こんにちは佐々木です。
いろいろなところで口を酸っぱくして言っているのは、データレイクとDWHを分離しろと。とりあえずDWHに放り込むという考えはあるけど、DWHに入れる時点でデータの整形が行われて、情報の欠損がでてくる。だから、その前にデータレイクに生のままに入れること
— Takuro SASAKI (@dkfj) 2021年5月1日
データレイクとDWHの分離について呟いたら、それなりの反響を頂きました。せっかくの機会なので、もう少ししっかりと解説してみます。何故、データレイクとDWHを分離する必要があるのか、格納するデータの構造と、データレイク・DWHの役割の観点から考えてみましょう。まずは、データの種類として、構造化データや非構造化データの説明をします。その次に、データレイクとDWHなどの用語・役割の説明をし、最後にアーキテクチャを考えてみます。
構造化データと半構造化データ、非構造化データ
まずデータ内の構造に着目したデータの分類方法を紹介します。構造化データ、半構造化データ、非構造化データの3種類に分類できます。構造化データとは、一般的なリレーショナルデータベース(RDB)に格納されたデータや、ExcelやCSVで2次元の表として表されているようなデータです。これに対して、非構造化データとは、メールやワード内など、区切り等の構造をもたない文章などです。それ以外にも、画像ファイルや音声ファイル・動画ファイルなども非構造化ファイルになります。そして半構造化データは、非構造化ファイルに一定の規則性をもたせて、柔軟ながらも構造をもたせたファイルになります。具体的には、HTMLやXML、JSONなどを思い浮かべて貰えばイメージがつくでしょう。

コンピューターが処理しやすいデータは、構造化データです。一方で、世の中のデータの大半は非構造化データや半構造化データと言われています。データ分析基盤では、これらのデータを構造化データに変換して分析します。この非構造化データ/半構造化データからの構造化データの変換が、今回の重要なポイントになります。ここについては、後ほど説明します。
なお、構造化データ、半構造化データ、非構造化データは、なぜか総務省のICT教材に丁寧に解説されてたので、興味があればご参照ください。
https://www.soumu.go.jp/ict_skill/pdf/ict_ev_el_3_1.pdf
データレイクとDWH
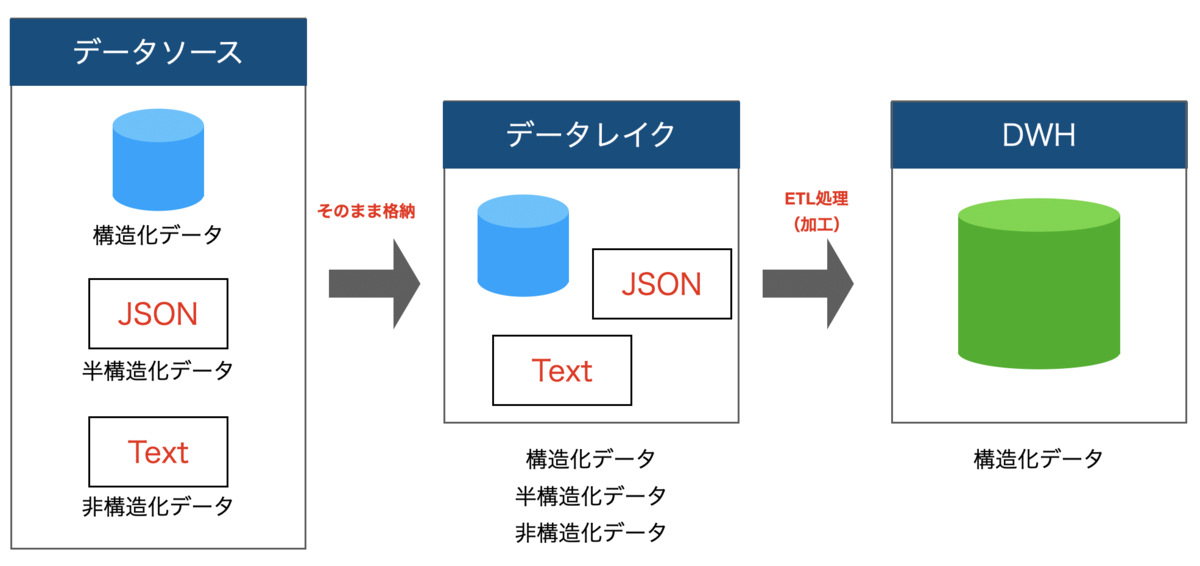
次にデータレイクとDWHです。データレイクは比較的新しい概念です。OLAPツールであるPentaho のCTO、James Dixonが2011年にデータマートに対比する形で、データレイクの概念を提唱したそうです。データレイクは、構造化/非構造化データを問わず、どのようなデータ形式でも一元的に格納するデータリポジトリです。AWSでいうとS3がデータレイクとして利用される事が多いです。
DWH(データウェアハウス)は、直訳すればデータの倉庫です。定義は一律ではないものの、概ね複数のシステムの構造化データを集約して管理するシステムの事を指します。格納されているデータはRDBから抽出されたデータが多く、構造化されています。そして、多くのDWHでは、SQLに準拠したクエリでデータの抽出が可能です。DWHの代表的な製品としては、Google CloudにおけるBigQueryやAWSのRedshiftがあります。 先程の構造化/非構造化の観点でいうと、どちらのデータも入れられるのがデータレイクで、(原則的に)構造化データしか格納できないのがDWHとなります。
構造化データと非構造化データの観点から、データレイクとDWHの違いが解りました。そして、ここからが、この記事で伝えたい事の本題です。
非構造化データ/半構造化データから構造化データを作り出すと、切り捨てられる情報が発生する
掲題していることが言いたい事のすべてです。非構造化データ/半構造化データから構造化データに変換する時に、情報の切り捨て/欠損が生じます。そのため、非構造化データ/半構造化データ ⇒ 構造化データの変換は可能でも、その逆の構造化データから非構造化データ/半構造化データに戻すことは不可能です。

上の図の例では、文章(非構造化データ)から情報を抜き出して、2次元の表を作っています。この過程でのポイントは、情報の抜き出しの際には、必ず情報の切り捨てが行われている点です。学年やポジション、身長といった定形の情報は、構造化データに保持しやすいです。しかし、ムードメーカーや肩が強いといった分類しにくいデータは切り捨てられがちです。もちろん、備考欄のような形でそういった情報を残すことも可能です。しかし、それでも文章の癖といった情報は切り捨てられます。そして、構造化データから非構造化データは、元に戻すことはできずに不可逆なのです。
情報が切り捨てられると、何が問題なのでしょうか?それは、将来的に全く別の切り口で分析したいときに、情報を切り捨てられた構造化データでは、既に分析不可能になっている可能性があることです。例えば、今までは定量的な情報のみ抜き出していたけど、定性的な情報であるポジティブかネガティブか感情分析したいとかですね。
このように、非構造化データ/半構造化データから構造化データを作り出す時は、情報の切り捨て・欠損が行われます。そして、失われた情報は後から取り戻すことはできません。では、システムのアーキテクチャで、どのように防げばよいのでしょうか?
データ分析基盤構築を構築する際は、かならずデータレイクとDWHを分離する
アーキテクチャの対策としては、ずばりデータレイクとDWHを分離することです。データレイクには、構造化データ・半構造化データ・非構造化データを問わず、まずそのままデータを格納します。そして、必要に応じて構造化し、DWHに格納します。こうすることにより、分析しやすい構造化データと、元の情報そのままの非構造化データの両方を残すことが可能です。
そういったアーキテクチャを推奨した場合、必ず懸念されるのがデータ保存のコストです。元の情報と加工した情報の2つを持つ事になるので、データ量としては単純に2倍近くなります。コスト面で心配になるのは、至極当然だと思います。しかし、クラウドの伸展で、データ保存に関するコスト面の心配はほぼ不要になっています。AWSの場合、データレイクとしてはS3を使いますが、1TBあたりのデータ保存にかかるコストは月あたり3,000円以下です。このコストが捻出が難しいようであれば、ビジネスの方を見直しましょう。
まとめ
少し長くなりましたが、Twitterで140文字ほどで呟いていたことは、上記のような事です。データレイクとDWHを分離することで、データの欠損を防ぎ分析処理もしやすくなります。データレイクの作り方については、更に設計上のコツがありますので、それはまた次回紹介したいと思います。
