本記事は
【Advent Calendar 2023】
17日目の記事です。
🎄
16日目
▶▶ 本記事 ▶▶
18日目
🎅

こんにちは。 2年目の草野です。年末が近づいてきましたね。
今回はAdvent Calendarの執筆に参加ということで、2023年の業務の中で印象深かったUnicodeについて少しお話したいと思います。
そもそもUnicodeとは
みなさんご存じの通り、Unicodeは文字を表すための国際的な標準規格の1つです。
一般的には [U+91CE] のように、16進数で表記されます。
常用文字は [U+0000] ~ [U+FFFF] の16進数4文字=2バイトの範囲に収まることが多いです。
Unicodeを作った当初は、この2バイト(65536文字)の範囲内で世の中のすべての文字が表現できると考えられていました。
しかしながら、実際はこの制限の中では世の中に存在する多様な文字すべてをカバーすることはできませんでした。
そこで、2バイトの範囲を拡張して、範囲に収まらなかった文字を無理やり表現しよう、となりました。
それがサロゲートペア文字と呼ばれる文字です。
サロゲートペア文字
サロゲートペア文字とは、従来未使用であったコードの中の、2つのコードの組み合わせ(ペア)で表現された文字です。
本来2バイトで1文字のところを、2バイト+2バイトの4バイトのデータで1文字を表現しています。
Unicodeにおいては、その4バイトのデータを独自の変換方法で変換し、 [U+10000] 〜 [U+10FFFF] の範囲のコードとして割り当てています。
具体的には下記のような文字がサロゲートペア文字にあたります。
「𩸽(ほっけ)」 : [U+29E3D] → [U+D867] と [U+DE3D]のペア
「😇(天使の輪がついた笑顔の絵文字)」 : [U+1F607] → [U+D83D] と [U+DE07]のペア
Unicodeは、増え続けていく文字に対してこのように対応していこうと頑張っているわけです。
突然ですが……
 いきなりですが、私の学生のころの話になります。
いきなりですが、私の学生のころの話になります。
学生のころは、生徒一覧の名簿が配布されることがたまにあると思います。
私の学校でもよく名簿が使用されていたのですが、ここで少し悲しい経験をしたことがあります。
私(草野)の名字の表記が「・野」になっているのです……。
なぜか?恐らく私の戸籍上の名字が、くさかんむりの間が離れた「草」であるためでしょう。(これ↓です)
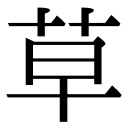 私としては一般的な「草野」という表記で名簿を作成してほしかったのですが、なぜか卒業までこの状態でした。
私としては一般的な「草野」という表記で名簿を作成してほしかったのですが、なぜか卒業までこの状態でした。
異体字セレクタとの出会い
社会人になるまでこんな出来事は忘れ去っていたのですが、業務の中でUnicodeについて調べていくうちにふと疑問に思いました。
私の名字ってどうやって表現するんだろう?
先生方の漢字変換の方法が悪かっただけで、実際は表示できる漢字なのではないか、と。
そこで調べていく中で、「異体字セレクタ」というものに出会いました。
異体字セレクタって?
全く同じ意味を持つ文字、異体字
漢字、特に人名には同じ漢字でもデザインが微妙に違う漢字って多いですよね。
有名どころだと「はしご高(髙)」でしょうか。
このように、標準の字体とは異なるものの、意味や発音が同じ字のことを「異体字」と呼びます。
異体字セレクタの誕生
はしご高のようにメジャーな異体字であれば1つの文字として登録すればよいですが、
私の名字のようなマイナーな異体字をいちいち登録していると、いずれサロゲートペア文字として拡張したコードの範囲内でも表現できなくなるかもしれません。
そこで、Unicodeにおいては、異体字のもととなる標準の文字(基底文字)に枝番を割り振ればよいのではないか、となりました。
この枝番が「異体字セレクタ」と呼ばれるものです。
Unicodeにおいて、異体字セレクタは [U+E0100] 〜 [U+E01EF] に割り当てられています。
このセレクタは単独では意味を持たず、基底文字のコードに付随することで異体字を表現できるようになります。
具体例
具体例をご紹介します。
東京都葛飾区の「カツ」と奈良県葛󠄀城市の「カツラ」は正確には異なる字です。
環境によっては同じ文字に見えてしまうかもしれないので、画像で示します 。
左が葛飾区の「カツ」、右が葛󠄀城市の「カツラ」です。


葛飾区の「葛」は基底文字であるため、Unicodeでは[U+845B]で登録されています。
一方で、葛城市の「葛󠄀」は標準で表示される文字ではないため、「葛」のコード [U+845B] に、
異体字セレクタである [U+E0102] を付与した [U+845B U+E0102] で登録されています。 *1
このように、異体字セレクタを使用することで、文字の微妙なデザインの違いを表現できるようになったのです。
結局私の名字はどう書くの?
こちらのサイトを参考に件の「草」を検索してみました。 moji.or.jp
Unicodeにおいて私の名字の「草」は、基底文字である「草」のコード [U+8349] に、
異体字セレクタである [U+E0102] を付与した [U+8349 U+E0102] で表現できるようです。
しかし、マイナーすぎる文字なのか、ほとんどのフォントには対応していないようでした……。
どうやら学生時代の先生方にはたいへんお手間をかけさせてしまっていたようです。

おわりに
少し技術的な話からは逸れてしまいましたが、いかがでしたでしょうか。
調べていくうちに、Unicodeが多種多様な文字の標準化になんとか取り組もうとする情景が浮かびました。
その反面、サロゲートペア文字などは2つのUnicodeの組み合わせであることから、バリデーションチェックでは少し厄介な存在です。*2
Webアプリエンジニアをしていく中で、バリデーションチェックとは切っても切れない関係なので、ここで基本的な知識を身につけられて良かったです。
Unicodeには、これからも増え続ける文字に頑張って対応していただきたいなと思います!
*1:どうやら異体字セレクタが重複して登録されているようなので、 [U+E0100] でも同様の文字が表現できます
*2:ちなみにお気づきの方もいると思いますが、異体字セレクタはセレクタ自身がサロゲートペアになっています。ややこしい……
Webアプリケーションエンジニア
緑が好き💚