re:Invent 2021盛り上がっていますね!自分も推しのセッションを視聴したので、内容をまとめておきます。
セッション概要
原題:[ARC201] Reliable scalability: How Amazon.com scales in the cloud
Amazon.com(AWSではない)の事例セッションです。Amazon.comがクラウドを活用してどう成長、スケールしてきたのか、実例に基づいて説明してくれるセッションです。
もともとはモノリシックなアーキテクチャだったAmazon.comが、現在のマイクロサービスにどう変わっていったのかという部分も紹介されています。
AWSを使う側としては参考になること間違いナシですね。
内容
Amazon.comの始まり
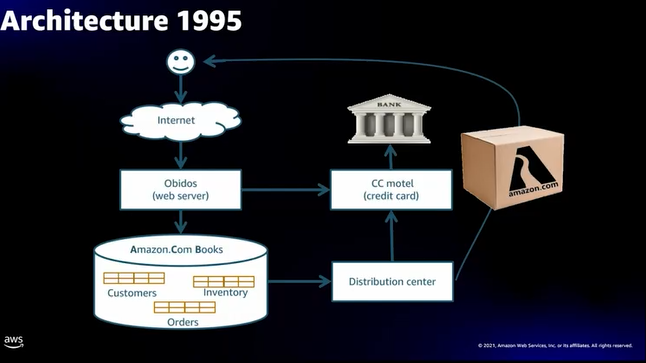
- 1995年にオンライン本屋として始まったAmazon.com

- 当初はObidosと呼ばれるモノリシックなWEBサーバと、1つのデータベースという構成だった
- 配送センターも一つ
- CC motelという仕組みでクレジットカード情報を処理、処理後はカード情報が見れないようにしていた
Scalability(拡張性)
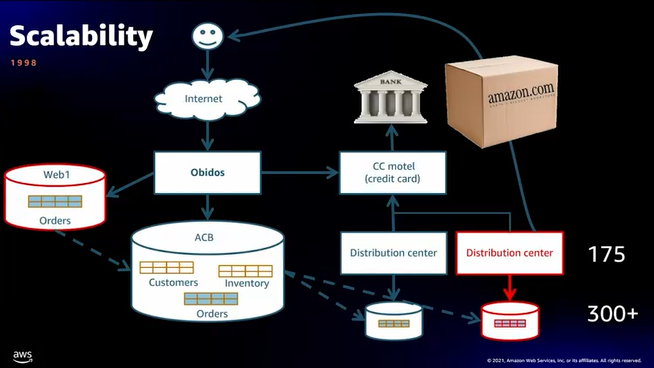
- Scalabilityとは、処理量(load)やscopeが変わった際に、ワークロードが要求された処理を実行できる能力

- WEBシステムの場合、Scalabilityで一番気にするところはどこでしょうか?Yes、データベースです!
- まずはOrdersテーブルを分離(オーダーがたくさん来る)
- 配送センターも増え、センターごとにDBを管理、その後175の配送センター、300以上のデータベースに拡張
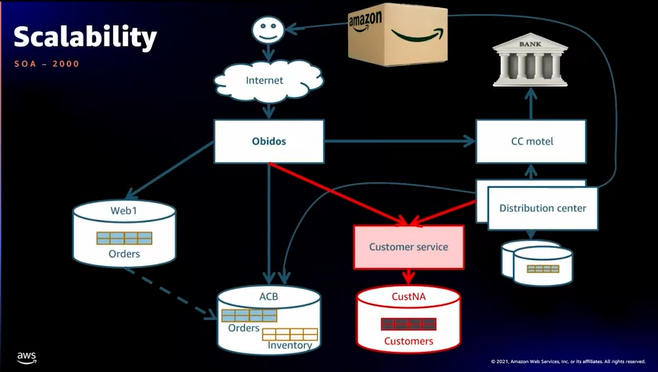
- 次のスケール対象は?Yes、 アプリケーションです!
- 顧客会員登録の機能をまず分離、データベース顧客管理専用に配置
- データベースは地域ごとに管理、図の例ではNorth America(NA)
- これがAmazon.comのService Oriented Architecture(SOA)
- 2021年現在、利用量がものすごく増えている
- 1億7500万個の購入、112億ドルの売上
- リクエスト量も大量
- これらのスケールに対応するには?


- 現在はマイクロサービスアーキテクチャを使用
- この図はイメージではなく、実際のAmazon.comのアーキテクチャー(すごいですね・・)
- 1つのマイクロサービスにフォーカスすると、他の400以上のマイクロサービスに接続されていることがわかる(右側の図)

Reliability(信頼性)
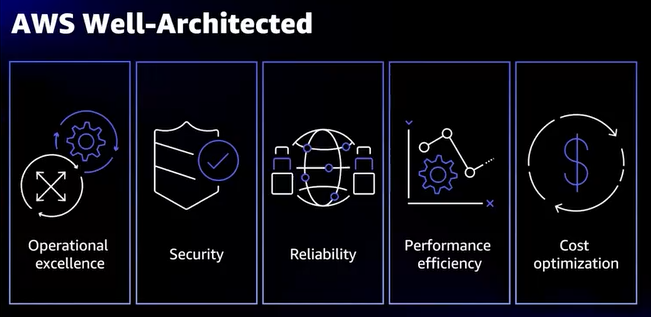
- Reliabilityとは、ワークロードが要求された処理を一貫して正確に実行できる能力

- Reliability Well-Architectedの柱の一つ
- このセッションではReliabilityとOperational excellenceの一部としてScalabilityにフォーカス
Service-oriented と microservices architecture
- 3種のアーキテクチャ紹介
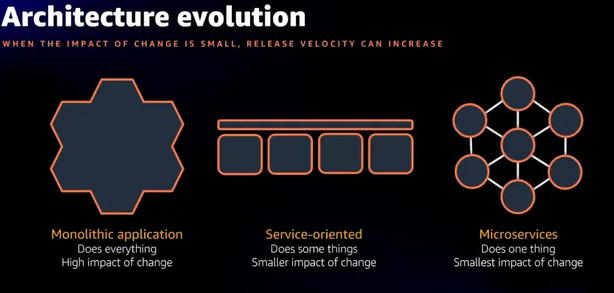
- Amazonでは1億5000万回/年のデプロイ
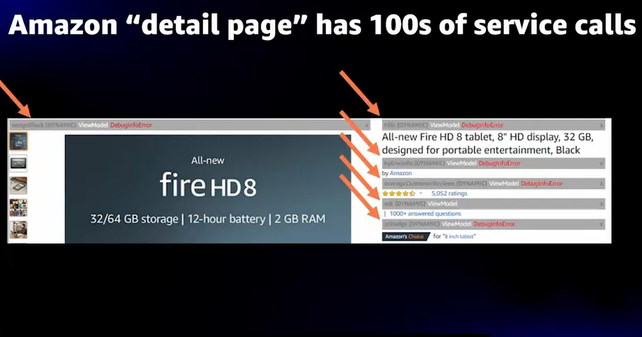
- 一例としてAmazon購入ページ、1画面の中に何百ものマイクロサービスがある

- 1サービスの例、シンプルなアーキテクチャ
- 3人のエンジニアで開発、管理されている
- マイクロより小さい"ナノサービス"

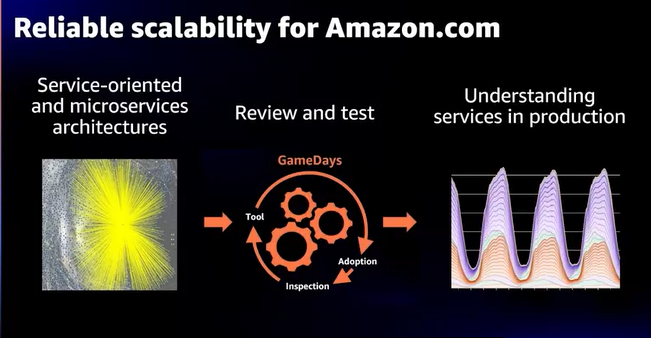
Review and test
- 善意を求めている場合、それは変更(Change)を求めていない、人々はすでに善意を持っているので
- ほとんどの人は善意と尽くしているし、できる限り最適化された状態でシステムを構築している
- 変更を行う場合は実際のアーキテクチャを検討し、指標を明確にしゴールに向かわないといけない。定期的なチェックも必要

- すべてのコードに対し、複数名でレビューを実施
- 本番リリース前に承認し、レビュアーは変更品質(本番での成功)の説明責任を持つ

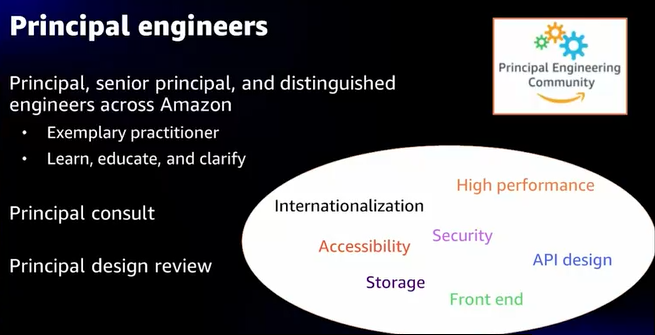
- AmazonにはPrincipal Engineerという、各分野のスペシャリストがいる
- プロジェクト序盤の内容やアーキテクチャのレビューを行っている
- 次はテストの話
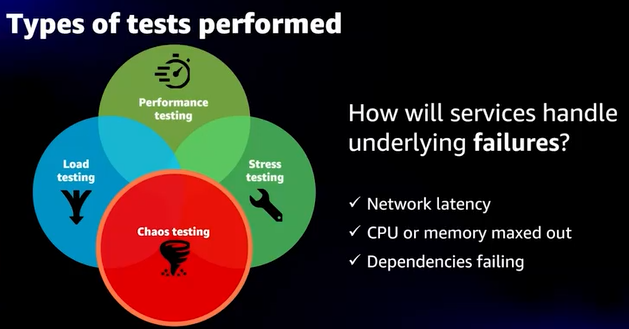
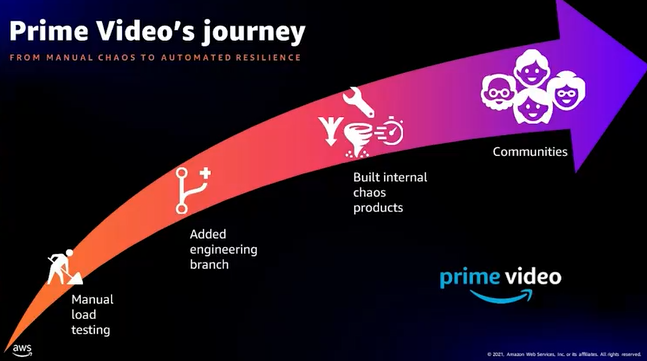
- Prime Videoのテスト事例
- 4種のテストを実施、W-A Toolにも質問事項としてある

- 左側はサッカーの試合、熱戦だったため、SNS上で話題になり、サインアップ急増
- 右側はTV番組、盛り上がって視聴者急増
- どちらも想定していなかったスパイク(青矢印部分)
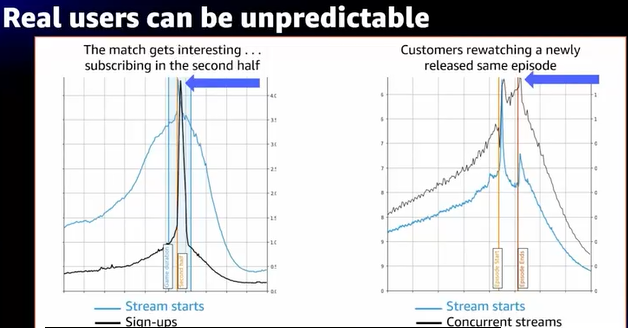
- このような経験を学習してメカニズムに入れていく
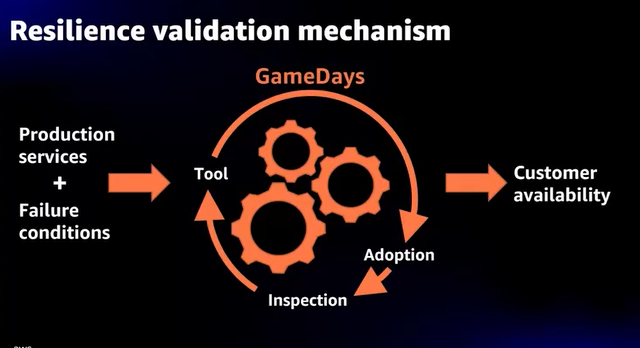
- マイクロサービス構造なので、1サービスの変更、テストが他チームの機能にも影響を与える
- 影響を与える場合は事前にそのチームに知らせる必要がある
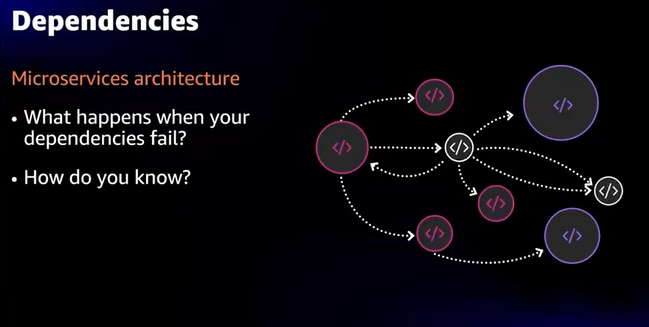
- ただの障害テストだけでなく、障害発生後どう復旧するのかまでテストする
- Circuit-breakerを使用して、1サービスの影響を最小限にするという手法もある
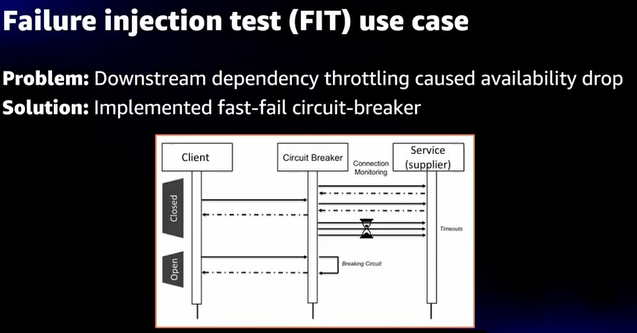
- 先ほどの視聴者急増などのイベントに対応する必要がある

- Prime Videoのテスト手法、ツールはコミュニティにより成長してきた
Understanding services in production
- Amazonでは定期的にレビューを行っている、メトリクス状況、技術観点、顧客課題などを議論
- 各サービスのリーダーが集まり、成功事例、課題のシェアをおこなっている
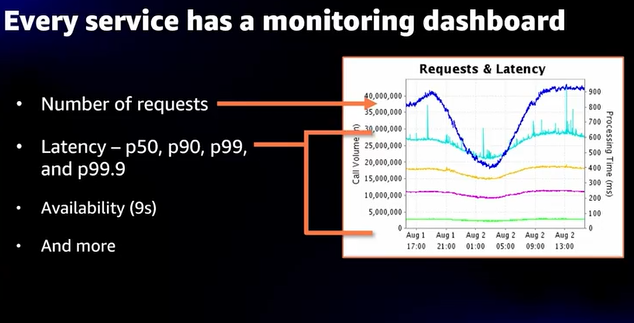
- 各サービスチームがメトリクスダッシュボードを管理し、シェアできるようにしている
- レイテンシーや信頼性を管理
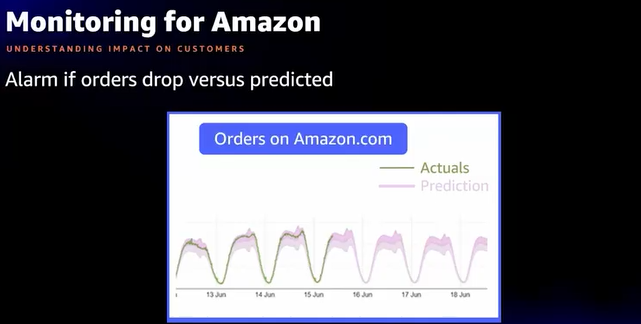
- Amazon.comではオーダー(注文)の減少を検知できるようにしている
- 時間による増減があるため、予測を使ってその比較を監視
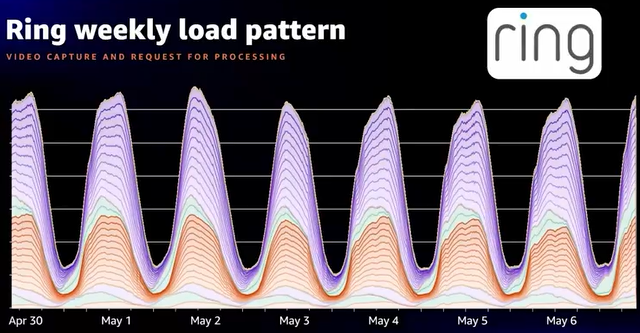
- Ringの事例
- オーダー同様、日中と夜間で使用数の差がある
- このメトリクスを使ってインスタンスタイプ(リザーブドなど)を決め、コスト最適化している
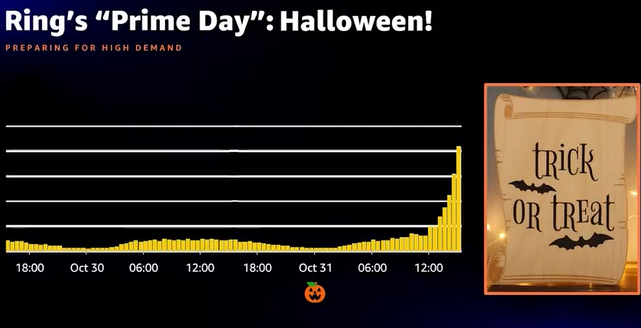
- ハロウィーンで使用量急増、予測可能で、AWSであれば容易に対処できる
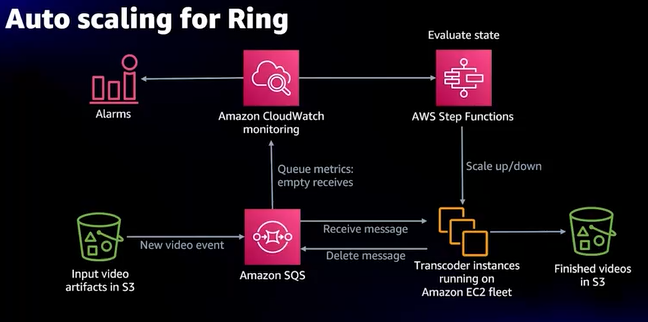
- Ringのアーキテクチャ
- SQSのキュー状況をCloudWatchで監視し、Step FunctionsでEC2増減
- W-Aにもあるよう、スケーリングの自動化を実現している
Going global
- AWSのネットワーク構成紹介、リージョン、AZ
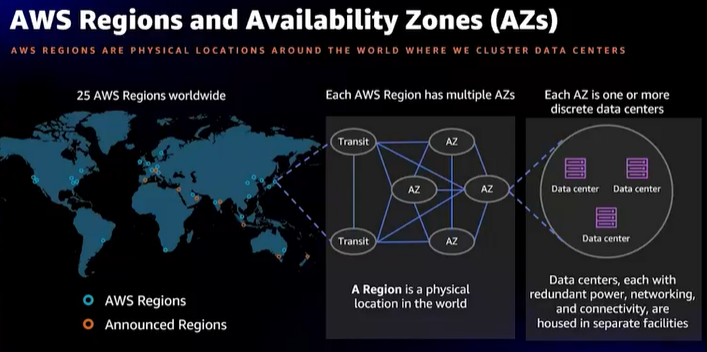
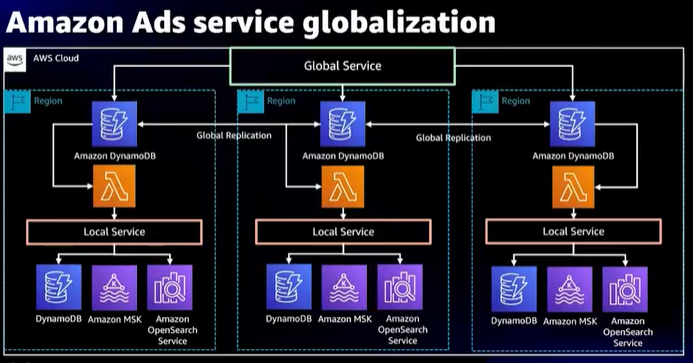
- Amazon adsの事例
- 各国それぞれで広告を表示する必要があった
- DynamoDBを使用してこの課題を解決

- adsのアーキテクチャ
- DynamoDB global tableを使用して、各リージョンに同じ構造のDynamoDBを配置
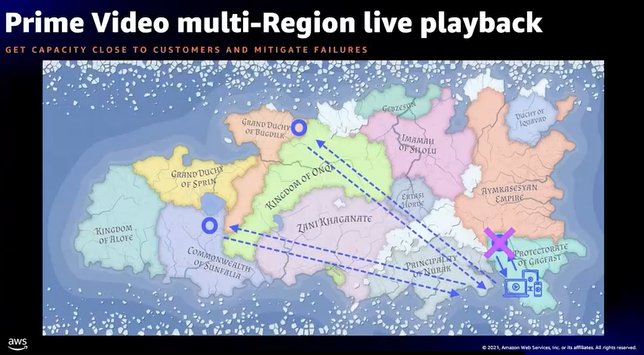
- Prime Videoの事例
- 各リージョンにサービスを配置することによって、レイテンシーを削減
- フェイルオーバー機能を他リージョン持たせることで可用性もUP
セッションまとめ
- サービス指向アーキテクチャとマイクロサービスアーキテクチャ
- レビューとテストの繰り返し
- サービスの状況を理解する
- Well-Architected Frameworkも要チェック!
所感
モノリシックなアーキテクチャーから現在のマイクロサービスアーキテクチャへの変遷、システム開発をする我々としてはとても参考になるセッションでした。特に最初はDB、量の多いオーダーテーブルから分離、アプリは会員機能から分離、という流れは具体的で参考になりました。
後半ではWell-Architected Frameworkにも多く触れられており、Well-Architectedレビューを多くやっている私としては参考になる部分が多かったです。本セッションの事例では、Well-Architected Frameworkを参考にしたというものもあれば、Well-Architected Frameworkの各項目が生まれた背景になっている課題も多かったのかなという印象です。
私の現場でもまだまだAWSを活用できる現場があると思うので、頑張っていきたいと思います。
