小西秀和です。
以下の記事で示したように、様々な画像理解モデルと画像生成モデルの組み合わせを使って、生成された画像がプロンプトの内容を正確に反映しているかを検証する実験を行ってきました。
- 理解モデルAmazon Nova Proで画像生成を検証・再試行する(Amazon Nova Canvas編)
- Amazon BedrockでClaude 3.5 Sonnetの画像理解・分析機能を使用して画像生成を検証・再生成・自動化する(Amazon Titan Image Generator G1編)
- Claude 3.5 SonnetでStable Diffusion XLによる画像生成を要件が満たされるまで繰り返すAmazon Bedrockの使用例
本記事では、Anthropic Claude 3.7 Sonnetの画像理解・分析機能を活用して、Stability AI Stable Diffusion 3.5 Large(SD3.5 Large)で生成した画像を検証・再生成するAmazon Bedrockの使用例をご紹介します。
前述の記事同様、この試みも生成画像の要件充足を自動的に判定することで、人間による目視確認作業の軽減を目指しています。
※本記事および当執筆者のその他の記事で掲載されているソースコードは自主研究活動の一環として作成したものであり、動作を保証するものではありません。使用する場合は自己責任でお願いいたします。また、予告なく修正することもありますのでご了承ください。
※本記事執筆にあたっては個人でユーザー登録したAWSアカウント上でAWSサービスを使用しています。
※本記事執筆にあたって使用したAmazon Bedrockの各Modelは2025-03-01(JST)に実行し、その時点における次のEnd user license agreement (EULA)に基づいています。
Anthropic Claude 3.7 Sonnet(Model ID: anthropic.claude-3-7-sonnet-20250219-v1:0, Cross-region inference: us.anthropic.claude-3-7-sonnet-20250219-v1:0): Anthropic on Bedrock - Commercial Terms of Service (Effective: September 17, 2024)
Stability AI Stable Diffusion 3.5 Large(stability.sd3-5-large-v1:0): STABILITY AMAZON BEDROCK END USER LICENSE AGREEMENT(Last Updated: April 29, 2024)
構成図と処理フロー
今回のテーマを実現する構成図は次のようになります。
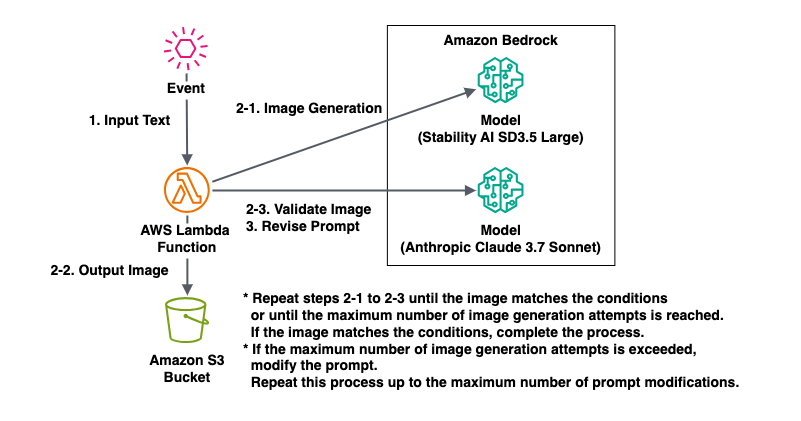
この処理フローについて詳細を説明します。
1. プロンプトやパラメータを含むイベントを入力します。 2-1. 入力した画像作成を指示するプロンプトでAmazon BedrockでSD3.5 Largeモデルを実行します。 * SD3.5 Largeはプロンプトに日本語をサポートしていないため、最初の日本語プロンプトでの実行ではエラーとなり画像生成されず、プログラム内ではこのプロセスはスキップされます。 2-2. 生成された画像をAmazon S3に保存します。 2-3. Amazon S3に保存された画像に対してAmazon BedrockでClaude 3.7 Sonnetモデルを実行し、画像作成を指示したプロンプトの要件にふさわしいかを検証します。 * 画像作成を指示したプロンプトの要件にふさわしいと判断されなければ、`2-1.`から`2-3.`の処理を指定した同一プロンプト実行回数だけ繰り返します。 * 画像作成を指示したプロンプトの要件にふさわしいと判断されれば、その画像を出力結果とします。 3. 修正プロンプト実行回数を超えておらず、画像作成を指示したプロンプトの要件にふさわしいと判断されない回数が同一プロンプト実行回数を超えた場合、Amazon BedrockでClaude 3.7 Sonnetモデルを実行し、画像作成を指示するプロンプトを要件が満たされる可能性が高いものに修正します。この新しい画像作成を指示するプロンプトで`2-1.`から処理をやり直します。 * 修正プロンプト実行回数を超えた場合、エラーとして処理を終了します。
この処理フローでポイントとなるのはClaude 3.7 Sonnetモデルによる画像作成を指示するプロンプトの修正です。
画像作成を指示するプロンプトがAIにとって理解しやすいものであれば、要件を満たす画像は何回か実行すれば出力される可能性が高いでしょう。
ただ、画像作成を指示するプロンプトがAIにとって理解しにくいものであれば、要件を満たす画像の出力がされない事も考えられます。
そのため、指定した同一プロンプト実行回数を超えた場合には、Amazon BedrockでClaude 3.7 Sonnetモデルを実行し、画像作成を指示するプロンプトを最適化したものに修正する処理を入れました。
実装例
入力するイベントのフォーマット
{ "prompt": "[画像生成のための初期プロンプト]", "max_retry_attempts": [各プロンプトで画像生成を試行する最大回数], "max_prompt_revisions": [プロンプトを修正する最大回数], "output_s3_bucket_name": "[生成された画像を保存するS3バケットの名前]", "output_s3_key_prefix": "[生成された画像のS3キーのプレフィックス]", "claude_validate_model_id": "[画像検証時のClaudeモデルのModel IDまたはCross-region inference]", "claude_validate_temperature": [画像検証時のClaudeモデルのtemperatureパラメータ(0.0~1.0)], "claude_validate_top_p": [画像検証時のClaudeモデルのtop-pパラメータ(0.0~1.0)], "claude_validate_top_k": [画像検証時のClaudeモデルのtop-kパラメータ], "claude_validate_max_tokens": [画像検証時のClaudeモデルが生成する最大トークン数], "claude_revise_model_id": "[プロンプト修正時のClaudeモデルのModel IDまたはCross-region inference]", "claude_revise_temperature": [プロンプト修正時のClaudeモデルのtemperatureパラメータ(0.0~1.0)], "claude_revise_top_p": [プロンプト修正時のClaudeモデルのtop-pパラメータ(0.0~1.0)], "claude_revise_top_k": [プロンプト修正時のClaudeモデルのtop-kパラメータ], "claude_revise_max_tokens": [プロンプト修正時のClaudeモデルが生成する最大トークン数], "sd_model_id": "[Stable Diffusion 3.5 LargeモデルのModel ID]", "sd_aspect_ratio": "[Stable Diffusion 3.5 Largeモデルで生成する画像のアスペクト比]", "sd_output_format": "[Stable Diffusion 3.5 Largeモデルの出力画像フォーマット]", "sd_seed": "[Stable Diffusion 3.5 Largeモデルで使用する乱数シード値(再現性のため、指定しない場合はランダム)]" }
入力するイベントの例
{ "prompt": "A serene landscape with mountains and a lake", "max_retry_attempts": 5, "max_prompt_revisions": 5, "output_s3_bucket_name": "your-output-bucket-name", "output_s3_key_prefix": "generated-images", "claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", "claude_validate_temperature": 1.0, "claude_validate_top_p": 0.999, "claude_validate_top_k": 250, "claude_validate_max_tokens": 64000, "claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", "claude_revise_temperature": 1.0, "claude_revise_top_p": 0.999, "claude_revise_top_k": 250, "claude_revise_max_tokens": 64000, "sd_model_id": "stability.sd3-5-large-v1:0", "sd_aspect_ratio": "1:1", "sd_output_format": "png", "sd_seed": 0 }
ソースコード
今回実装したソースコードは次のようになります。
# #Event Sample # { # "prompt": "A serene landscape with mountains and a lake", # "max_retry_attempts": 5, # "max_prompt_revisions": 5, # "output_s3_bucket_name": "your-output-bucket-name", # "output_s3_key_prefix": "generated-images", # "claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", # "claude_validate_temperature": 1.0, # "claude_validate_top_p": 0.999, # "claude_validate_top_k": 250, # "claude_validate_max_tokens": 64000, # "claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", # "claude_revise_temperature": 1.0, # "claude_revise_top_p": 0.999, # "claude_revise_top_k": 250, # "claude_revise_max_tokens": 64000, # "sd_model_id": "stability.sd3-5-large-v1:0", # "sd_aspect_ratio": "1:1", # "sd_output_format": "png", # "sd_seed": 0 # } import boto3 import json import base64 import os import sys import logging from io import BytesIO import datetime import random logger = logging.getLogger() logger.setLevel(logging.INFO) if not logger.handlers: handler = logging.StreamHandler(sys.stdout) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) logger.addHandler(handler) region = os.environ.get('AWS_REGION') bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region) s3_client = boto3.client('s3', region_name=region) def claude3_invoke_model(input_prompt, image_media_type=None, image_data_base64=None, model_params={}): logger.info(f"Invoking Claude model: {model_params.get('model_id')}") logger.debug(f"Prompt length: {len(input_prompt)} characters") messages = [ { "role": "user", "content": [ { "type": "text", "text": input_prompt } ] } ] if image_media_type and image_data_base64: logger.debug(f"Including image in prompt with media type: {image_media_type}") messages[0]["content"].insert(0, { "type": "image", "source": { "type": "base64", "media_type": image_media_type, "data": image_data_base64 } }) body = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": model_params.get('max_tokens', 64000), "messages": messages, "temperature": model_params.get('temperature', 1.0), "top_p": model_params.get('top_p', 0.999), "top_k": model_params.get('top_k', 250), "stop_sequences": ["\n\nHuman:"] } try: logger.debug(f"Claude request parameters: temperature={body['temperature']}, top_p={body['top_p']}, top_k={body['top_k']}") response = bedrock_runtime_client.invoke_model( modelId=model_params['model_id'], contentType='application/json', accept='application/json', body=json.dumps(body) ) response_body = json.loads(response.get('body').read()) response_text = response_body["content"][0]["text"] logger.debug(f"Claude response length: {len(response_text)} characters") logger.info("Claude model invocation successful") return response_text except Exception as e: logger.error(f"Error invoking Claude model: {str(e)}") raise def sd_invoke_model(prompt, negative_prompt, model_params={}): logger.info(f"Invoking Stable Diffusion model: {model_params.get('model_id')}") logger.debug(f"Prompt: {prompt}") if negative_prompt: logger.debug(f"Negative prompt: {negative_prompt}") seed = model_params.get('seed', 0) if seed == 0: seed = random.randint(0, 4294967295) logger.info(f"Generated random seed: {seed}") else: logger.info(f"Using provided seed: {seed}") body = { "prompt": prompt, "mode": 'text-to-image', "aspect_ratio": model_params.get('aspect_ratio', '1:1'), "output_format": model_params.get('output_format', 'png'), "seed": seed } if negative_prompt: body['negative_prompt'] = negative_prompt logger.info(f"SD model parameters: {json.dumps(body)}") try: response = bedrock_runtime_client.invoke_model( modelId=model_params['model_id'], contentType="application/json", accept="application/json", body=json.dumps(body) ) response_body = json.loads(response['body'].read()) logger.debug("SD model response received") if 'images' in response_body and response_body['images']: image_data = base64.b64decode(response_body['images'][0]) logger.info(f"Image generated successfully with seed: {seed}") return image_data, None else: error_msg = "Image data was not found in the response." logger.error(error_msg) return None, Exception(error_msg) except Exception as e: logger.error(f"Exception during SD model invocation: {str(e)}") return None, e def save_image_to_s3(image_data, bucket, key): logger.info(f"Saving image to S3: bucket={bucket}, key={key}") try: s3_client.put_object( Bucket=bucket, Key=key, Body=image_data ) logger.info(f"Image saved successfully to S3: s3://{bucket}/{key}") except Exception as e: logger.error(f"Error saving image to S3: {str(e)}") raise def validate_image(image_data, image_format, prompt, claude_validate_params): logger.info("Validating generated image with Claude") image_base64 = base64.b64encode(image_data).decode('utf-8') input_prompt = f"""Does this image match the following prompt? Prompt: {prompt}. Please answer in the following JSON format: {{"result":"<YES or NO>", "reason":"<Reason for your decision>"}} Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure.""" media_type = f"image/{image_format}" logger.debug(f"Image validation media type: {media_type}") validation_result = claude3_invoke_model(input_prompt, media_type, image_base64, claude_validate_params) try: logger.debug(f"Validation raw result: {validation_result}") parsed_result = json.loads(validation_result) if 'result' not in parsed_result: logger.error("Missing 'result' field in validation response") return False is_valid = parsed_result['result'].upper() == 'YES' logger.info(f"Image validation result: {is_valid}") logger.info(f"Validation reason: {parsed_result.get('reason', 'No reason provided')}") return is_valid except json.JSONDecodeError: logger.error(f"Error parsing validation result: {validation_result}") return False def revise_prompt(original_prompt, claude_revise_params): logger.info("Revising prompt with Claude") logger.debug(f"Original prompt: {original_prompt}") input_prompt = f"""Revise the following image generation prompt to optimize it for Stable Diffusion 3.5 Large, incorporating best practices: {original_prompt} Please consider the following guidelines in your revision: 1. Use natural language descriptions - SD3.5 excels with conversational prompts. 2. Structure the prompt with key elements in this order if applicable: - Style (illustration, painting medium, photography style) - Subject and action (focus on subject first, then any actions) - Composition and framing (close-up, wide-angle, etc.) - Lighting and color (backlight, rim light, dynamic shadows, etc.) - Technical parameters (bird's eye view, fish-eye lens, etc.) 3. For text in images, enclose desired text in "double quotes" and keep it short. 4. Consider including negative prompts to filter out unwanted elements. 5. Be specific with descriptive adjectives and clear nouns. 6. Mention specific artists or art styles if relevant for the desired aesthetic. 7. If the original prompt is not in English, translate it to English. Your goal is to create a clear, natural language prompt that will result in a high-quality image with Stable Diffusion 3.5 Large. Please provide your response in the following JSON format: {{"revised_prompt":"<Revised Prompt>", "negative_prompt":"<Optional Negative Prompt>"}} Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure.""" revised_prompt_json = claude3_invoke_model(input_prompt, model_params=claude_revise_params) logger.debug(f"Revised prompt JSON response: {revised_prompt_json.strip()}") try: parsed_result = json.loads(revised_prompt_json) revised_prompt = parsed_result['revised_prompt'] negative_prompt = parsed_result.get('negative_prompt', '') logger.info(f"Prompt revised successfully") logger.debug(f"Revised prompt: {revised_prompt}") if negative_prompt: logger.debug(f"Negative prompt: {negative_prompt}") return revised_prompt, negative_prompt except json.JSONDecodeError: logger.error(f"Error parsing revised prompt result: {revised_prompt_json}") return original_prompt, "" def lambda_handler(event, context): logger.info("Lambda function started") logger.debug(f"Event: {json.dumps(event)}") try: initial_prompt = event['prompt'] prompt = initial_prompt max_retry_attempts = max(0, event.get('max_retry_attempts', 5) - 1) max_prompt_revisions = max(0, event.get('max_prompt_revisions', 3) - 1) output_s3_bucket_name = event['output_s3_bucket_name'] output_s3_key_prefix = event.get('output_s3_key_prefix', 'generated-images') logger.info(f"Initial prompt: {initial_prompt}") logger.info(f"Max retry attempts: {max_retry_attempts}") logger.info(f"Max prompt revisions: {max_prompt_revisions}") logger.info(f"Output S3 bucket: {output_s3_bucket_name}") logger.info(f"Output S3 key prefix: {output_s3_key_prefix}") # Model parameters claude_validate_params = { "model_id": event.get('claude_validate_model_id', 'us.anthropic.claude-3-7-sonnet-20250219-v1:0'), 'temperature': event.get('claude_validate_temperature', 1.0), 'top_p': event.get('claude_validate_top_p', 0.999), 'top_k': event.get('claude_validate_top_k', 250), 'max_tokens': event.get('claude_validate_max_tokens', 64000) } claude_revise_params = { "model_id": event.get('claude_revise_model_id', 'us.anthropic.claude-3-7-sonnet-20250219-v1:0'), 'temperature': event.get('claude_revise_temperature', 1.0), 'top_p': event.get('claude_revise_top_p', 0.999), 'top_k': event.get('claude_revise_top_k', 250), 'max_tokens': event.get('claude_revise_max_tokens', 64000) } sd_params = { "model_id": event.get('sd_model_id', 'stability.sd3-5-large-v1:0'), "aspect_ratio": event.get('sd_aspect_ratio', '1:1'), "output_format": event.get('sd_output_format', 'png'), "seed": event.get('sd_seed', 0) } logger.debug(f"Claude validate params: {json.dumps(claude_validate_params)}") logger.debug(f"Claude revise params: {json.dumps(claude_revise_params)}") logger.debug(f"SD params: {json.dumps(sd_params)}") # Generate start timestamp and S3 key start_timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S") negative_prompt = "" for revision in range(max_prompt_revisions + 1): logger.info(f"Starting revision {revision}/{max_prompt_revisions}") for attempt in range(max_retry_attempts + 1): logger.info(f"Starting attempt {attempt}/{max_retry_attempts} for generating image") # Generate image with SD3.5 Large image_data, error = sd_invoke_model(prompt, negative_prompt, sd_params) # Skip image save and validation if there's an error if error is not None: logger.error(f"Error generating image: {str(error)}") # If we've reached max attempts for this revision, break to try a revised prompt if attempt == max_retry_attempts: logger.info("Max attempts reached for this revision, moving to next revision") break else: logger.info("Retrying image generation") continue image_format = sd_params["output_format"] image_key = f"{output_s3_key_prefix}-{start_timestamp}-{revision:03d}-{attempt:03d}.{image_format}" logger.debug(f"Generated image key: {image_key}") # Save image to S3 save_image_to_s3(image_data, output_s3_bucket_name, image_key) # Validate image with Claude is_valid = validate_image(image_data, image_format, prompt, claude_validate_params) if is_valid: logger.info("Valid image generated successfully") response = { 'statusCode': 200, 'body': json.dumps({ 'status': 'SUCCESS', 'message': 'Image generated successfully', 'output_s3_bucket_url': f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}', 'output_s3_object_url': f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&prefix={image_key}' }) } logger.debug(f"Lambda response: {json.dumps(response)}") return response # If max retry attempts reached and not the last revision, revise prompt if revision < max_prompt_revisions: logger.info("Revising prompt for next revision") prompt, negative_prompt = revise_prompt(initial_prompt, claude_revise_params) logger.warning("Failed to generate a valid image after all attempts and revisions") response = { 'statusCode': 400, 'body': json.dumps({ 'status': 'FAIL', 'error': 'Failed to generate a valid image after all attempts and revisions' }) } logger.debug(f"Lambda response: {json.dumps(response)}") return response except Exception as ex: logger.error(f'Exception in lambda_handler: {str(ex)}', exc_info=True) tb = sys.exc_info()[2] err_message = f'Exception: {str(ex.with_traceback(tb))}' response = { 'statusCode': 500, 'body': json.dumps({ 'status': 'FAIL', 'error': err_message }) } logger.debug(f"Lambda error response: {json.dumps(response)}") return response
このソースコードでは以下の点を工夫しました。
- 画像生成と検証のサイクルを自動化し、要件を満たすまで繰り返す仕組みを実装
- Claude 3.7 Sonnetを使用して生成された画像の検証とプロンプトの修正を実施
- 高品質な画像生成のためにStable Diffusion 3.5 Largeを使用
- プロンプト修正の指示に画像生成のベストプラクティス(Stable Diffusion 3.5 Prompt Guide)を具体的に盛り込んだ
- 画像生成パラメータ(cfg_scale、steps、width、height、seed)をカスタマイズ可能に設計
- Claude 3.7 Sonnetの呼び出しパラメータ(temperature、top_p、top_k、max_tokens)を調整可能に実装
- 生成された画像を自動的にS3バケットに保存し、結果のURLを返す機能
- 適切なエラーハンドリングとログ出力を実装し、トラブルシューティングを簡略化
- JSONフォーマットを使用してClaudeとの対話を構造化し、結果の解析を容易にした
- 最大リトライ回数と最大プロンプト修正回数を設定可能にし、無限ループを防止
実行内容と結果
実行の一例:入力パラメータ
{ "prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。", "max_retry_attempts": 5, "max_prompt_revisions": 5, "output_s3_bucket_name": "ho2k.com", "output_s3_key_prefix": "generated-images", "claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", "claude_validate_temperature": 1.0, "claude_validate_top_p": 0.999, "claude_validate_top_k": 250, "claude_validate_max_tokens": 64000, "claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", "claude_revise_temperature": 1.0, "claude_revise_top_p": 0.999, "claude_revise_top_k": 250, "claude_revise_max_tokens": 64000, "sd_model_id": "stability.sd3-5-large-v1:0", "sd_aspect_ratio": "1:1", "sd_output_format": "png", "sd_seed": 0 }
今回の実行例の入力パラメータには以下の工夫をしています。
max_retry_attemptsを5に設定して、画像生成の成功率を高めています。max_prompt_revisionsを5に設定しており、必要に応じてプロンプトを改善する機会を増やしています。- Claude modelの画像検証と修正のパラメータ(temperature、top_p、top_k、max_tokens)を細かく設定しています。
- 画像生成に使用する
sd_seedがランダムに設定され、毎回異なる画像が生成されるようにしています。
実行の一例:結果
生成された画像
今回の試行において、最終的にプロンプトの要件を満たして検証をパスした画像は以下です。
この画像は実際に「自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。」という要件をほぼすべて満たしています。
(流星群と言えるほど多くの流星はなく、月はやや小さく描かれていますが、流氷とオーロラははっきりと表現され、月と地平線から昇る太陽という矛盾した情景もしっかりと表現されています。)
また、以前に生成された他の画像(「生成された画像一覧」参照)と比較しても、検証をパスした最終画像がより多くの指定要件を満たしていることを確認できました。

上記の画像は、Claude 3.7 Sonnetによる画像検証プロセスで以下のように評価されました。
[画像検証の結果と理由]
結果: 合格
理由: The image perfectly matches the prompt, showing an Arctic night landscape with floating ice floes on water, a vibrant aurora borealis with purple and green waves in the sky, visible shooting stars, and what appears to be a low sun/light on the horizon. The scene is captured in high detail with natural lighting, showing a pristine wilderness with no human structures. The starry night sky, dramatic auroras, and frozen seascape create exactly the breathtaking nature photograph described in the prompt.
以下は、この試行実行で生成された画像の一覧です。
この「生成された画像一覧」の各行の画像は、それぞれ異なる修正プロンプトから生成されたものです。
SD3.5 Largeはプロンプトに日本語をサポートしていないため、最初の日本語プロンプトでの実行ではエラーとなり画像生成されず、実際の画像生成は、1回目のプロンプト修正以降になります。
1回目のプロンプト修正以降の出力画像は要件に近づいています。

修正されたプロンプトの変化
「生成された画像一覧」の各行の画像は、異なる修正プロンプトから生成されています。
具体的には、SD3.5 Largeはプロンプトに日本語をサポートしていないため、最初の日本語プロンプトでの実行ではエラーとなり画像生成されず、実際の画像生成は、1回目のプロンプト修正以降になります。
そのため、「生成された画像一覧」の1行目の画像は以下の「修正1回目」のプロンプトから生成され、最後の行の画像は「修正3回目」のプロンプトから生成されています。
今回は、初期プロンプトの修正と同時にネガティブプロンプトも生成し、SD3.5 Largeに渡しています。
プロンプト修正回数ごとの修正された画像生成プロンプトとネガティブプロンプトの変化を見てみましょう。
修正0回目
{
"prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。"
}
- SD3.5 Largeはプロンプトに日本語をサポートしていないため、最初の日本語プロンプトでの実行ではエラーとなり画像生成されず、プログラム内ではこのプロセスはスキップされます。
修正1回目
{
"prompt": "Create a breathtaking nature landscape photograph showing the magnificent northern lights (aurora borealis) dancing across the night sky, accompanied by a crescent moon and a meteor shower. Below, an arctic sea stretches to the horizon with floating ice floes gently drifting on the water. In the distance, the sun is just beginning to rise over the horizon, creating a dramatic contrast between night and day. Wide-angle composition capturing both the expansive sky and reflective ocean surface. Cinematic lighting with the auroras casting ethereal green and purple reflections on the water and ice.",
"negative_prompt": "people, humans, text, watermark, signature, blurry, distorted, low resolution, oversaturated, unrealistic lighting, cartoon style"
}
修正2回目
{
"prompt": "A breathtaking natural landscape photograph at night captured from a shoreline perspective. In the sky, vibrant aurora borealis waves dance alongside a bright crescent moon and a spectacular meteor shower with multiple shooting stars. Below, a vast ocean stretches to the horizon with floating ice floes scattered across the dark water. At the horizon line, the first rays of sunrise emerge, creating a beautiful contrast between night and dawn. The scene is completely devoid of people or man-made structures, showcasing pure wilderness.",
"negative_prompt": "people, buildings, structures, text, watermark, blurry, distorted, low quality, grainy, oversaturated"
}
修正3回目
{
"prompt": "A breathtaking nature photograph capturing the Arctic night landscape. A wide-angle composition showing the horizon where a low sun is just beginning to rise, casting golden light across a vast frozen sea filled with floating ice floes. In the dramatic night sky above, a vibrant aurora borealis dances in waves of green and purple, while a bright crescent moon illuminates the scene. Several shooting stars streak across the starry sky. The perspective is from a high vantage point overlooking the pristine wilderness, with no human presence or structures visible. Ultra-detailed 8K photography with crisp focus and natural lighting.",
"negative_prompt": "people, buildings, structures, ships, boats, text, watermarks, blurry, noisy, low quality, artifacts, oversaturation, unnatural colors, lens flare"
}
SD3.5 Largeはプロンプトに日本語をサポートしていないため、最初の日本語プロンプトでの実行ではエラーとなり、画像は生成されず、プログラム内でこのプロセスはスキップされています。
しかし、「生成された画像一覧」と修正されたプロンプトを見ると、Claude 3.7 Sonnetがプロンプトを画像生成に最適化し、1回目のプロンプト修正後には要件に近い画像が出力されていることがわかります。
このように、プロンプト修正と生成実行ごとに画像が変化し、最終的にプロンプトの要件を満たす画像が検証をパスしました。
<参考資料>
AWS Documentation(Amazon Bedrock)
Stable Diffusion 3.5 Prompt Guide
Using Claude 3.7 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Stable Diffusion 3.5 Large
Amazon Bedrock AgentCore Beginner's Guide - AI Agent Development from Basics with Detailed Term Explanations
Tech Blog with related articles referenced
まとめ
本記事では、Anthropic Claude 3.7 Sonnetの画像認識機能を活用して、Stability AI Stable Diffusion 3.5 Large(SD3.5 Large)で生成した画像を検証し、要件を満たすまで再生成する Amazon Bedrockの使用例を紹介しました。
この実験結果から、Claude 3.7 Sonnetの画像認識機能がOCRだけでなく、画像に描かれている内容や表現を認識し、要件充足の検証に活用できることが示されました。また、Claude 3.7 Sonnetがプロンプト自体の内容を修正・最適化できることも確認できました。さらに、Claude 3.7 Sonnetの画像認識機能とプロンプト修正機能はClaude 3.5 Sonnet(v2)よりも高速に実行されることも確認できました。
最も重要な点として、これらの機能を使用して生成画像の要件充足を自動的に判定することで、人間による目視確認作業を大幅に軽減できました。Claude 3.7 Sonnetの画像認識機能と高度なテキスト編集能力により、今回の例のように他の画像生成AIモデルを制御するなど、これまで自動化が難しかったプロセスへの応用可能性が広がりました。
今後も、Anthropic Claudeモデルをはじめとする Amazon BedrockがサポートするAIモデルの更新や実装方法、他サービスとの組み合わせについて引き続き注目していきます。
- [English Edition] Using Claude 3.7 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Stable Diffusion 3.5 Large

