こんにちは佐々木です。
前回、データレイクとDWHを分離せよという趣旨の記事を書いていました。今回は、その続きとして、データレイクをRAWデータレイク・中間データレイク・構造化データレイクの3層構造がお勧めですよというお話をします。何の事でしょう?
RAWデータレイク・中間データレイク・構造化データレイクの役割
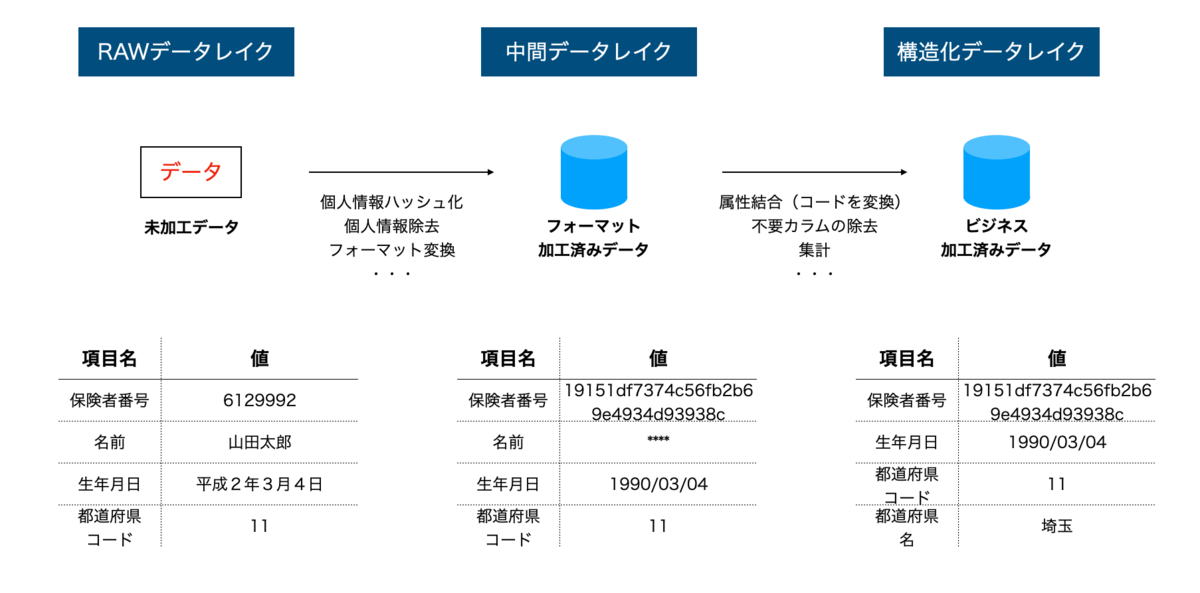
データレイクに、RAWデータレイク・中間データレイク・構造化データレイクと3つの名前をつけました。まずこのネーミングはオリジナルで、ググっても出てきません。ここ数年、データ分析基盤を作ってきた中の経験で、こんな感じでデータレイクを3層に分けると良いなぁってなっています。層ごとに便宜的に名前をつけたのが、RAWデータレイク・中間データレイク・構造化データレイクです。それぞれの層の役割をみていきましょう。
RAWデータレイク
RAWデータレイクは、名前のとおりに各データソースから送られてきたデータをそのまま(生のまま)配置するデータレイクです。加工していないという意味のRAWですね。ちなみに、データソースから送られてきたデータを加工していないという意味なので、このRAWデータレイクに入ってきた時点で、既に構造化データになっている場合もあります。
中間データレイク
中間データレイクは、RAWデータを扱いやすいように加工したデータレイクです。目的は扱いやすくするということなので、原則的にデータの意味は変えません。例えば、日付に関するカラムをすべてUTC形式に変換するなどのフォーマット変換や、個人情報が入っているカラムをマスクやハッシュ化するなどの匿名加工などの処理です。
構造化データレイク
最後に、構造化データレイクです。これは分析の目的に応じて様々な加工されたデータが格納されます。県コードのようなコード値を人間がみて解るように県名に変換することや、複数のデータを結合して新たなテーブルを作成するといったことや、データの集計など、ここでしておいても良いでしょう。つまりビジネスロジックに応じて加工されたデータです。
3層に分けると、何が嬉しいの?
それでは、この3層構造にすると、何が嬉しいのでしょう?メリットは、次の3点に集約できます。
- RAWデータが残っているので、観点が変わっても分析し直せる
- 中間データレイクがあると、様々な結合が容易にできる
- 構造化データレイクに対して、直接クエリーで検索できる
それぞれのメリットを、詳しく見ていきましょう。
RAWデータが残っているので、観点が変わっても分析し直せる
まず、RAWデータレイクの意味です。これは、加工前のデータを残せる事。これが非常に重要なことになります。データを加工するというのは、多くの場合は必要の無い部分を切り捨てることです。つまり情報の欠損が発生するということですね。後日、別の観点で分析したくなった場合に、情報が切り捨てられていて分析できないということもありえます。そうならない為に、加工前のデータをそのまま残しておく事が重要です。
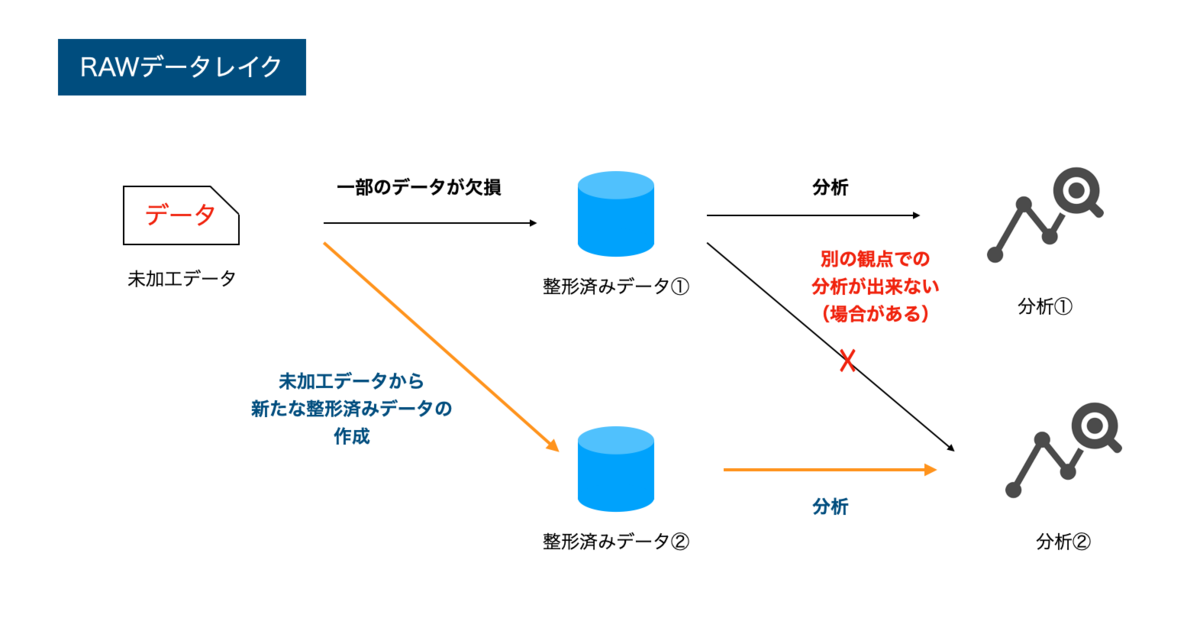
これ以外のメリットとしては、データソース側が未加工でデータを送信できる事もあります。データの加工や保存を、データソース側の責務にするかデータレイク側の責務するか、いろいろな考え方があります。また同様に、データレイクに個人情報が入ることを許すかどうか。これについては、また別の回で論じたいと思いますが、データソース側の負担を小さくできるのは、メリットと考える事もできます。
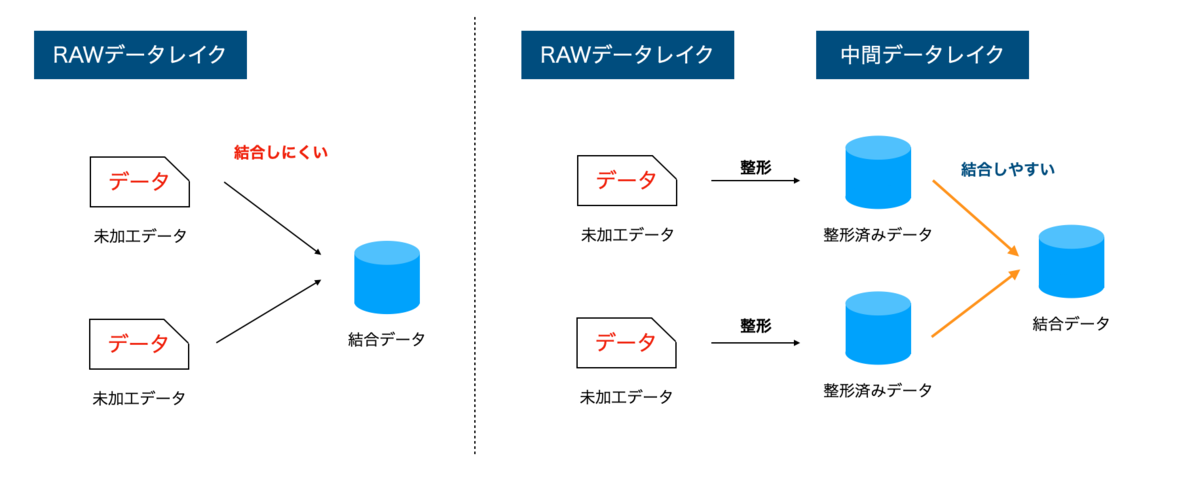
中間データレイクがあると、様々な結合が容易にできる
3層構造を提案した場合に、一番疑問に思われるのが、この中間データレイクです。率直に言うと、この層は必要なのかと。RAWデータと構造化データレイクの2層でも充分の場合もあります。しかし、中間層を作ることで次のようなメリットが生じます。
- フォーマット変換など機械的な加工のみなので、ビジネスロジック変更時にも再利用できる
- 複数のテーブルの結合が容易
どう結合するか、或いは集計するかは、分析の目的に応じて頻繁に変わりますし、変わるべきです。分析のための下準備のレイヤーを用意しておくことで、分析のための下準備を減らす事ができます。
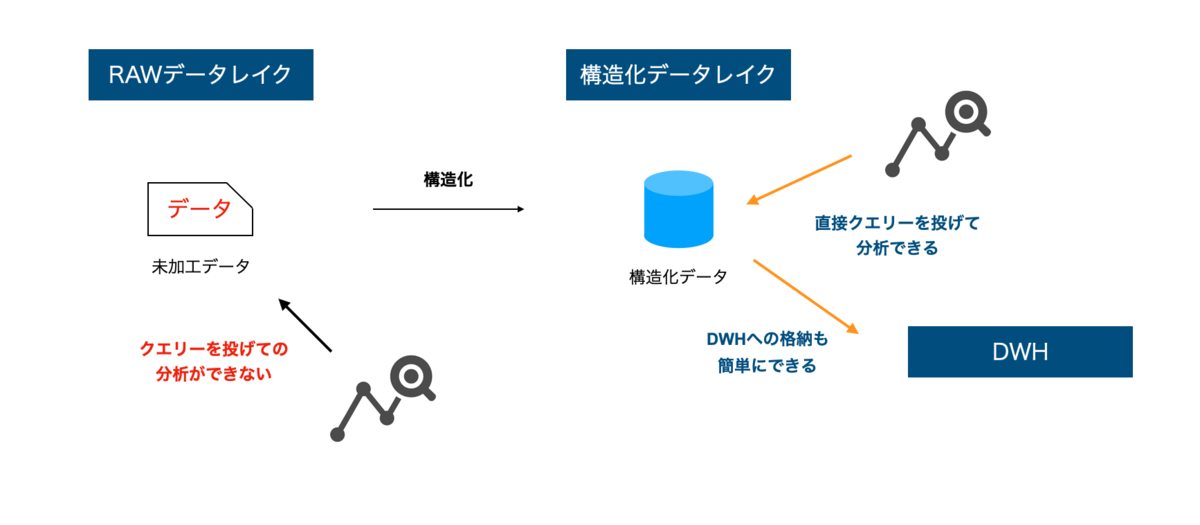
構造化データレイクに対して、直接クエリーで検索できる
構造化データレイクを作っておくことのメリットは、DWHいらずで直接クエリーを投げて分析できることです。AWSではAthenaやRedshift Spectrum、Google CloudやAzureでも使えるSnowflakeなどは、ストレージ内のデータに直接参照・集計できます。定型的な作業は、DWHにいれてしまった方が使い勝手が多いですが、どうするか検討する段階の分析(アドホック分析)ではDWHに入れずに分析できる事のメリットは大きいです。
まとめ
前回は、データ分析基盤はデータレイクとDWHを分離せよという話でした。今回は更にデータレイク内でも、RAWデータレイク・中間データレイク・構造化データレイクの3層に分離せよという話でした。加工前のデータを残しておくことは、後々になって重要さが増します。少なくともRAWデータレイク的なものは作っておくことはお勧めします。そのうえで、2層構造にするか3層構造にするかはご検討ください。私も1年後には、全く違う方法論を主張しているかもしれません。
DWHの方が進化して、非構造化データを簡単に扱えるような動きもあるみたいですしね。
これ面白い!Snowflakeは非構造化データへの対応も進めているので、AI-OCRアプリをSnowflakeで動かすことで、クラウドストレージにPDFが置かれると自動でテーブルにデータが格納される世界がすぐに来そうですね。#SnowflakeDB
— Mineaki Motohashi (@mmotohas) 2021年5月4日
Impira | Unlock the data within your files https://t.co/znW8zkVafV
