本記事は
AI・MLウィーク
2日目の記事です。
💻
1日目
▶▶ 本記事 ▶▶
3日目
📱
こんにちは、新人の福井です。
本記事は、私が直近AI 関連のイベントに複数参加した事がきっかけで、AIエージェントとRAGに興味を持ったため、実際にエージェントを構築しながら私なりに咀嚼して整理したものです。
私は現在、社内勉強会の運営メンバーとして活動しており、その活動も早いもので半年が過ぎました。
- Netcomの社内勉強会って?
様々な部署から登壇者を募り、毎週金曜日の18:00~19:00 にナレッジをシェアする会のこと。
対面・オンラインのハイブリッド型で実施しており、当日参加が難しい方は後日アーカイブを見るという手もあります。
活動を続ける中、運営目線で、せっかく部署横断で有益なナレッジが共有されているにもかかわらず、その知見が十分に行き渡っていないという課題を感じていました。そこで今回、「勉強会で生まれたナレッジを、より多くの人に、必要なタイミングですぐに届けたい!」という思いから、Amplify Gen2 × S3 Vectors を用いた社内勉強会エージェントを作ってみました。
従来の生成AI
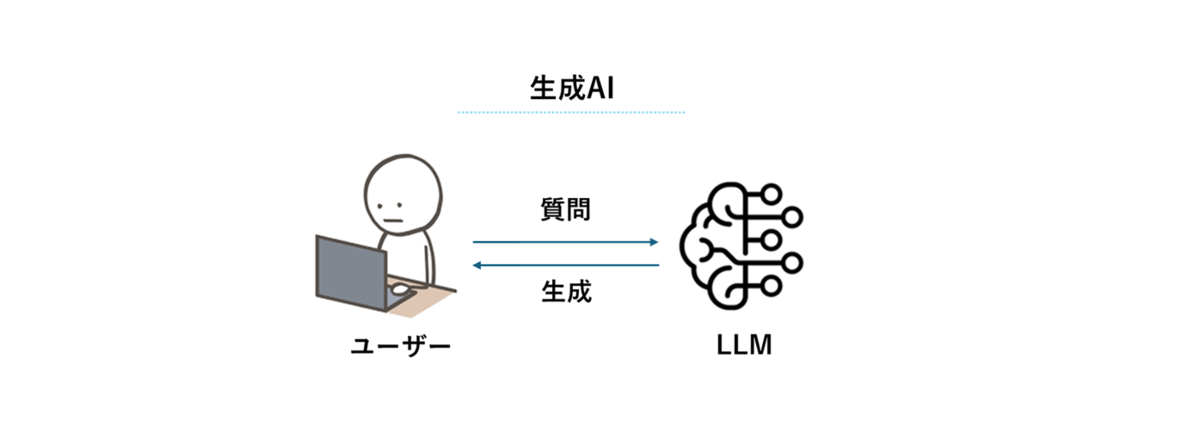
生成AI (≒ LLM)とは、事前に学習したデータをもとに、ユーザーの質問に対して成果物を返す人工知能のことを指します。
通常の LLM は、開発プロセスにおいて「ここまでのデータを使って学習させる」という締め切りを設けて構築されます。この事前学習の最終時点をナレッジカットオフといい、それ以降の情報には正しく回答できません。そのため、LLM が学習していない情報についてユーザーが質問をすると、もっともらしい嘘(ハルシネーション)を生成するリスクがあります。
RAG(検索拡張生成)の仕組み

このLLMの最大の弱点ともいえるハルシネーションを劇的に減らすアプローチとして、RAG(Retrieval-Augmented Generation)という仕組みがあります。RAGとは事前準備済みの外部データベース(ベクトル DB)に必要な情報を検索し、その検索内容に基づいた回答を生成する仕組みです。RAGは、参照した情報源を明確に示すことができ、万が一 AI が間違った解釈をしても、人間がすぐに元データを確認して間違いに気づくことができます。
※注意
情報源を明示できるため、RAG はハルシネーションを防げる万能なアプローチに思えるかもしれませんが、実際は、RAG を用いた場合でもハルシネーションが発生する可能性はあります。その前提を理解した上で設計することが重要です。
Embedding(埋め込み)とVector(ベクトル)
次に LLM は外部 DB 内の大量データの中から、最適なデータをどのように見つけているか仕組みを説明します。
そのためには、埋め込みとベクトルを理解する必要があります。
- 埋め込み

テキストや画像などのデータをLLMが理解できる数字のリストに変換する作業のことを指します。
- ベクトル
変換された後の数字のリストそのものを指します。
各数値が何らかの特徴を表す指標となっています。
RAG においては、この埋め込みとベクトルを最大限に活用し、 LLM が外部 DB 内の大量データの中から、最適なデータを見つけています。
具体的な流れとしては以下の通りです。
事前準備
事前に学習させたい内容を適切な長さに分割(チャンキング)し、AIが理解できる数値に変換(埋め込み)してベクトルDBに格納。ユーザーからの質問に対して検索・抽出
ユーザーからの質問に対しても同様に埋め込みを実施。
埋め込みの結果、ベクトル空間上で意味的に近いドキュメントを高速に検索・抽出が可能に。回答生成
検索によって得られた情報をコンテキストとして LLM に与えることで、モデル自身の推測に頼らない回答生成を実現。
Amazon S3 Vectors
現在、RAGのコンポーネントとしてベクトルデータベースにOpenSearch Serviceを用いる構成が主流ですが、コスト面で課題を抱えていました。
そこで、2025年12月2日に Amazon S3 Vectors という、ベクトルデータの保存と検索をネイティブにサポートする初のクラウドオブジェクトストレージが正式にGAされたことで、コスト面の懸念が解消されました。
S3 Vectors の基本的な機能
ベクトルの保存と追加
ベクトルデータのクエリ
メタデータによるフィルタリング
S3 Vectorsを使った RAG 構成の推しポイント
月額固定費がない
S3の低価格と従量課金が相まって、コストが高いという悩みが解決し個人開発に最適に。「とりあえず全部入れる」が可能
20億ベクトル(数億ドキュメント相当)という巨大な容量をS3価格で維持可能。
そのため、これまで「コストに見合わない」と捨てていた低頻度参照データもすべてRAGの対象に含めることが可能に。
S3 Vectorsを使った RAG 構成の課題
セマンティック検索のみサポート
Kendra はハイブリッド検索が可能な一方で、S3 Vectors ではセマンティック検索のみサポートしています。そのため、従来の RAG 構成より、曖昧な回答が返される可能性があります。検索速度の遅さ
こちらは直接検証していないため、具体的にどの程度遅いかは分かりませんが従来の RAG 構成より遅いそうです。下記のサイトで検索速度について検証されています。
Amazon S3 Vectors によるRAGの性能/精度を評価してみた - Taste of Tech Topics
社内勉強会エージェントを作ってみた
 実際に、S3 Vectors を使って低コストなエージェントを構築しました(☝アーキテクチャ)。
実際に、S3 Vectors を使って低コストなエージェントを構築しました(☝アーキテクチャ)。
流れとしては以下の通りです。
社内勉強会が終了すると、Zoom の Webhook を通じてレコーディング動画が mp4 形式で Amazon S3 に自動保存
保存をトリガーに Amazon Transcribe を実行し、動画を文字起こしした結果を JSON 形式で別の S3 バケットに格納
その後、イベント駆動で Bedrockを呼び出し、文字起こしデータを埋め込みし、S3に保存
Bedrock Agents は、Bedrock KBを介して S3 と同期された S3 Vectors に対して検索を行い、その結果をもとにユーザーへ回答を生成
UI については、AWS Amplify Gen 2 を使って少し派手に作ってみました。
エージェント構築
Amplify Gen2でバックエンドを楽に構築しよう
npm create amplify@latestというAmplify Gen 2プロジェクトを生成するコマンドを実行すると、 認証基盤とフロントエンドから利用可能なデータモデルを定義したTypeScriptコードのひな形を自動作成してくれました。以下は、コマンド実行時に生成されるひな形で、バックエンドの定義はルート直下のamplify フォルダに格納されます。また、amplify/auth/resource.ts ファイルに認証基盤の定義、amplify/data/resource.tsファイルにフロントエンドから利用可能なデータモデルが定義されています。この2つの定義をamplify/backend.tsファイルにインポートし、defineBackend()関数の引数として与えることで、バックエンドリソースとして組み込まれます。 Amplify Gen2の認証基盤としては、 Amazon Cognito が利用され、その設定に基づいて生成されるログイン画面が次の画面になります
amplify/backend.ts
import { defineBackend } from '@aws-amplify/backend'; import { auth } from './auth/resource'; import { data } from './data/resource'; import { PolicyStatement, Effect } from 'aws-cdk-lib/aws-iam';
const backend = defineBackend({
auth,
data,
});
backend.auth.resources.authenticatedUserIamRole.addToPrincipalPolicy(
new PolicyStatement({
effect: Effect.ALLOW,
actions: [
// ナレッジベースを検索して回答を生成する
'bedrock:RetrieveAndGenerate',
'bedrock:Retrieve',
// モデルを呼び出す
'bedrock:InvokeModel',
],
resources: [
// ナレッジベースのARN
`arn:aws:bedrock:us-east-1:123456789012:knowledge-base/xxxxxxx`,
// 使用する基盤モデルのARN
`arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3.5-sonnet-20240620-v1:0`,
],
})
);
amplify/auth/resource.ts
import { defineAuth } from '@aws-amplify/backend';
/**
* Define and configure your auth resource
* @see https://docs.amplify.aws/gen2/build-a-backend/auth
*/
export const auth = defineAuth({
loginWith: {
email: true,
},
});
amplify/data/resource.ts
import { type ClientSchema, a, defineData } from '@aws-amplify/backend';
const schema = a.schema({
Todo: a
.model({
content: a.string(),
})
.authorization((allow) => [allow.guest()]),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: 'identityPool',
},
});
社内勉強会エージェント へまずはログインしよう
ひな形では、デフォルトでdefineAuth()関数内にemailパラメータが指定されているため、メールアドレスでのログインになります。
初回はアカウントを作成する必要があります。
社内勉強会エージェント UI
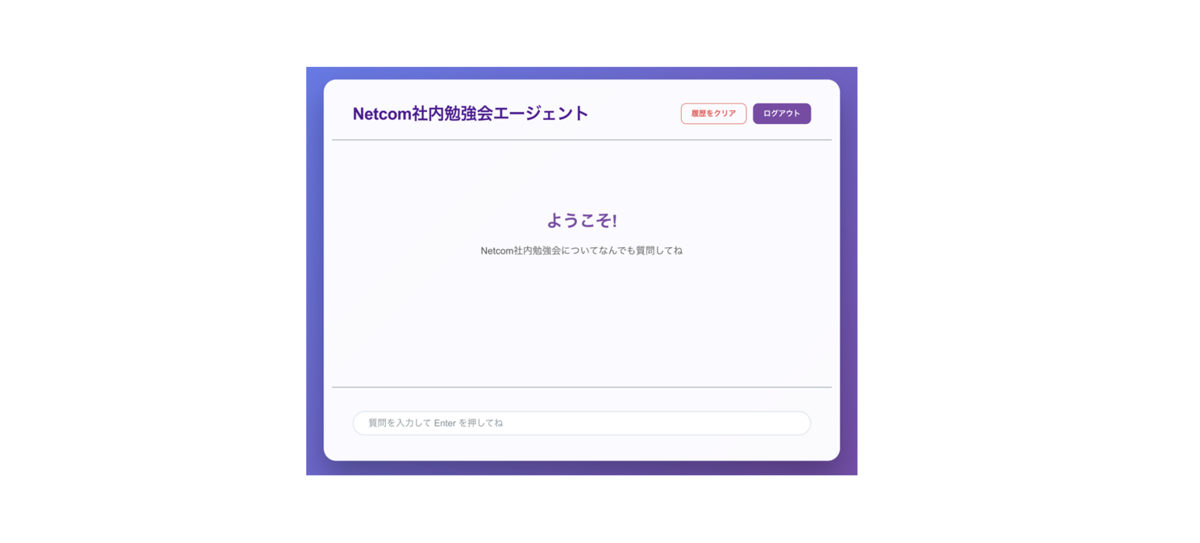
認証が通ると、Netcom 社内勉強会エージェントの UI 画面に遷移します。
普段エージェント開発で UI には、Streamlit を用いていたため、Amplify Gen2 でこの重厚感あふれる UI を作れた時は感動しました。
UI を作る時に意識したこと
AIが回答するまでの待機時間において、ユーザーにストレスを与えないようにする → 「思考中....」 とAI が考えている様子を目に見える形で示す
会話のラリーが増えてきたときに、最新の回答が目に入るようにする → 自動スクロール機能の導入
ソースコード
"use client"; import { useState, useRef, useEffect } from "react"; import { Amplify } from "aws-amplify"; import { Authenticator, Button, Heading, View, Card, TextField, Flex, Text, Divider } from "@aws-amplify/ui-react"; import "@aws-amplify/ui-react/styles.css"; import { fetchAuthSession } from "aws-amplify/auth"; import { BedrockAgentRuntimeClient, RetrieveAndGenerateCommand } from "@aws-sdk/client-bedrock-agent-runtime"; import outputs from "../../amplify_outputs.json"; Amplify.configure(outputs); const KNOWLEDGE_BASE_ID = "xxxxxxxxxxx"; export default function App() { const [input, setInput] = useState(""); const [messages, setMessages] = useState<{role: string, text: string}[]>([]); const [isLoading, setIsLoading] = useState(false); const scrollRef = useRef<HTMLDivElement>(null); const handleClear = () => { setMessages([]); }; useEffect(() => { if (scrollRef.current) { scrollRef.current.scrollTop = scrollRef.current.scrollHeight; } }, [messages, isLoading]); const handleSend = async () => { if (!input.trim() || isLoading) return; const textToSend = input; setMessages(prev => [...prev, { role: "user", text: textToSend }]); setInput(""); setIsLoading(true); try { const session = await fetchAuthSession(); const credentials = session.credentials; if (!credentials) throw new Error("認証失敗"); const client = new BedrockAgentRuntimeClient({ region: "ap-northeast-1", credentials }); const command = new RetrieveAndGenerateCommand({ input: { text: textToSend }, retrieveAndGenerateConfiguration: { type: "KNOWLEDGE_BASE", knowledgeBaseConfiguration: { knowledgeBaseId: KNOWLEDGE_BASE_ID, modelArn: "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0", retrievalConfiguration: { vectorSearchConfiguration: { numberOfResults: 5, }, }, generationConfiguration: { inferenceConfig: { textInferenceConfig: { temperature: 0.5, maxTokens: 2048, } } } } } }); const response = await client.send(command); const aiMsg = { role: "ai", text: response.output?.text || "ナレッジベースから回答が見つかりませんでした。" }; setMessages(prev => [...prev, aiMsg]); } catch (error: any) { console.error(error); setMessages(prev => [...prev, { role: "ai", text: "エラーが発生しました。再度お試しください。" }]); } finally { setIsLoading(false); } }; return ( <Authenticator> {({ signOut }) => ( <View className="App" padding="1rem" style={{ background: "linear-gradient(135deg, #667eea 0%, #764ba2 100%)", minHeight: "100vh", display: "flex", alignItems: "center", justifyContent: "center" }} > <Card variation="elevated" width="100%" maxWidth="1000px" borderRadius="24px" boxShadow="0 30px 60px rgba(0,0,0,0.3)" backgroundColor="rgba(255, 255, 255, 0.97)" style={{ backdropFilter: "blur(20px)" }} > <Flex justifyContent="space-between" alignItems="center" padding="1.8rem 2.5rem"> <Heading level={3} color="#4a148c" fontWeight="900" style={{ letterSpacing: "-0.5px" }}> Netcom社内勉強会エージェント </Heading> <Flex gap="0.8rem" alignItems="center"> <Button onClick={handleClear} variation="outline" size="small" style={{ color: "#d9534f", borderColor: "#d9534f", borderRadius: "10px", fontWeight: "600", fontSize: "0.9rem", padding: "0.5rem 1.2rem" }} > 履歴をクリア </Button> <Button onClick={signOut} variation="primary" size="small" style={{ backgroundColor: "#764ba2", borderColor: "#764ba2", borderRadius: "10px", fontWeight: "600", fontSize: "0.9rem", padding: "0.5rem 1.2rem" }} > ログアウト </Button> </Flex> </Flex> <Divider /> <View ref={scrollRef} height="60vh" overflow="auto" padding="2.5rem" backgroundColor="transparent" > {messages.length === 0 && ( <View textAlign="center" marginTop="10%"> <Text fontSize="2rem" fontWeight="900" color="#764ba2" marginBottom="1rem"> ようこそ! </Text> <Text color="#555" fontSize="1.15rem" lineHeight="1.8"> Netcom社内勉強会についてなんでも質問してね<br /> </Text> </View> )} {messages.map((m, i) => ( <View key={i} marginBottom="2rem" textAlign={m.role === 'user' ? 'right' : 'left'}> <Text display="inline-block" padding="1.2rem 1.8rem" borderRadius={m.role === 'user' ? "24px 24px 4px 24px" : "24px 24px 24px 4px"} fontSize="1.05rem" lineHeight="1.7" backgroundColor={m.role === 'user' ? '#667eea' : '#f0f4f8'} color={m.role === 'user' ? 'white' : '#1e293b'} maxWidth="80%" boxShadow="0 8px 20px rgba(0,0,0,0.06)" > {m.text} </Text> </View> ))} {isLoading && ( <View textAlign="left" marginBottom="1.5rem" paddingLeft="1rem"> <Text color="#764ba2" fontSize="0.95rem" fontWeight="700" className="blink"> AI is thinking... </Text> </View> )} </View> <Divider /> <View padding="2rem 2.5rem"> <TextField placeholder="質問を入力して Enter を押してね" value={input} onChange={(e) => setInput(e.target.value)} width="100%" autoComplete="off" size="large" style={{ borderRadius: "40px", border: "2px solid #e2e8f0", backgroundColor: "#fff", fontSize: "1.1rem", paddingLeft: "1.8rem", boxShadow: "inset 0 2px 4px rgba(0,0,0,0.02)" }} isDisabled={isLoading} onKeyDown={(e) => { if (e.key === 'Enter' && !e.nativeEvent.isComposing) { handleSend(); } }} /> </View> </Card> </View> )} </Authenticator> ); }
実際に質問してみた
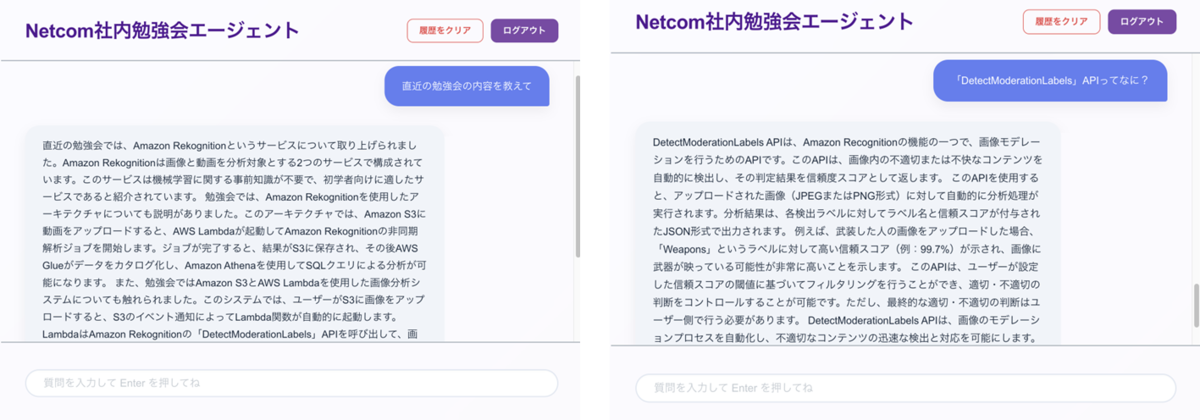 現在ナレッジベースには、二つの勉強会のサンプルデータが入っています。
現在ナレッジベースには、二つの勉強会のサンプルデータが入っています。
2月4日開催の勉強会 「CloudWatch Synthetics が拓くアプリの外形監視」
2月8日開催の勉強会 「ゼロから始める AWS 生活 ~Amazon Rekognition をさわってみた~」
ここで試しに「直近の勉強会の内容を教えて」と質問すると、直近開催された 2月8日開催の勉強会 について説明してくれます。
また、生成された回答の中により詳細に知りたい語句が出てきた際は、追加で質問すると、ナレッジベースにある知識範囲から回答を生成してくれます。
本来、エージェント構築においては外部のツールを利用したり、API を叩くことで回答に幅を持たせるなど多機能にすることができます。
ただ、今回のユースケースは社内勉強会の内容のシェアなので、必要以上に外部から情報を参照し、回答の幅を持たせる必要性はないと思いました。
そのため、今回はツールを利用せず、また誰が質問しても一貫して安定した回答を生成するようデフォルト設定( temperature:0 , TopP:1 , TopK:250 )にしています。
性能評価
Amazon Bedrock Model Evaluationの LLM-as-a-Judge で LLM の性能を評価しよう
LLM の性能を評価する方法はいくつかありますが、今回は Amazon Bedrock Model Evaluation の LLM-as-a-Judge を採用しました。
Amazon Bedrock Model Evaluation とは、Bedrock の LLM の性能を評価する機能のことです。
LLM-as-a-Judge は、自動で LLM 自身に LLM や RAG の出力精度などを判定させるアプローチのことです。
以下のように、RAG 評価用のプロンプトデータセットを用意し、期待した回答に沿っているかを評価します。
プロンプトデータセット(例)
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon Rekognitionのイメージとビデオで、処理方式(同期・非同期)が異なる理由を技術的な観点から説明してください。"}]},"referenceResponses":[{"content":[{"text":"イメージは即時性が求められデータ量が小さいため同期処理ですが、ビデオは容量が大きく解析に時間がかかるため、後から結果を受け取る非同期処理となっています。"}]}]}]} {"conversationTurns":[{"prompt":{"content":[{"text":"長時間動画の解析結果を保存する際、なぜJSONではなくApache Parquet形式が推奨されるのですか?コストと速度の面から答えてください。"}]},"referenceResponses":[{"content":[{"text":"Parquetは列指向構造のため必要なデータのみを読み込め、分析が高速化されます。また、スキャン量が減ることでAthena等のクエリコストを大幅に削減できるメリットがあります。"}]}]}]} {"conversationTurns":[{"prompt":{"content":[{"text":"Lambdaを用いた画像モデレーションの自動化において、Slack通知の設計パターンを3つ挙げてください。"}]},"referenceResponses":[{"content":[{"text":"「不適切ラベル未検出(安全)」「不適切ラベル検知(アラート)」「Lambda実行エラー(システム異常)」の3つの通知パターンが設計されています。"}]}]}]} {"conversationTurns":[{"prompt":{"content":[{"text":"サーバーレスでの長時間動画解析フローにおいて、SNSとGlueはそれぞれどのような役割を担っていますか?"}]},"referenceResponses":[{"content":[{"text":"SNSは非同期解析ジョブの完了通知を発行して次のLambdaを起動する役割、GlueはS3に保存された解析データをカタログ化してクエリ分析可能にする役割を担います。"}]}]}]} {"conversationTurns":[{"prompt":{"content":[{"text":"Rekognitionの信頼スコア(Confidence Score)の閾値をユーザー側で柔軟に変更できるように実装する理由はなぜですか?"}]},"referenceResponses":[{"content":[{"text":"信頼スコアは確率的な値であり、業務要件によって許容できる誤検知率が異なるため、ユーザー側で最終的な判定基準をコントロールできるようにするためです。"}]}]}]}
プロンプトデータセットが用意できたら、RAG の評価を実施します。
RAG Evaluation の設定は以下の通りです。
評価タイプ:Retrival and response generation (検索と生成)
評価モデル:Claude 3.5 Sonnet v2
回答生成モデル:Claude Sonnet 4 v1
評価項目(品質):Correctness(正確性), Completeness(網羅性), Helpfulness(有用性), Faithfulness(忠実性), Citation precision(引用の正確性)
責任ある AI:Harmfulness(有害性), Refusal(応答拒否)
評価結果
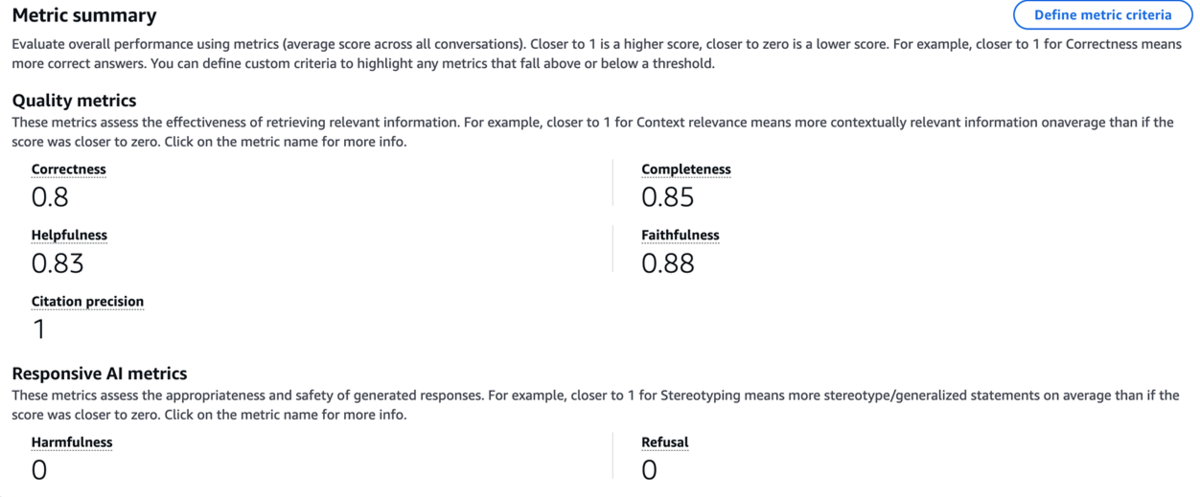 各メトリクスは、0~1で評価されます。
各メトリクスは、0~1で評価されます。
Citation precision : 1
→ 質問に対してピンポイントで正しい資料を特定できているFaithfulness : 0.88 → ハルシネーションが非常に少ない
Correctness : 0.8
→ 今回のナレッジベースのデータが文字起こしデータに由来するもので、LLM が解釈を間違えた可能性がある
現に、評価結果の詳細では、出力が若干抜けていたCompleteness : 0.85
→ 多くの回答が質問の主要な側面を適切にカバーしているHelpfulness : 0.83
→ユーザーの意図をくみ取った回答ができているRefusal : 0
→過剰なガードレールに阻まれることなく、必要な情報を提供できている
一旦、不自由なく使用できる水準まで構築することができましたが、使ってもらうためにはまだまだ改善の余地ありです。
特に文字起こしデータを基に回答しているため、出力の揺らぎをいかに抑えていくかが今後の課題です。
AI エージェント構築はむしろ、ここからがスタートでより安心して安全に利用できるエージェント開発を目指していきたいと思います。
個人的なつまづきポイント
- ナレッジベースからデータを削除後、Bedrock Agents の指示で挙動を縛っているにも関わらず、時折削除したデータに基づいた回答を生成してしまう
Bedrock Agents への指示
あなたは「社内勉強会エージェント」です。 あなたの任務は、S3 上のナレッジベースにあるテキストデータのみをソースとして、ユーザーの質問に正確に回答することです。 以下の【絶対厳守ルール】に従って行動してください: 1. 検索の徹底: ユーザーの質問に対し、必ず「ナレッジベース」を検索してください。 2. 回答のソース制限(最優先): 回答は、ナレッジベースから得られた情報「のみ」で構成してください。 ナレッジベース検索の結果、参照元が1つも得られなかった場合は、他のいかなるガイドラインよりも優先して、即座に『現在の資料の中にはその情報は含まれておりません』とだけ回答してください。 3. 一般知識の禁止: たとえあなたが一般的な知識として答えを知っていたとしても、それを回答に含めることは【厳禁】です。自分の知識で補完したり、推測でアドバイスしたりしないでください。 4. 形式の指定: 回答の最後には、必ず引用したファイル名を明記してください。 5. 余計な会話の禁止: 資料に情報がない場合、ユーザーへの聞き返し、代替案の提示、お詫びの長文などは一切不要です。指定の拒絶文言のみを返してください。
対策:フロントエンド側でガードレールを張る
if "chunk" in event:
# 検索を実行し、参照元が見つからなかった場合、AIの回答を無視して固定メッセージに変換
if kb_lookup_executed and not kb_has_refs:
full_response = force_stop_response
else:
text = event["chunk"]["bytes"].decode("utf-8")
full_response += text
response_placeholder.markdown(full_response + "▌")
システムプロンプトでの指示だけでなく、コードレベルで「根拠が1つでもなければしゃべらせない」という制限を設けることで解決
- Amazon Bedrock モデル評価ジョブで temperature と topPパラメータの両方を同時指定した際に生じたエラー

原因:新しい Claude モデルである Claude Sonnet 4.5 と Claude Haiku 4.5 では、 temperature または topPパラメータのどちらかのみ指定可能。両方同時指定はできない。
最後に
Amplify Gen2 と S3 Vectors を使うことで、コストを気にせず RAG を組み込んだエージェントを構築することができました。 また、Amplify Gen2 は初めて使いましたがバックエンドの構築が楽かつ、sandbox 環境でのリアルタイムでの検証が可能という点が素晴らしいと思いました!今後は作って終わりではなく、LLMOps の方にも力を入れていきたいと思いました! 是非、RAG を構築する際は、S3 Vectors を使ってみてください!

2025年度入社のアプリケーションエンジニア
2026 Japan AWS Jr. Champions
2026 Japan All AWS Certifcations Engineers