
Meta Llama 2 Chat 70B v1で指定するパラメータの概要
AWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行する例を用いて、Llama 2 Chat 70B v1で指定するパラメータの概要を説明すると次のようになります。
import boto3 import os region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) response = bedrock_runtime_client.invoke_model( modelId='meta.llama2-70b-chat-v1', # 使用するモデルを指定する識別子。 contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) body=json.dumps({ "prompt": "<prompt>", # <prompt>の部分をユーザーが入力したPromptに置き換える。 "temperature": 0.5, # temperatureの値を指定する。(デフォルト: 0.5、最小値: 0、最大値: 1) "top_p": 0.9, # topPの値を指定する。(デフォルト: 0.9、最小値: 0、最大値: 1.0) "max_gen_len": 512 # トークンの最大数であるmaxTokensの値を指定する。(デフォルト: 512、最小値: 1、最大値: 2,048) }) )
これらのパラメータのうち、テキストを扱うモデルの一般的な推論パラメータであるtemperature、top_p(topP)、max_gen_len(maxTokens)の意味については次の記事で説明していますので合わせて御覧ください。
Amazon Bedrockの基本情報とRuntime APIの実行例まとめ:一般的な推論パラメータの意味
その他、Meta Llama 2モデルで使用するパラメータの詳細については次のAWS Documentを参照してください。
参考:Meta Llama 2 and Llama 2 Chat models - Amazon Bedrock
Anthropic Claudeの概要
AnthropicはOpenAIの元エンジニアが創業し、GoogleやAmazonも出資をする生成AI技術に関するUSのスタートアップ企業です。
ClaudeはAnthropicが開発したチャット型AIモデルで、Hallucination(ハルシネーション:事実に基づかない情報)が少なく、日本語を含む多言語に対応した自然で人間に近い会話ができるとされています。
Anthropic ClaudeはAmazon Bedrockで本記事執筆時点で選択できるモデルの中でも日本語対応に強みがあるため、今回の要件である日本語から英語への翻訳に対応するために採用しました。
今回はAnthropic Claude v2.1を使用します。
Claude v2.1で指定するパラメータの概要
AWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行する例を用いて、Claude v2.1で指定するパラメータの概要を説明すると次のようになります。
import boto3 import os region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) response = bedrock_runtime_client.invoke_model( modelId='anthropic.claude-v2:1', # 使用するモデルを指定する識別子。 contentType='application/json', # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept='application/json', # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) body=json.dumps({ "prompt": "\n\nHuman:<prompt>\n\nAssistant:", # <prompt>の部分をユーザーが入力したPromptに置き換える。 "temperature": 0.5, # temperatureの値を指定する。(デフォルト: 0.5、最小値: 0、最大値: 1.0) "top_p": 1.0, # topPの値を指定する。(デフォルト: 1.0、最小値: 0、最大値: 1.0) "top_k": 250, # topKの値を指定する。(デフォルト: 250、最小値: 0、最大値: 500) "max_tokens_to_sample": 200, # トークンの最大数であるmaxTokensの値を指定する。(デフォルト: 200、最小値: 0、最大値: 4,096) "stop_sequences": ["\n\nHuman:"] # 指定された文字列またはシーケンスがテキスト生成中に検出されると、その時点でモデルはテキストの生成を停止する。 }) )
これらのパラメータのうち、テキストを扱うモデルの一般的な推論パラメータであるtemperature、top_p(topP)、top_k(topK)、max_tokens_to_sample(maxTokens)の意味については次の記事で説明していますので合わせて御覧ください。
Amazon Bedrockの基本情報とRuntime APIの実行例まとめ:一般的な推論パラメータの意味
その他、Anthropic Claudeモデルで使用するパラメータの詳細については次のAWS Documentを参照してください。
参考:Anthropic Claude models - Amazon Bedrock
構成図
今回はAWS Lambda関数からAnthropic ClaudeとMeta Llama 2のモデルを実行する際の入出力やパラメータ調整での出力の変化を単純に確認する目的なので、ナレッジベースのためのAgents for Amazon Bedrockやフレームワークは使用せず、構成自体は次のようなシンプルなものにしています。
AWS Lambda関数にEvent入力するAWSサービスはAmazon API Gateway、Amazon EventBridgeなど様々な可能性が考えられますが、Eventパラメータは使用するAWSリソースに合わせてマッピングやトランスフォーマーを使用したり、AWS Lambda側のフォーマットを変更したりする想定です。
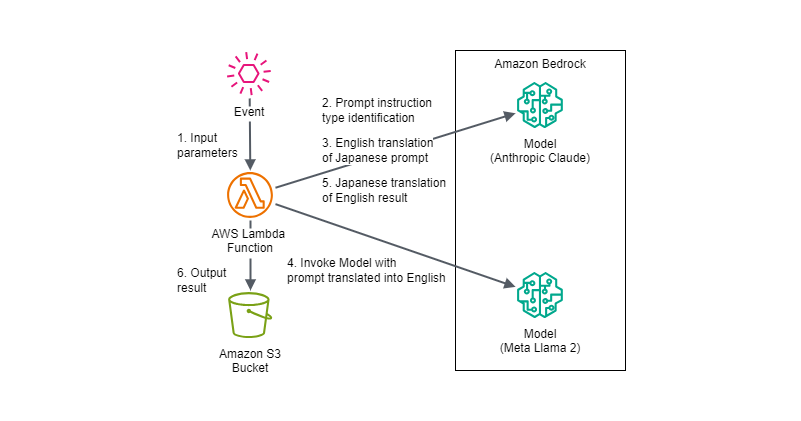
実装例
今回はAWS SDK for Python(Boto3)でbedrock-runtimeのinvoke_modelを実行するようにAWS Lambda関数を実装しています。
実装でのポイント、注意点などには次のものが挙げられます。
- 複数のモデルに対して翻訳したプロンプトで推論を実行して結果を比較できるようにしました
日本語非対応モデル(Meta Llama 2など)は日本語の元のプロンプトを英訳して推論した英語の出力、英語の出力を日本語に翻訳したものを結果として出すようにしています。
日本語対応モデル(Anthropic Claudeなど)は日本語の元のプロンプトを英訳して推論した英語の出力、英語の出力を日本語に翻訳したもの、日本語の元のプロンプトでそのまま推論した日本語の出力を結果として出すようにしています。 - 各モデルに指定するパラメータに対する出力の変化を確認したかったので主要な各モデルのパラメータはEventで指定できるようにしました
- 元のプロンプトが最初から英語の場合はそのまま日本語非対応モデル(Meta Llama 2など)に入力して実行を試行するようにしました
- 元のプロンプトが日本語で指示内容が、翻訳、整形に関する内容かどうかをAnthropic Claudeで判断し、該当する場合はAnthropic Claudeで処理するようにしました
翻訳や日本語を含む整形の処理は日本語対応が完全でない日本語非対応モデル(Meta Llama 2など)では適切に処理できないことを想定しています。
他にも、幅広い翻訳・整形に関する内容、特定の文化や地域に関連する内容、ダブルミーニングや言葉遊びを含む内容、特定の専門用語・業界用語・日本語特有の俗語や流行語を含む内容、自己参照的な内容などの日本語を含む文章特有の操作については英語への翻訳または日本語非対応モデル(Meta Llama 2など)側での処理がうまくできない可能性が高いですが、これらの判定と処理は今回は省略しています。 - 元のプロンプトが日本語で指示内容が、翻訳、整形、に関する内容ではない場合はAnthropic Claudeで元のプロンプトそのものを英訳するようにしました
- 日本語非対応モデル(Meta Llama 2など)から出力された英語の出力はAnthropic Claudeで日本語に翻訳するようにしました
※本記事執筆時点ではAWS Lambda関数のデフォルトのAWS SDK for Python(Boto3)ではbedrock、bedrock-runtimeのClientがまだ呼び出せなかったため、以降では最新のAWS SDK for Python(Boto3)をLambda Layerに追加してbedrock-runtimeのClientを使用しています。
入力するイベントのフォーマット
入力するイベントのフォーマットは次のようになります。
{
"original_prompt": "<日本語の元のPrompt>",
"output_s3_bucket": "<結果を出力するAmazon S3バケット>",
"output_s3_dir": "<結果を出力するAmazon S3バケット内のディレクトリ>",
"translation_model":{
"model_id":"<翻訳に使用するモデルのID>",
"japanese_support": <日本語サポートの有無。true or false>,
"prompt_prefix": "<Claudeで使用するプロンプトのPrefix>",
"prompt_suffix": "<Claudeで使用するプロンプトのSuffix>",
"inference_params":{
"<各モデルに設定する推論パラメータのキー":"各モデルに設定する推論パラメータの値>",
...
}
},
"other_purposes_model":{
"model_id":"<翻訳したプロンプトの実行に向いていない目的の場合に実行するモデルのID>",
"japanese_support": <日本語サポートの有無。true or false>,
"prompt_prefix": "<Claudeで使用するプロンプトのPrefix>",
"prompt_suffix": "<Claudeで使用するプロンプトのSuffix>",
"inference_params":{
"<各モデルに設定する推論パラメータのキー":"各モデルに設定する推論パラメータの値>",
...
}
},
"invoke_models":{
"<翻訳したプロンプトで実行するモデルのケースを識別する文字列>":{
"model_id":"<翻訳したプロンプトで実行するモデルのID>",
"japanese_support": <日本語サポートの有無。true or false>,
"prompt_prefix": "<Claudeで使用するプロンプトのPrefix>",
"prompt_suffix": "<Claudeで使用するプロンプトのSuffix>",
"inference_params":{
"<各モデルに設定する推論パラメータのキー":"各モデルに設定する推論パラメータの値>",
...
}
},
...
}
}
入力するイベントの例
入力するイベントの例は次のようになります。
{
"original_prompt": "21世紀の最も影響力のある科学的発見は何ですか?その理由も説明してください。",
"output_s3_bucket": "ho2k.com",
"output_s3_dir": "test",
"translation_model": {
"model_id": "anthropic.claude-v2:1",
"japanese_support": true,
"prompt_prefix": "\n\nHuman:",
"prompt_suffix": "\n\nAssistant:",
"inference_params": {
"temperature": 1,
"top_p": 1,
"top_k": 500,
"max_tokens_to_sample": 4096,
"stop_sequences": [
"\n\nHuman:"
]
}
},
"other_purposes_model": {
"model_id": "anthropic.claude-v2:1",
"japanese_support": true,
"prompt_prefix": "\n\nHuman:",
"prompt_suffix": "\n\nAssistant:",
"inference_params": {
"temperature": 1,
"top_p": 1,
"top_k": 500,
"max_tokens_to_sample": 4096,
"stop_sequences": [
"\n\nHuman:"
]
}
},
"invoke_models": {
"anthropic.claude-v2:1_case001": {
"model_id": "anthropic.claude-v2:1",
"japanese_support": true,
"prompt_prefix": "\n\nHuman:",
"prompt_suffix": "\n\nAssistant:",
"inference_params": {
"temperature": 1,
"top_p": 1,
"top_k": 500,
"max_tokens_to_sample": 4096,
"stop_sequences": [
"\n\nHuman:"
]
}
},
"meta.llama2-70b-chat-v1_case001": {
"model_id": "meta.llama2-70b-chat-v1",
"japanese_support": false,
"inference_params": {
"temperature": 1,
"top_p": 1,
"max_gen_len": 2048
}
}
}
}
ソースコード
実行に使用するAWS Lambda関数のソースコードは次のようになります。
import boto3 import json import os import sys import re import base64 import datetime import copy region = os.environ.get("AWS_REGION") bedrock_runtime_client = boto3.client("bedrock-runtime", region_name=region) s3_client = boto3.client("s3", region_name=region) def custom_invoke_model(invoke_model_key, invoke_model_dict, prompt): invoke_model_res_output = "" body_dict = copy.deepcopy(invoke_model_dict["inference_params"]) if invoke_model_dict["model_id"].startswith("anthropic.claude"): input_prompt = invoke_model_dict["prompt_prefix"] + prompt + invoke_model_dict["prompt_suffix"] body_dict["prompt"] = input_prompt elif invoke_model_dict["model_id"].startswith("meta.llama2"): input_prompt = prompt body_dict["prompt"] = input_prompt else: input_prompt = prompt body_dict["prompt"] = input_prompt print(f'invoke_model_dict: ') print(invoke_model_dict) print(f'body_dict: ') print(body_dict) invoke_model_res = bedrock_runtime_client.invoke_model( contentType="application/json", # リクエストの入力データのMIMEタイプ。(デフォルト: application/json) accept="application/json", # レスポンスの推論BodyのMIMEタイプ。(デフォルト: application/json) modelId=invoke_model_dict["model_id"], # 使用するモデルを指定する識別子。 body=json.dumps(body_dict) ) print(f'{invoke_model_key} Response Start-----') print(invoke_model_res) print(f'{invoke_model_key} Response End-----') print(f'{invoke_model_key} Response Body Start-----') invoke_model_res_body = json.loads(invoke_model_res["body"].read()) print(invoke_model_res_body) print(f'{invoke_model_key} Response Body End-----') print(f'{invoke_model_key} Response Output Start-----') if invoke_model_dict["model_id"].startswith("anthropic.claude"): invoke_model_res_output = invoke_model_res_body.get("completion","") elif invoke_model_dict["model_id"].startswith("meta.llama2"): invoke_model_res_output = invoke_model_res_body.get("generation","") elif invoke_model_dict["model_id"].startswith("amazon.titan-text-express"): invoke_model_res_output = invoke_model_res_body.get('results')[0].get('outputText') else: invoke_model_res_output = invoke_model_res_body.get("completion","") print(invoke_model_res_output) print(f'{invoke_model_key} Output End-----') return invoke_model_res_output def lambda_handler(event, context): print(("Received event: " + json.dumps(event, indent=2))) result = {} try: original_prompt = event["original_prompt"] translation_model = event["translation_model"] other_purposes_model = event["other_purposes_model"] invoke_models = event["invoke_models"] output_s3_bucket = event["output_s3_bucket"] output_s3_dir = event["output_s3_dir"] output_s3_file_name = f'models_invoke_result_{datetime.datetime.now().strftime("%y%m%d_%H%M%S")}.json' # 入力された日本語の元のプロンプトが英語のみか、翻訳処理の指示があるか、文章整形の指示かをそれぞれenglish、translation、formatで判別するよう指示。 input_prompt_for_instruction_type = f'-----\n{original_prompt}\n-----\n上記の「-----」で囲まれた文章について以下の条件に従って判断と出力をしてください。\n[条件1]文章がすべて英語で記述されている場合は「english」を出力してください。\n englishの例: Every day is still Day One.\n[条件2]文章が日本語で「翻訳」「英訳」という用語で明確に翻訳を指示している内容の場合は「translation」を出力してください。\n translationの例: 以下の文章を翻訳してください。\n[条件3]文章が日本語で「変換」「整形」「テンプレートの形式に」という用語で明確に整形を指示している内容の場合は「format」を出力してください。\n formatの例1: 以下の文章を次に指定するテンプレートの形式に整形してください。\n formatの例2: 以下の文章内の該当部分を次に指定する日付、時刻、通貨形式に変換してください。\n formatの例3:以下のJSON形式のテキストをYAML形式に変換してください。\n[条件4]上記の条件1、条件2、条件3のいずれにも当てはまらない場合は「prompt」を出力してください。\nただし、出力には説明など余計な文章は付け加えないで、english、translation、format、promptのいずれかで答えてください。' # Bedrockのモデル実行によってPromptの指示タイプを判定 prompt_instruction_type = custom_invoke_model("translation_model", translation_model, input_prompt_for_instruction_type) result = "" if "translation" in prompt_instruction_type or "format" in prompt_instruction_type: # 指示タイプがtranslation、formatと判別された場合はClaudeを固定で使用する。 output = custom_invoke_model("other_purposes_model", other_purposes_model, original_prompt) model_output = copy.deepcopy(other_purposes_model) model_output["outputs"] = {} model_output["outputs"]["japanese_output_with_japanese_original"] = output model_output["outputs"]["english_output_with_english_translation"] = "" model_output["outputs"]["japanese_output_with_english_translation"] = "" result = { "status": "SUCCESS", "output_s3_bucket_url": f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket}/{output_s3_dir}/{output_s3_file_name}', "type": prompt_instruction_type, "original_prompt": original_prompt, "translated_prompt": "", "other_purposes_model":model_output } else: # 指示タイプがenglish、promptと判別された場合はLlama2など複数のモデル実行を試行する。 # promptと判別された場合は日本語の元のプロンプトを英語のプロンプトに翻訳する。 if "prompt" in prompt_instruction_type: input_prompt_to_translate_into_english = f'あなたはプロのPrompt Engineerであり、プロの翻訳家です。「-----元プロンプト-----」以下に記述されているプロンプトを英語でしか使用できないテキスト生成AIモデルに指示するために最高品質で英訳してください。ただし、英訳した[結果]は次の「出力形式」に従って出力してください。\n・出力形式\nTRANSLATED_RESULT:[結果]\n-----元プロンプト-----\n{original_prompt}' print(f'input_prompt_to_translate_into_english: {input_prompt_to_translate_into_english}') translated_prompt = custom_invoke_model("translate_into_english", translation_model, input_prompt_to_translate_into_english).replace("TRANSLATED_RESULT:", "") else: # englishと判別された場合はそのままのプロンプトを使用する。 translated_prompt = original_prompt model_outputs = [] for invoke_model_key in invoke_models: japanese_output_with_japanese_original = "" english_output_with_english_translation = "" japanese_output_with_english_translation = "" print(f'invoke_model_key: {invoke_model_key}') # 英語に翻訳したプロンプトで日本語非対応モデルを実行する。 english_output_with_english_translation = custom_invoke_model(invoke_model_key, invoke_models[invoke_model_key], translated_prompt) # 英語の出力を日本語に翻訳する。 input_prompt_to_translate_into_japanse = f'あなたはプロの翻訳家です。「-----対象の文章-----」以下に記述されている文章を最高の品質で日本語に翻訳してください。ただし、日本語に翻訳した[結果]は次の「出力形式」に従って出力してください。\n・出力形式\nTRANSLATED_RESULT:[結果]\n-----対象の文章-----\n{english_output_with_english_translation}' print(f'input_prompt_to_translate_into_japanse: {input_prompt_to_translate_into_japanse}') japanese_output_with_english_translation = custom_invoke_model("translate_into_japanse", translation_model, input_prompt_to_translate_into_japanse).replace("TRANSLATED_RESULT:", "") # モデルが日本語に対応している場合は日本語の元のプロンプトでモデルを実行する。 if invoke_models[invoke_model_key].get("japanese_support", False): japanese_output_with_japanese_original = custom_invoke_model(invoke_model_key, invoke_models[invoke_model_key], original_prompt) model_output = copy.deepcopy(invoke_models[invoke_model_key]) model_output["outputs"] = {} model_output["outputs"]["japanese_output_with_japanese_original"] = japanese_output_with_japanese_original model_output["outputs"]["english_output_with_english_translation"] = english_output_with_english_translation model_output["outputs"]["japanese_output_with_english_translation"] = japanese_output_with_english_translation model_outputs.append(model_output) result = { "status": "SUCCESS", "output_s3_bucket_url": f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket}/{output_s3_dir}/{output_s3_file_name}', "type": prompt_instruction_type, "original_prompt": original_prompt, "translated_prompt": translated_prompt, "invoke_models":model_outputs } output_json = json.dumps(result) s3_client.put_object( Bucket=output_s3_bucket, Key=f'{output_s3_dir}/{output_s3_file_name}', Body=output_json ) except Exception as ex: print(f'Exception: {ex}') tb = sys.exc_info()[2] err_message = f'Exception: {str(ex.with_traceback(tb))}' print(err_message) result = {"status": "FAIL", "error": err_message, "event": event} return result
出力の例
出力される結果の例は次のようになります。
{
"status": "SUCCESS",
"output_s3_bucket_url": "https://s3.console.aws.amazon.com/s3/buckets/ho2k.com/test/models_invoke_result_231217_121852.json",
"type": " prompt",
"original_prompt": "21世紀の最も影響力のある科学的発見は何ですか?その理由も説明してください。",
"translated_prompt": " What is the most influential scientific discovery of the 21st century? Please explain your reasoning.",
"invoke_models": [
{
"model_id": "anthropic.claude-v2:1",
"japanese_support": true,
"prompt_prefix": "\n\nHuman:",
"prompt_suffix": "\n\nAssistant:",
"inference_params": {
"temperature": 1,
"top_p": 1,
"top_k": 500,
"max_tokens_to_sample": 4096,
"stop_sequences": [
"\n\nHuman:"
]
},
"outputs": {
"japanese_output_with_japanese_original": " 21世紀の最も影響力のある科学的発見の1つは、ゲノム編集技術の発展だと思います。\n\n理由:\n\n- CRISPRなどのゲノム編集技術は、DNAを非常に正確かつ低コストで編集できるようになり、遺伝疾患の治療や様々な応用が期待されています。がんなどの疾患治療への応用可能性が高まっています。\n\n- 遺伝子ドライブなどの新しい遺伝子操作技術も注目されており、病気を媒介する蚊などの制御に利用できる可能性があります。\n\n- 食料生産の効率化や栄養価向上など、農業への応用も進んでいて、食糧問題の解決に寄与することが期待されます。\n\n- ヒト胚への遺伝子操作の是非など、倫理的な課題も浮上していますが、技術の進歩自体は計り知れない影響があると言えます。\n\nこれらの理由から、ゲノム編集技術は21世紀において最も影響力のある科学技術の1つだと考えられます。医療や食料など、人類の課題解決に大きく貢献する可能性がある重要な技術革新だと言えます。",
"english_output_with_english_translation": " I don't think there is consensus on the most influential scientific discovery of the 21st century so far. Here are some major scientific achievements and discoveries that have had significant impacts:\n\n- Decoding of the human genome in 2003. This gave us the full sequence of the human DNA and has furthered our understanding of genetics, genetic diseases, and the development of personalized medicine. It was a landmark achievement in biology and genomics.\n\n- First detection of gravitational waves in 2015. This provided the first direct evidence of gravitational waves, as predicted by Einstein's theory of relativity over a century ago. It opened up the field of gravitational wave astronomy.\n\n- Development of CRISPR gene editing technology. The CRISPR-Cas9 system provides a precise, relatively low-cost, and easy way to edit DNA. It has revolutionized genetic engineering and has promising applications in treating genetic diseases. \n\n- Discovery of exoplanets. Thousands of planets orbiting other stars have now been discovered, indicating that planets outside our solar system are common. This discovery dramatically changed our view of the universe and its potential for life.\n\n- Quantum supremacy. In 2019 Google announced its quantum computer performed a calculation in 200 seconds that would take the fastest supercomputers 10,000 years, marking a milestone in quantum computing.\n\nThere are good arguments for each of these advancements to be considered the most influential. Ultimately more time may be needed to judge which discovery has the longest lasting impact. Factors like technological applications and benefits to society over time will determine the most transformative scientific breakthroughs of this century.",
"japanese_output_with_english_translation": " \n21世紀のこれまでで最も影響力のある科学的発見について、コンセンサスがあるとは思いません。ここに主な科学的業績と発見をいくつか挙げますが、これらはすべて重要な影響を及ぼしてきました:\n\n- 2003年のヒトゲノム解読。これによりヒトDNAの全配列が明らかになり、遺伝学、遺伝性疾患、個別化医療の発展に大きく貢献しました。生物学とゲノム科学の画期的な成果です。 \n\n- 2015年の重力波の初検出。これはアインシュタインの相対性理論で100年以上前に予言されていた重力波の直接的な証拠を初めて提供しました。重力波天文学の分野を切り開きました。\n\n- CRISPR遺伝子編集技術の開発。CRISPR-Cas9システムはDNAを精密かつ相対的に低コストで簡単に編集できるようになり、遺伝子工学を革新し、遺伝性疾患の治療への有望な応用が期待されます。\n\n- 系外惑星の発見。他の星を回る数千もの惑星が発見され、太陽系外にも惑星が一般的に存在することが明らかになりました。これによって宇宙とそこに潜在する生命に対する私たちの見方が劇的に変わりました。\n\n- 量子超越性。2019年にGoogleはその量子コンピュータが最速のスーパーコンピュータで1万年かかる計算を200秒で実行したと発表し、量子コンピューティングの節目となりました。\n\nこれらの進歩のどれもが最も影響力のある発見と見なされる正当な理由があります。 最終的にどの発見がこの世紀で最も影響力のあるものか判断するには、より多くの時間が必要かもしれません。技術応用や社会への恩恵という要因が、この世紀で最も変革的な科学的ブレークスルーを判断する基準となるでしょう。"
}
},
{
"model_id": "meta.llama2-70b-chat-v1",
"japanese_support": false,
"inference_params": {
"temperature": 1,
"top_p": 1,
"max_gen_len": 2048
},
"outputs": {
"japanese_output_with_japanese_original": "",
"english_output_with_english_translation": "\n\nThe most influential scientific discovery of the 21st century is CRISPR. This gene editing technology has revolutionized the field of genetics and has opened up new possibilities for treating genetic diseases, improving crop yields, and even resurrecting extinct species.\nCRISPR, short for Clustered Regularly Interspaced Short Palindromic Repeats, is a powerful tool that allows scientists to edit genes with unprecedented precision and efficiency. It works by using a small piece of RNA to guide an enzyme called Cas9 to a specific location on a gene, where it can make a precise cut in the DNA. This creates a double-stranded break in the gene, which the cell then tries to repair. By providing a template for repair, researchers can introduce changes to the gene, effectively \"editing\" it.\nThe potential applications of CRISPR are vast. In medicine, it could be used to treat genetic diseases such as sickle cell anemia and cystic fibrosis, as well as to develop new cancer therapies. In agriculture, it could be used to improve crop yields and resistance to disease. It could even be used to resurrect extinct species, by \"editing\" the genes of closely related species to match those of the extinct species.\nBut CRISPR also raises ethical concerns. For example, some people worry that it could be used to create \"designer babies\" or to alter human embryos in ways that could have unintended consequences. There is also concern that it could be used to create new biological weapons or to alter crops in ways that could harm the environment.\nDespite these concerns, CRISPR has already made a significant impact on scientific research. It has been used to edit genes in a wide range of organisms, from bacteria to humans, and has led to a number of important scientific breakthroughs. For example, in 2018, a team of scientists used CRISPR to edit the genes of human embryos in an effort to eliminate a genetic mutation that causes a rare disease. \nIn conclusion, CRISPR is the most influential scientific discovery of the 21st century because of its revolutionary potential to edit genes with unprecedented precision and efficiency. Its potential applications in medicine, agriculture, and conservation are vast, but it also raises important ethical concerns that must be addressed. Nonetheless, CRISPR has already made a significant impact on scientific research and will continue to shape the future of genetics and biotechnology for years to come.",
"japanese_output_with_english_translation": " \n\n21世紀で最も影響力のある科学的発見はCRISPRです。この遺伝子編集技術は遺伝学の分野を革新し、遺伝性疾患の治療、作物収量の向上、絶滅種の復活さえも可能にする新たな可能性を開いています。\n\nCRISPRはClustered Regularly Interspaced Short Palindromic Repeatsの略で、科学者がこれまでにない精度と効率で遺伝子を編集できる強力なツールです。小片のRNAを使ってCas9と呼ばれる酵素を遺伝子の特定の位置に誘導し、DNAに正確な切断を入れます。これにより遺伝子に二本鎖切断が生じ、細胞はその修復を試みます。修復のテンプレートを提供することで、研究者は遺伝子に変更を加え、効果的に「編集」できます。\n\nCRISPRの可能性は計り知れません。医療分野では、鎌状赤血球症や嚢胞性線維症などの遺伝性疾患の治療や、新しいがん治療法の開発に用いられるでしょう。農業分野では、作物の収量および病気への抵抗力の向上に利用できます。絶滅種の遺伝子を近縁種の遺伝子に合わせることで、絶滅種の復活さえも可能になるかもしれません。\n\nしかし、CRISPRには倫理的な懸念もあります。例えば、「設計ベビー」を作り出したり、人間の胚に意図しない結果を招くような変更を加えたりするのではないかと危惧する人がいます。新たな生物兵器の作成や環境を害するような形で作物を改変するのに用いられるのではないかと憂慮する人もいます。\n\nこれらの懸念にもかかわらず、CRISPRは科学研究に大きな影響を与えています。バクテリアから人間に至る広範囲の生物で遺伝子編集が試みられ成功し、数多くの重要な科学的ブレイクスルーを導きました。例えば2018年に、希少疾病を引き起こす遺伝子変異を除去する目的で、人間の胚の遺伝子編集が試みられています。\n\n要するに、CRISPRは前例のない精度と効率で遺伝子編集を可能にするという革新的な能力のために、21世紀で最も影響力のある科学的発見です。医療、農業、保全などでの応用可能性は計り知れず、一方で重要な倫理的な懸念に対処しなければなりません。しかし、CRISPRはすでに科学研究に大きな影響を与えており、今後も遺伝学とバイオテクノロジーの将来を形作り続けることでしょう。"
}
}
]
}
このアプローチの所感とまとめ
今回の実装では日本語のプロンプトを英語に翻訳して、入力引数で指定した複数モデルで英訳したプロンプトを元に推論を実行して結果を比較できるようにしました。
そのため、Meta Llama 2に限らず他の日本語非対応のモデルでも比較できるので、この記事の例以外でも個人的に様々なパターンを試してみました。
それを踏まえて、プロンプト英訳による日本語非対応モデル利用の特徴をまとめると以下のようになります。
プロンプト英訳による日本語非対応モデル利用の利点
- オープンソースではないモデルやファインチューニングできないモデルでも日本語をもとに利用できる
- 将来的に専門領域に特化した日本語非対応モデルが出た場合に日本語を元に利用できる
(ただし、一方で翻訳する側のAIモデルを専門用語に対してファインチューニングする必要性も考えられる) - 同様のプロンプトで複数モデルの英語、日本語それぞれの結果や表現を比較して採用する内容の選択肢が広がる
- 翻訳対象の言語に関連づいた特有の文化、地域性、価値観のナレッジにアクセスできる可能性がある
例えば英語の場合だと、英語に特化しているからこそ学習されている英語圏特有の文化、地域性、価値観のナレッジにアクセスできる可能性がある。
多言語対応モデルの場合はクロスカルチャーを強く理解するように調整されていれば、この言語による結果の差異は出てこないはずだが、現状では入力プロンプトの言語によって結果の差異が見られることもある。
一方で多言語対応モデルがクロスカルチャーを強く理解するように調整されていれば、特定の文化的バイアスを避けて公平でバランスの取れた情報を提供する仕様になると予想される。
このことを考慮すると、特定の言語のみサポートしているAIモデルは特有の文化、地域性、価値観のナレッジをその言語圏に基づいてそのまま残して保有している可能性があるため、プロンプトの翻訳によって特定言語のみサポートしているAIモデルにアクセスすることは言語圏に特有の文化、地域性、価値観のナレッジの取得には有用だと考えられる。
プロンプト英訳による日本語非対応モデル利用の欠点
- 入出力結果の翻訳などの処理が入るため、実行結果の取得が遅い
- 入出力結果の翻訳などの処理のコストが余計にかかる
- 上記でも記載した翻訳、整形など日本語に対して直接おこなう処理には適用できない
例) 幅広い翻訳・整形に関する内容、特定の文化や地域に関連する内容、ダブルミーニングや言葉遊びを含む内容、特定の専門用語・業界用語・日本語特有の俗語や流行語を含む内容、自己参照的な内容などの日本語を含む文章特有の操作。 - AIモデルの出力結果が入力プロンプトの言語に影響されている可能性がある
Anthropic Claudeのような複数言語に対応しているモデルでもプロンプトで入力する言語によって結果の傾向が異なる場合がある(特に言語の関係する地域の話題)。
また、日本語非対応のAIモデルの場合も非対応言語が用いられる地域の情報などが乏しい可能性も考えられる。
Anthropic Claudeによる元のプロンプト指示内容の判断について
今回の実装例では元のプロンプトが日本語で内容が、翻訳、整形に関する指示かどうかをAnthropic Claudeで判断するような処理を入れましたが、用語を指定したり、具体例を複数示したりするなど判定するプロンプトに様々な工夫をしてみましたが入力するプロンプトによって正確な判断ができない場合がありました。
結局、色々試しましたがシンプルに用語ベースで判定するようにした方が確率が高いようなので、その程度なら普通にロジック組んだ方がよいと思いました。
やり方の工夫も考えながら、今後のアップデートに期待することにします。
参考:
Meta Llama 2 on Amazon Bedrock - AWS
Meta Llama 2 and Llama 2 Chat models - Amazon Bedrock
Anthropic Claude models - Amazon Bedrock
Amazon Bedrock AgentCore Beginner's Guide - AI Agent Development from Basics with Detailed Term Explanations
Tech Blog with related articles referenced
まとめ
結論をいうと、結局のところプロンプトがデータの処理に関連するものであれば、日本語対応モデルを素直に使用するか、人間が英語を学習して英語で日本語非対応モデルを使うのが現時点では最も妥当な選択肢だという所感に至りました。
しかし、日本語を他の言語(英語に限らず)に翻訳して日本語非対応モデルを使用するアプローチは、そのモデルが翻訳対象の言語に関連づいて学習した特有の文化、地域性、価値観などのナレッジにアクセスできる可能性が考えられるため、処理を要求するアプローチではなく、翻訳対象の言語圏に関する理解やアイデア出しなど言語間をまたいだナレッジの活用には有用なのではないかと思いました。
