
はじめに
こんにちは、寺嶋です。
re:Invent 2025 に現地参加してきました。その中で「Data analytics for financial organizations with Amazon SageMaker」
というワークショップに参加したので内容をまとめます。
このワークショップは、金融機関にありがちな「データはあるが、どれを使えばいいか分からない/共有が怖い」という状態を、Amazon SageMakerの機能を使って改善する流れを体験するものでした。
具体的には、生データを分析向けに整備し、メタデータ(説明・属性)を付け、承認プロセスを経てデータカタログとして公開しました。
その結果、作る側(データエンジニア)は整備〜公開の手間が減り、管理側(オーナー)は責任ある公開ができ、使う側(分析担当)は信頼できるデータを素早く見つけられるようになります。
Amazon SageMakerとは
機械学習を実施するうえで、必要なプロセスを行うトレーニングデータの前処理や作成・機械学習(ML)モデルの構築・学習・学習モデルのデプロイといった、一連のプロセスを行う機能が備わっているマネージドサービスです。
ワークショップの概要
ワークショップ説明文の日本語訳です。
この実践的なワークショップでは、金融機関がAmazon SageMakerを使ってエンドツーエンドのデータ分析やMLワークフローを構築し、スケールさせ、管理する価値をどのように生み出せるかを学びます。銀行のユースケースに対応し、顧客セグメンテーション、不正検出、チャーン予測、パーソナライズされたコミュニケーション、文書処理などをカバーします。データアナリスト、データエンジニア、データサイエンティストが、専用のツールと統合されたワークフローを用いて一つのプラットフォームで協力する様子を体験しましょう。
ワークショップの流れ
このワークショップは14:30~15:30の1時間のセッションです。
このセッションは予約できていなかったのでWalk-Up(先着順)で参加しました。
中は8人ごとのグループ席に、1人のティーチャーがつき、それぞれのグループで進められていく感じでした。
最初に10分の説明パートが終わると、その後は各自ハンズオンを進めていくという流れでした。
資料はブラウザの翻訳機能で日本語表示にして閲覧でき、画像も多かったため、資料だけでもある程度理解することができました。
また、ティーチャーが見回ってくれていたので、質問しやすい環境でした。
<実際のスケジュール>
13:55 Walk-Up(先着順)に並ぶ。このとき、Reserved(予約済み)もWalk-Up(先着順)も既に数人並んでいました。
14:15 Reserved(予約済み)が入場開始。会場が7割ほど埋まっていました。
14:23 Walk-Up(先着順)が入場開始。
14:26 グループの席が埋まったので、早めにセッション開始
14:40 ハンズオン開始
ワークショップの内容
データエンジニア、ステークホルダー向けに銀行のデータの準備、公開をします。 エンジニアとして、銀行データをアップロードし、Amazon SageMakerカタログに公開することで、ビジネス関係者がアクセスできるようにします。
データセット(テーブル)の準備
まずは、銀行データをもとに分析用のテーブルを作成します。 ここでは組織として利用できる統一されたデータセットを作成します。
①上部のビルドメニューからJupyterlabを選択し、用意されたファイルをダウンロードします。
この環境で作業を行います。
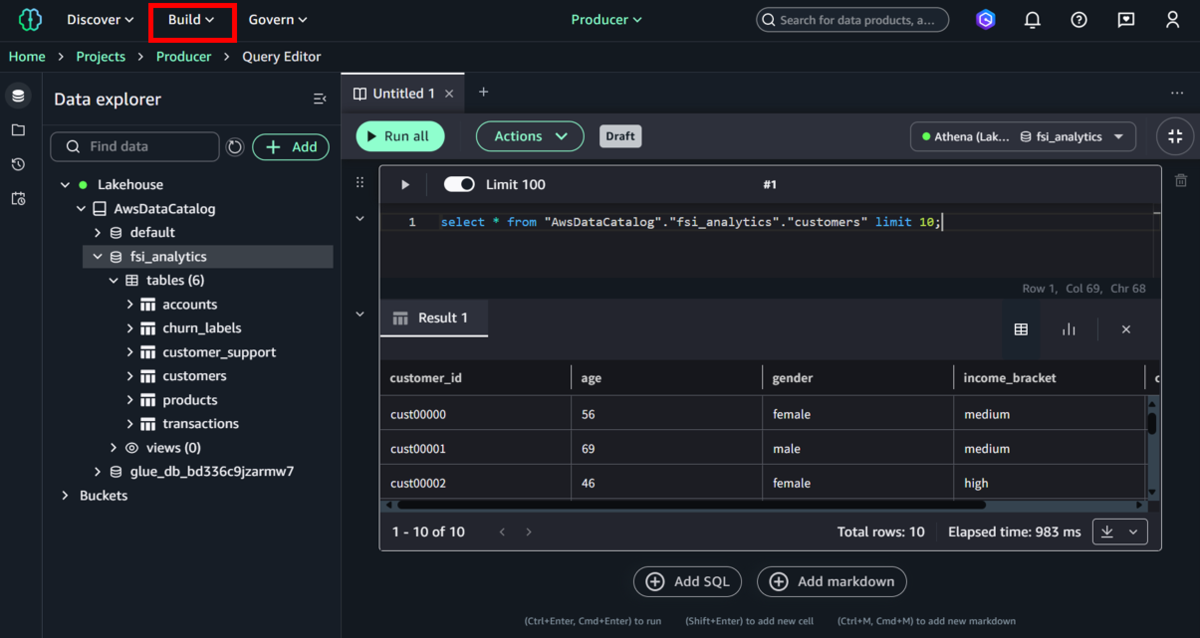
②ファイルを開き、各セルを選択し順番に実行します。
データの読み込み、加工、集計といった処理を再現可能な形(コード)で実行します。

③テーブルが作成できたことを確認します。

データをAmazon SageMakerカタログに公開
作成したデータセットを Amazon SageMaker のデータカタログに公開し、他のチームがアクセスできるようにします。
①アクションの3つの点(︙)を選択し、「Run」でプロジェクトのデータソースを実行します。
実行することで、作成したデータセットを プロジェクトの管理対象として認識させます。

②「DATA SOURCE RUNS」タブで新たに作成されたデータセットを見つけ、公開準備完了であることを確認します。

③左のナビゲーションバーを「Project catalog」の「Assets」から対象のアセットを選択します。
④「BUSINESS METADATA」の「GENERATE DESCRIPTIONS」を選択すると、数秒以内にビジネスメタデータとスキーマ説明情報が自動で入力されます。
⑤メタデータ生成のポップアップが表示されたら「Accept」を選択して変更を承認します。
自動生成された情報を人の目で確認し、責任を持って承認するプロセスになります。
⑥SCHEMAタブを確認して、カラムの内容が正確かを確認します。

⑦「LINEAGE」タブを選択し、リソースのライフサイクルで確認することもできます。
いつ作成され、どう管理されるデータなのかを明確にすることができます。
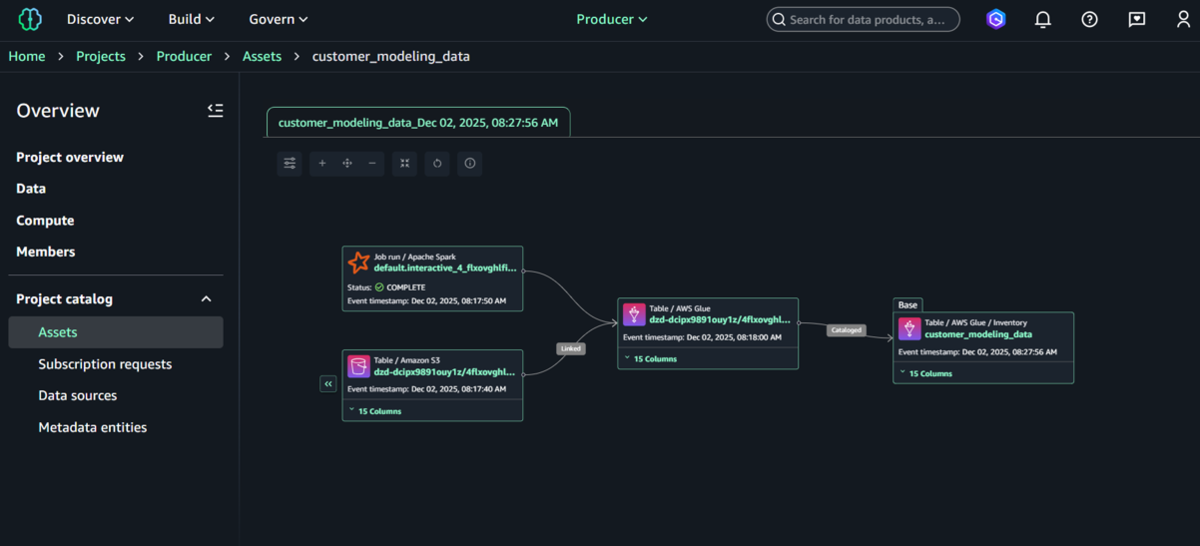
⑧すべての情報を確認した後、Amazon SageMakerカタログにメタデータを保存するために「Accept ALL」を選択します。
⑨「Publish ASSET」を選択し、データを組織内の他のプロジェクトで利用できるようにします。完了すると「PUBLISHED」と表示されます。
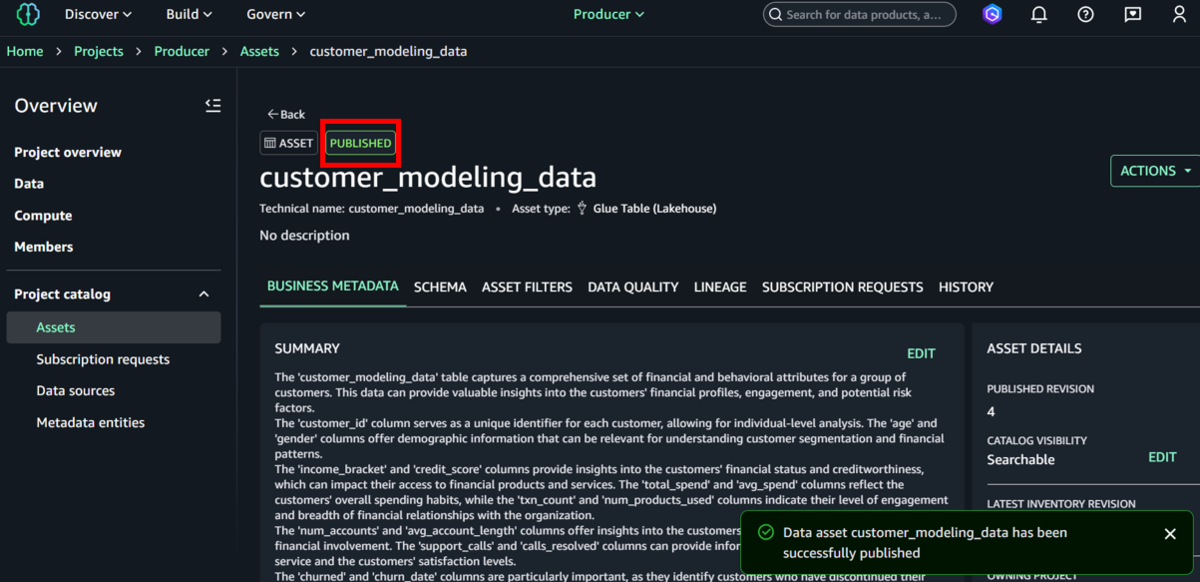
以上の手順を通じて、銀行データをAmazon SageMakerカタログに公開し、ビジネス関係者がアクセスできるようになりました。
おわりに
Amazon SageMaker はこれまでも名前はよく耳にしていましたが、今回のワークショップで実際に手を動かしてみることで、想像以上に手軽に扱えるサービスだと感じました。
コンソール上でデータの準備から公開までを一貫して行える点は非常に便利でありながら、最終的な公開前には人が内容を確認し、「Accept」ボタンを押して承認するプロセスが用意されている点が印象的でした。
自動化と人による確認がバランスよく組み合わさっており、安心して利用できる仕組みだと感じました。
今回はデータの準備と公開が主な内容でしたが、今後は今回作成したデータを実際に活用し、分析や調査につなげる部分にも挑戦してみたいと思います。
今回の体験を通じて、Amazon SageMaker を活用したデータ分析のイメージがより具体的になりました。
