こんにちは佐々木です。
それでも続くデータ分析基盤の設計シリーズの第六弾です。前回に引き続き、データ加工をテーマにします。今回は、GUIによるデータ加工処理についてです。将来的には、GUIが活躍する領域がもっと広がってくると予想していますが、その選定についての個人的な課題感についてです。なお、論理的にどういうパターンがあるかを整理しているだけで、具体的な製品についての紹介や言及はしません。
データプレパレーションについて
データプレパレーション(Data Preparation )とは、データ分析に先立って元データをクレンジングしたり分析しやすいように加工するプロセスです。いわゆる前処理にあたります。Preparationは直訳すると準備なので、データの準備ということですね。やっている事自体は、ETLそのものなのですが、データプレパレーション製品を提供する会社によると、ETLとは違うものと定義される事が多いです。ETLはSQLやプログラムの知識は必要だが、 データプレパレーションツールはGUIで操作できプログラミング不要とのことです。が、基本的には一緒のものだと思います。製品のカテゴリーとして、データプレパレーションというものがあると認識しておけば大丈夫です。
前回、データの民主化という概念を紹介したように、データ分析基盤を構築・運用する上で重要なのは、できるだけ自前で運用できるようにすることです。そのため、データ加工についても、自組織内で変更できるようにしておくと良いでしょう。前回はSQLを使うELTという手法を紹介しましたが、それでも厳しいという組織も多いでしょう。そこで、もう一つの選択肢として、GUIによるデータ加工が行えるデータプレパレーションツールを紹介します。
データプレパレーションツールと加工、データの所在について
データプレパレーションツールは、主にGUIでデータの前処理をするツールです。フォーマットの変更やデータ同士の結合をブラウザ等の画面をみながら操作できます。Excelで用途に応じて項目の変更を行うのを、ブラウザで行うようなイメージをしてもらえば大丈夫です。Excelの場合は大量のデータを扱うのは難しいですが、この手のツールを使うと、画面での表示はサンプリングデータを使う等の工夫がされている事が多く、データ量に関係なく編集できます。提供形態としては、パッケージ型とSaaS型が主流です
データプレパレーションツールの機能については、それぞれの要件に沿ったものを選択してください。ここではデータ加工が行われる場所と、データの連携について整理してみます。なお、今回の検討の前提として、AWSを利用するものとします。
データ加工の場所
データ加工の場所としては、自分のAWSのアカウントの中か外があります。
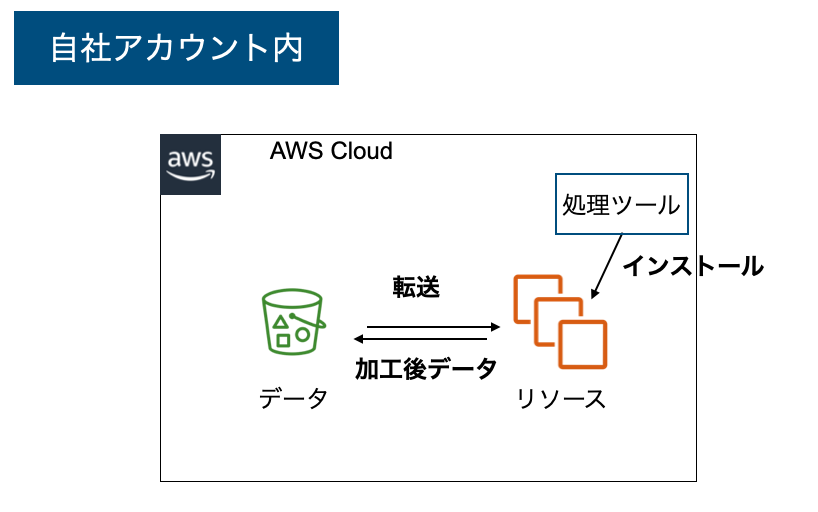
自前のAWSアカウント内
自分のアカウント内というのは、いわゆるパッケージタイプです。自分でインスタンス等のリソースを用意して、ツールをインストールするタイプです。データを外に持ち出す必要がなく設計上の考慮点が少ないです。一方で処理のためのリソースの管理や、インストールしたソフトウェアのアップデートなど、運用に関わるタスクを自分で行う必要があります。
自前のAWSアカウント外
自分のアカウント外というのは、主にデータプレパレーションツールがサービスとして提供されているパターンです。データ加工に関するリソースやソフトウェアの管理は、サービスの主体にお任せできます。一方で、データをどのように連携するか検討が必要です。

データの連携方法
次にデータの所在についてです。こちらについては、次の3パターンが考えられます。
- データ転送不要
- 外部にコピー
- 外部からデータ参照
データ転送不要
まず一つ目のデータ転送不要のパターンです。これは、自アカウント内にインストールするタイプで、データの扱いについてはあまり考える必要はありません。ただし、このタイプは自前の環境で動作させるタイプであるパッケージ型のみ利用可能で、SaaSタイプの利用はできません。

外部にコピー
2つ目は、外部にデータをコピーするタイプです。コピーする手段としては様々なルート・プロトコルがありますが、とにかく外部にデータを持ち出すパターンです。このパターンの肝としては、データ転送の管理です。検討事項として、データ転送費用や転送時間があります。また、場合によっては、サービス側に腹持ちしたデータとの差分管理が必要となります。データを持ち出すために、社内のポリシーやルールの確認も必要になるでしょう。SaaS型の場合、このような形態になります。

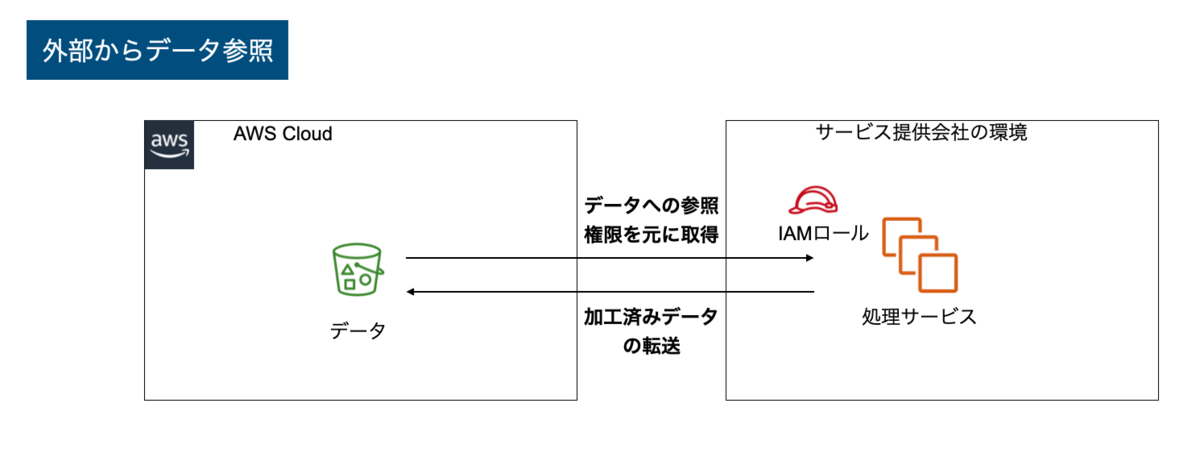
外部からデータ参照
3つ目のパターンとしては、外部からデータ参照してもらうパターンです。データの持出の観点としては、2つ目のパターンと本質的には同じです。しかし、外部のサービス自体がAWSで提供されている場合は、データの転送費用や転送時間に関して言うと1つ目の自アカウント内での処理とほぼ同じになるというメリットがあります。こちらもSaaS型のパターンの一つですね。
どのパターンが良いか?
データプレパレーションツールについて、加工処理の場所とデータの連携について整理してみました。これについては、どれが良いとか悪いという問題ではありません。処理するデータ量や、使う人のスキルを勘案の上で、どのようなアーキテクチャを選んでいくのかが設計です。一般論でいうと大量のデータを扱う場合は、外部のサービスと連携するタイプのサービスを使うと転送時間とコスト面から運用が難しいケースが多い事が多いです。また、逆にいうと、少量のデータの場合に自前でインストールや運用が必要なものは、相対的に有利になります。
最初はサービスを使って素早く成果を確かめて、本格的な運用をする際に改めてアーキテクチャを考えるでも良いのかもしれません。もちろん、その場合であってもサービスを使い続けるほうが良い場合もあります。
クラウド事業者が提供するデータプレパレーションツール
ここまで書いておきながら、実はもう一つのパターンがあります。それは、クラウド事業者(AWSやGoogle Cloud)自身が提供しているサービスを使うという方法があります。AWSだとGlue DataBrewがあり、Google CloudだとDataPrepがあります。個人的には、本命はこれです。最終的には今回問題提起したようなサードパーティ製ツールの問題を解決し、主流になってくるのではと思います
一方でAWSでいえば、他のGlue製品との使い分けについて、設計者がノウハウを蓄積する必要もありますし、併用や切り替え方法について予め考えておく必要があります。この辺り、別途調べた上でまとめてみようと思います。
まとめ
データ分析基盤を導入する組織は、今後とも増えてくるでしょう。データを分析する際には、前処理としてのデータの整形は不可欠です。データ分析基盤の普及が進むにつれて、今回紹介したようなデータプレパレーションツールの利用も増えてくるでしょう。今回のようなデータの所在や処理する場所は、導入を検討する際の観点の一つになります。クラウド事業者のさらなるサービス強化を期待するとともに、自分にとって必要なものは何かというのをしっかりと把握しておきましょう。
