本記事は
生成AIウィーク
3日目の記事です。
👨💻
2日目
▶▶ 本記事 ▶▶
4日目
👩💻

1. はじめに
皆さんこんにちは、新入社員の松澤武志です!
もうあと2か月で新入社員と言い張るのが厳しくなってきました…(汗)。働いていると、時が過ぎるのが早いですね~。
今回は生成AIウィークということで、生成AIにまつわるテーマで筆を進めていきたいと思います。生成AIといえば、思い浮かぶのはやはりStable Diffusionでしょうか。大学生の時に授業でStable DiffusionをGoogle Colaboratory上で動かしていたのを思い出します。最近、AWSのサービスの1つであるAmazon SageMaker AI について勉強していたのですが、Amazon SageMaker JumpStartという機能を用いれば、Google Colaboratory上でなくてもAWS上でJupytorLabを用いてモデルを簡単に利用できることがわかりました!
ということで今回は、Amazon SageMaker JumpStartの使い方をお伝えすることを目的として、Amazon SageMaker JumpStartを用いてStable Diffusionモデルの推論エンドポイントをデプロイしてみようと思います!
※実はAmazon Bedrockを利用すれば、さらに簡単にモデルを利用できますが、今回はSageMaker JumpStartを学んだアウトプットとして共有させていただきます。
2. 基本知識
2-1. Amazon SageMaker AIとは
Amazon SageMaker AIの公式サイトはこちらになります。
Amazon SageMaker AIとは、機械学習モデルのパイプラインをサポートする様々な機能を兼ね備えたAWSが提供するクラウドサービスのことです。データレイクからデータを取得し、モデルを作成して、デプロイ、モニタリングまで、様々なコンポーネントを利用することでユーザーの機械学習モデルの構築や管理をサポートしてくれます。JupyterLabやR Studioのような馴染みのあるIDEも使用でき、大規模な開発を行うことができます。
今回紹介するAmazon SageMaker JumpStartはそのコンポーネントの一つです。
2-2. Amazon SageMaker JumpStartとは
Amazon SageMaker JumpStartの公式サイトはこちらになります。
Amazon SageMaker JumpStartは、MetaやHugging Faceなど、様々なプラットフォームで提供されているモデルを簡単にデプロイする機能のことです。
この機能を使えば、特にユーザーがモデルをトレーニングするためのコード等を記述したりしなくても、事前に記述されたサンプルノートブック等を実行、または少ないパラメータの変更で簡単にモデルのデプロイができます!モデルの中には、自前のデータでファインチューニングすることができるモデルも存在します!
このSageMaker JumpStartは、機械学習パイプライン上の「データ準備」→「データの前処理」→「特徴量エンジニアリグ」→「モデル作成」→「モデル評価」が済んだモデルに関して「モデルのエンドポイントへのデプロイ」→「推論」を行うだけです。「推論」までの過程をまさにJumpしてStartしているわけです。 したがって、手軽にトレーニング済みモデルを使用したい時などにとても有用です!
2-3. 画像生成モデルStable Diffusionとは
AWS公式にStable Diffusionの説明が記載していました!
Stable Diffusion は、テキストや画像プロンプトから写真のようにリアルな独自の画像を生成する生成型人工知能 (生成 AI) モデルです。
とのことです。簡単に言うと、オープンソースの画像生成AIサービスです。
元の画像データにランダムノイズを加える過程(順拡散)と、そこからノイズを除去し、画像を生成する過程(逆拡散)からなる潜在拡散モデルを利用しています。プロンプトにテキスト入力することで0から画像生成をする「txt2img」と呼ばれる技術や、画像とテキストを入力することで元の画像からテキストに沿った画像を生成する「img2img」と呼ばれる技術に分類されます。
Stable Diffusionのモデル自体は、綺麗な人物を出力したりするものやアニメ風イラストを出力するものなど、様々なモデルが公開されており、JumpStartでも様々なモデルを利用することができます。
その中でも今回は、Stability AIが提供する「Stable Diffusion XL 1.0」というモデルを用います。このモデルはStability AIが開発したモデルでSDXLと呼ばれます。通常のStable Diffusionモデルに加えて、リファインメントモデルと呼ばれるモデルを使用して、潜在拡散モデルで生成された画像を精密化して綺麗に仕上げることができるモデルです。このモデルはSageMaker JumpStartでも利用できるので、モデルをデプロイして推論する過程をお届けします!
3. JumpStartでStable Diffusionモデルを使ってみた
3-1. 環境構築
それでは事前準備として環境構築をしていきます。環境構築とはいっても作業自体は何ら難しいステップはありません。
ステップとしては、以下になります。
- AWSコンソールでSageMakerドメインの作成
- SageMaker Studioを立ち上げ、Jump Startからモデルを選択
- 推論エンドポイントのデプロイ
まず、AWSコンソールにログインし、SageMakerドメインを作成します。
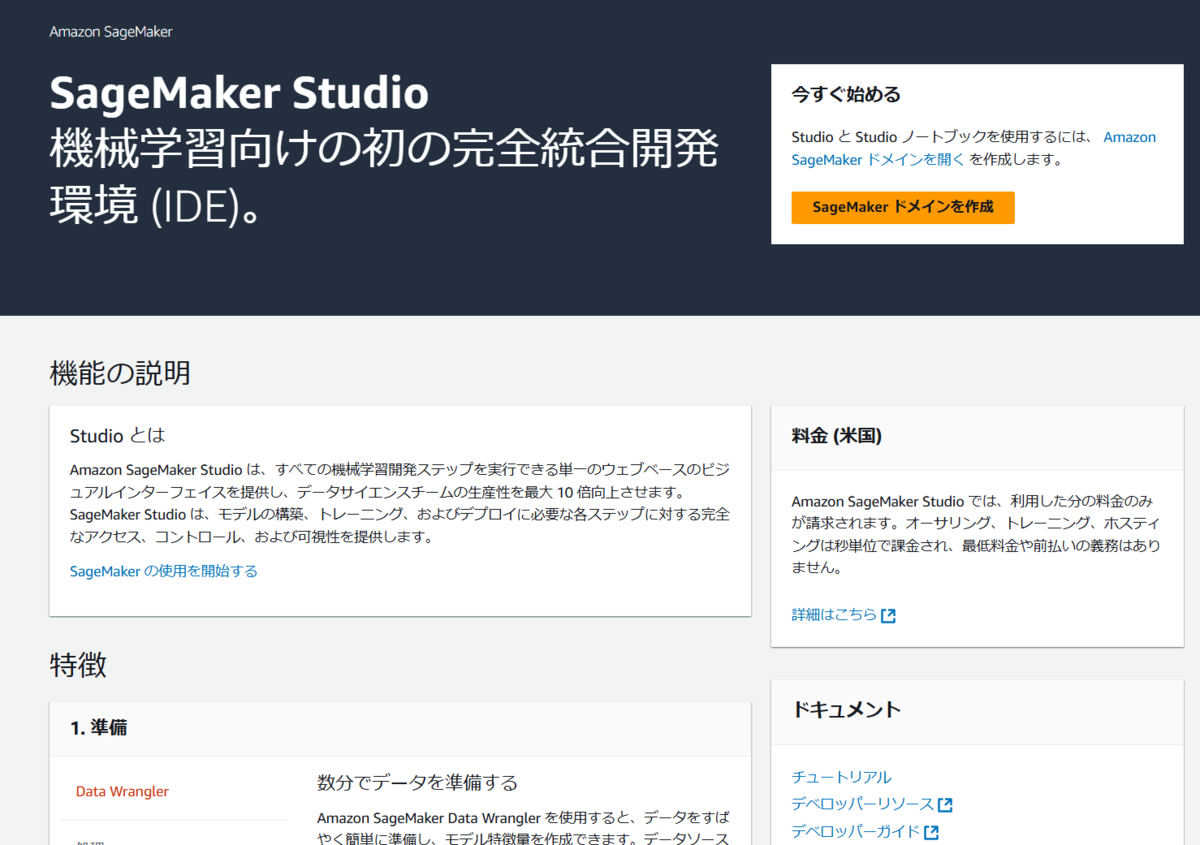
ドメインを作成したら、今回は私が個人的に使用するドメインですので、シングルユーザー向け設定を選択します。
そして数分後にドメインの作成が完了しますので、グローバルナビゲーションのStudioを選択します。その後、SageMaker Studioが立ち上がります。
Studioのグローバルナビゲーションから「Jump Start」を選択すると以下のような画面が表示されます。HuggingFaceやMetaなどのプロバイダが提供している様々なモデルを手軽に利用できます。
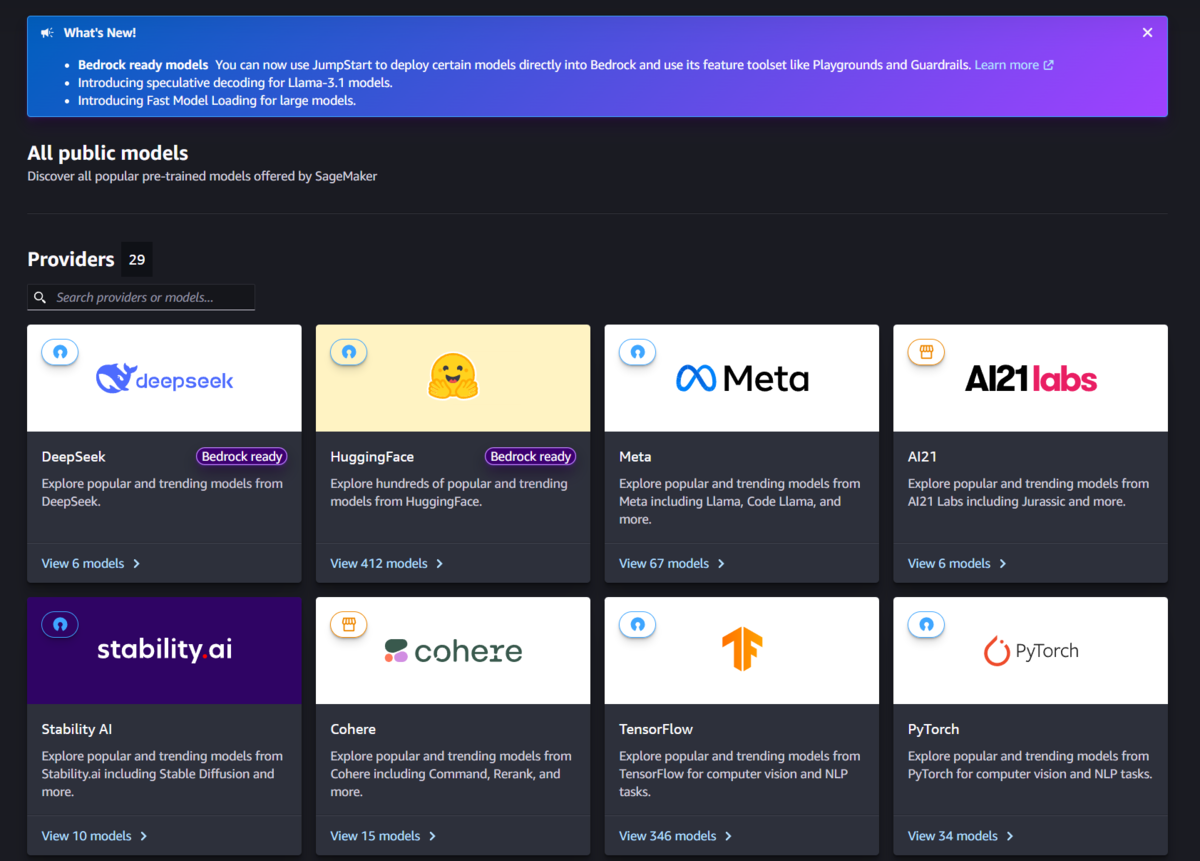
これらの中から今回は「Stable Diffusion XL 1.0」を選択します。
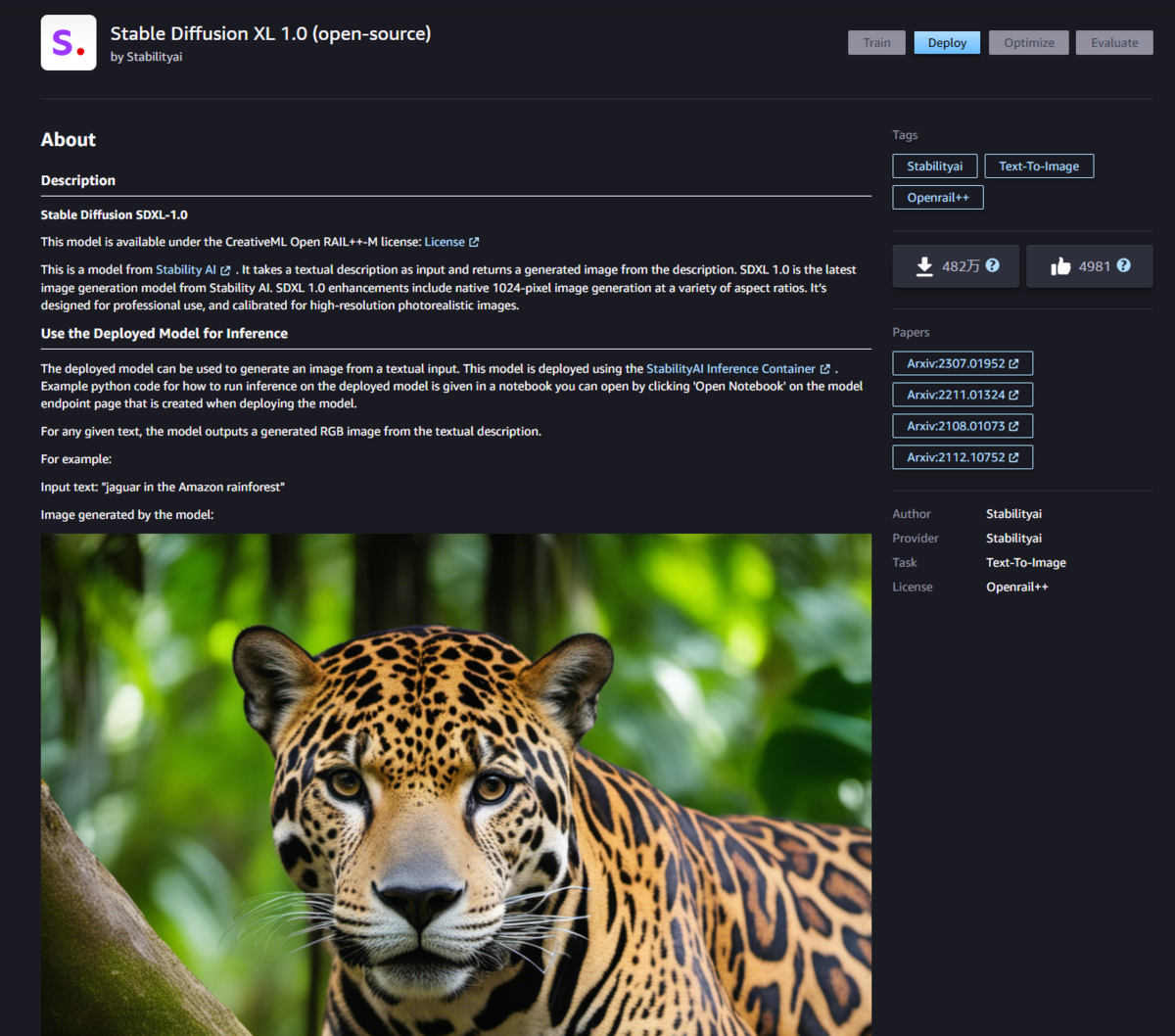
次にDeployボタンを押下してモデルのエンドポイントをデプロイします。私のAWSアカウントのサービスクォータの関係でインスタンスを2個立ち上げることができないので「Maximum instance count」を1に設定していますが、それ以外は変更していません。
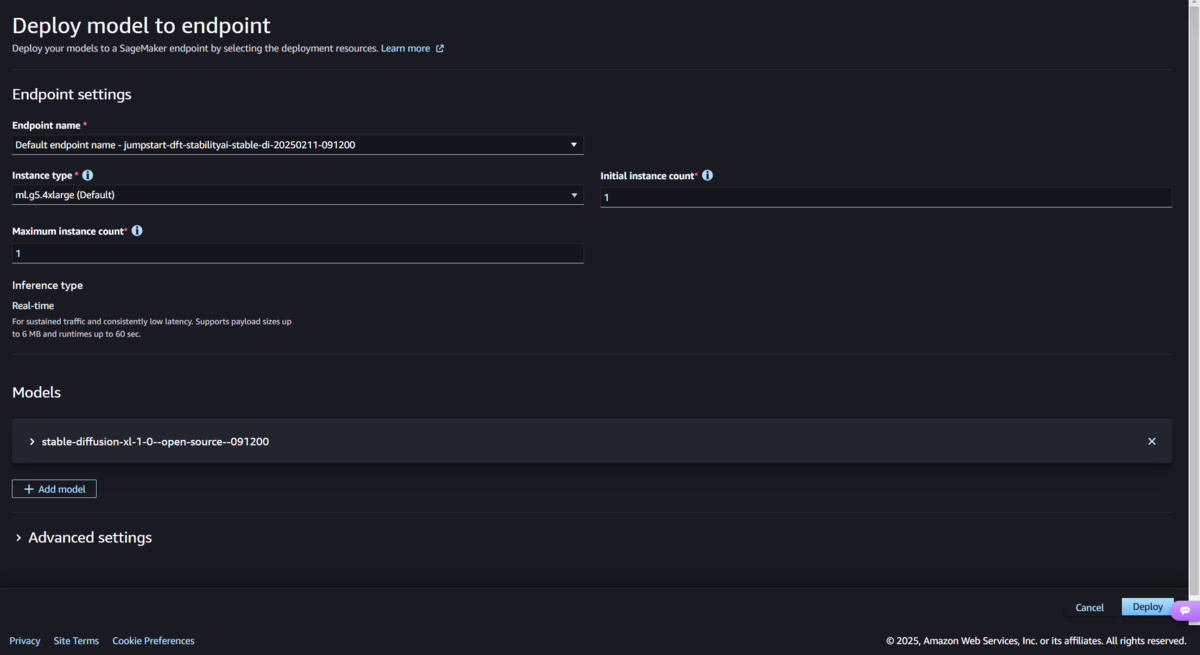
「Deploy」ボタンを押下し、数分すると、「jumpstart-dft-stabilityai-stable-di-日付」という推論エンドポイントがデプロイされました。 こちらはリアルタイム推論という、リクエスト時に即座に推論する種類のエンドポイントとなります。
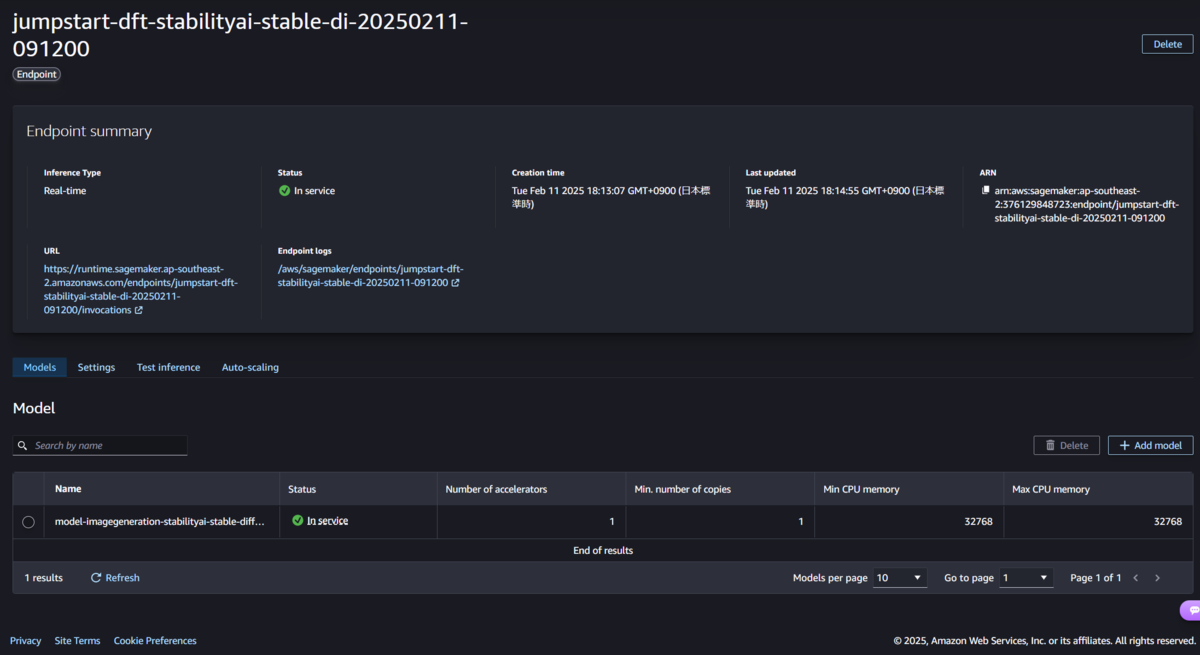
ちなみに、SageMakerで作成されたモデルをユーザーが利用するために前述した「推論エンドポイント」にモデルをデプロイします。画像生成モデルですので違和感がある方もいらっしゃるかもしれませんが、画像生成も「推論」の一種となります。
3-2. デプロイした推論エンドポイントによる画像生成
先ほど作成した推論エンドポイントを実際に使用して画像生成を行ってみましょう!
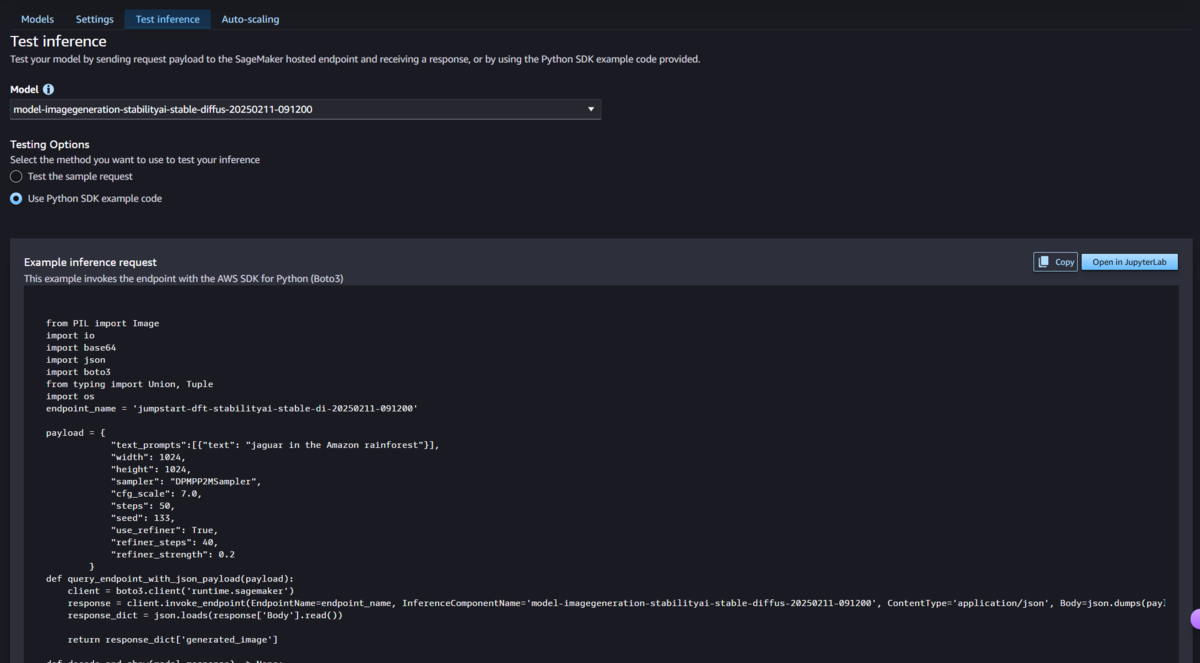
といってもやることは簡単です。先ほどのエンドポイントを選択し、「Test inference」タブを選択します。その次に「Open in JupyterLab」を押下します。これにより「Example inference request」に記載しているコードを、機械学習によく使用されるJupyter Labと呼ばれる環境で実行することができます。
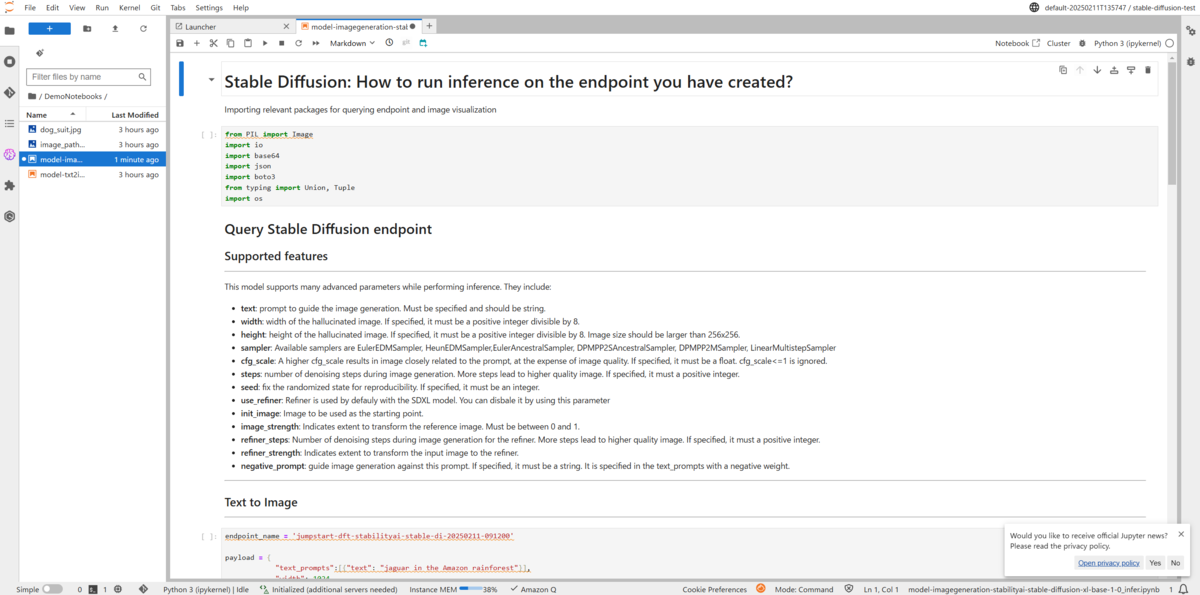
Jupyter Labではこのようにノートブック形式でソースコードが表示されます。ただコードが記載されるだけではなく、実行方法やパラメータの解説などもマークダウン形式で記載されます。コード自体の生成や説明までしてくれるのはJumpStartの魅力ですね!
生成されたPythonコードには何が書いてあるのか
この段階で「モデルのエンドポイントへのデプロイ」までは終了しているので、残りは「推論」だけです。下記に具体的な「Example inference request」で自動生成されたコードを記載します。これらは名の通り、「推論」をするためのコードとなっています。
txt2img テキストから画像を生成
下記のコードは必要なライブラリ、endpoint_nameの定数を定義しているコードになります。
from PIL import Image import io import base64 import json import boto3 from typing import Union, Tuple import os endpoint_name = 'jumpstart-dft-stabilityai-stable-di-20250211-091200'
下記はpayload部となります。このパラメータで画像を生成してください!とモデルに受け渡す値です。プロンプトに入力するテキストもこちらに記載します。
- text: 画像生成を指示するプロンプト。
- width:生成画像の幅。
- height:生成画像の高さ。
- sampler:画像を生成する際にノイズをどのように除去するかを決めるアルゴリズム。
- cfg_scale: 大きくすると、画質は犠牲になるが、プロンプトに近い画像が得られる。
- steps: 画像生成時のノイズ除去ステップ数。ステップ数が多いほど高画質になる。
- seed:ノイズの初期値を決める値。異なる数にすると異なる画像が生成される。
- use_refiner: 高品質化するリファイナーを利用するか。(Stable Diffusion XLで搭載の機能)
- refiner_steps: リファイナーの画像生成時のノイズ除去ステップ数。ステップ数が多いほど高画質になる。
- refiner_strength:入力画像をどの程度リファイナーに変換するかを表す。
payload = {
"text_prompts":[{"text": "jaguar in the Amazon rainforest"}],
"width": 1024,
"height": 1024,
"sampler": "DPMPP2MSampler",
"cfg_scale": 7.0,
"steps": 50,
"seed": 133,
"use_refiner": True,
"refiner_steps": 40,
"refiner_strength": 0.2
}
下記はpayload部を用いてエンドポイントで推論を行い、レスポンスを返す関数と、そのレスポンスをデコードしてJupyterLab上で表示する関数を定義してそれぞれ呼び出しているコードになります。
def query_endpoint_with_json_payload(payload): client = boto3.client('runtime.sagemaker') response = client.invoke_endpoint(EndpointName=endpoint_name, InferenceComponentName='model-imagegeneration-stabilityai-stable-diffus-20250211-091200', ContentType='application/json', Body=json.dumps(payload).encode('utf-8'), Accept='application/json') response_dict = json.loads(response['Body'].read()) return response_dict['generated_image'] def decode_and_show(model_response) -> None: """ Decodes and displays an image from SDXL output Args: model_response (GenerationResponse): The response object from the deployed SDXL model. Returns: None """ with Image.open(io.BytesIO(base64.b64decode(model_response))) as image: display(image) response = query_endpoint_with_json_payload(payload) decode_and_show(response)
img2img 画像とテキストから新たな画像生成
下記は、入力に用いる画像をBase64形式の文字列にエンコードする処理を行う関数を定義しています。
def encode_image(image_path: str, resize: bool = True, size: Tuple[int, int] = (1024, 1024)) -> Union[str, None]: """ Encode an image as a base64 string, optionally resizing it to a supported resolution. Args: image_path (str): The path to the image file. resize (bool, optional): Whether to resize the image. Defaults to True. Returns: Union[str, None]: The encoded image as a string, or None if encoding failed. """ assert os.path.exists(image_path) if resize: with Image.open(image_path) as image: image = image.resize(size) image.save("image_path_resized.png") image_path = "image_path_resized.png" with Image.open(image_path) as image: assert image.size == size with open(image_path, "rb") as image_file: img_byte_array = image_file.read() # Encode the byte array as a Base64 string try: base64_str = base64.b64encode(img_byte_array).decode("utf-8") return base64_str except Exception as e: print(f"Failed to encode image {image_path} as base64 string.") print(e) return None
下記は、S3バケットに保存されたdog_suit.jpgという画像ファイルをダウンロード、JupyterLab上で表示しています。
ここで、boto3とは、AWS SDKの一つで、Pythonを用いてAWSリソースを管理するためのライブラリです。また、sagemaker.jumpstartとは、SageMaker JumpStartにまつわる処理をまとめたパッケージです。
# Here is the original image: from sagemaker.jumpstart import utils s3_bucket = utils.get_jumpstart_content_bucket(boto3.Session().region_name) key_prefix = "model-metadata/assets" input_img_file_name = "dog_suit.jpg" s3 = boto3.client("s3") s3.download_file(s3_bucket, f"{key_prefix}/{input_img_file_name}", input_img_file_name) with Image.open(input_img_file_name) as image: display(image)
下記はtxt2imgの時と同様にpayload部にパラメータを入力し、推論をしています。
画像特有のパラメータを下記に記載します。
- init_image: 開始点として使用する画像。
- image_strength: 参照画像を変換する範囲を示す。
size = (512, 512) dog_data = encode_image(input_img_file_name, size=size) payload = { "text_prompts":[{"text": "dog in embroidery"}], "init_image": dog_data, "cfg_scale": 9, "image_strength": 0.8, "seed": 42, } output = query_endpoint_with_json_payload(payload) decode_and_show(output)
3-3. 様々な画像を生成してみた
せっかくなのでいろんな画像を生成してみましょう!
今回text_promptsに入力する文字列は日本語は指定できないので、別途翻訳ツールを使用して英語に変換してからプロンプトに入力するものとします。各生成画像の下に、入力したプロンプトを記載しています。
txt2img



txt2imgは、個人的に画像生成が楽しすぎて24もの画像を生成してしまいました。
このようにStable Diffusionを利用すれば、現実にありそうな画像だけでなく、現実ではありえなさそうな画像まで、多種多様な画像を生成することができます。
しかし、中には「Library books walk themselves back to the bookshelf(図書館の本が自分で歩いて本棚に戻る)」や「People of the future are teaching dinosaurs how to use smartphones(未来の人が恐竜にスマホの使い方を教えている)」など、一部のプロンプトでは予想通りの画像が生成されないパターンも出力されてしまいました。後者に関しては恐竜人がスマホを使いこなしていると思われる画像を出力しています。
このような場合は、出力のパターンを変えるseedパラメータの数を変更してもう一度推論を行うと予想通りの出力が得られる可能性があります。
img2img

img2imgでは、「Stable Diffusion XL 1.0」で提供されている犬の画像とtxt2imgで出力した「Hamsters dancing on the river(川の上で踊るハムスター)」を利用して「毛糸化」「笑わせる」「太らせる」「木のおもちゃにする」という文言をプロンプトに入力しました。
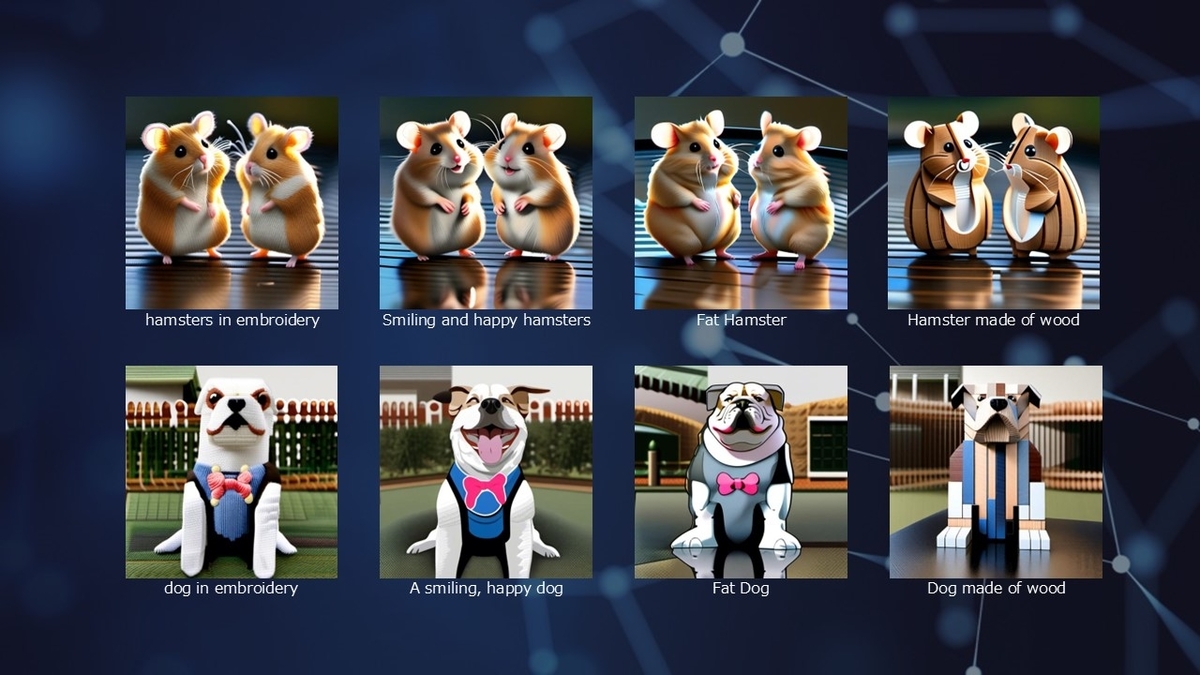
それぞれ元の画像の特徴をとらえたままプロンプト通りに変化させることができました。
3-4. 不要なリソースの削除
推論を終えたので、最後に無駄な課金を防ぐために不要なリソースを削除します。SageMaker で発生する料金は下記リンクに記載されています。
JumpStartに関して下記の記載があります。
Jumpstart は、一般的な機械学習ユースケースを解決するエンドツーエンドソリューションも提供しており、お客様のニーズに合わせてカスタマイズすることができます。JumpStart のモデルやソリューションの使用には、追加料金はかかりません。基礎となるトレーニングおよび推論インスタンスの使用時間については、手動で作成した場合と同じように課金されます。
今回はさらに、ドメイン設定でシングルユーザー向け設定、推論を行うためにJupyterLabも使用したので、今回使用したリソースで課金される対象は下記の3つとなります。
- ノートブックインスタンス(JupyterLab)
- 推論インスタンス(推論エンドポイント)
- ユーザーに紐づくEBSボリュームのストレージ使用料
- 今回のストレージ使用料は1日あたり0.01$と少額でした。 スペース・ユーザーを削除しなければならないので、スペース・ユーザーを再利用したい方は削除しなくても良いかと思います。
それぞれ使用時間当たりの料金として計算されるので、無料利用枠が存在するとはいえ、起動し続けると課金されてしまいます。ということで不要なリソースを削除します。今回生成したリソースを今後利用することはないので、今回は下記のすべてのリソースを削除することとします。課金のみを抑制する場合は太字の部分のみを停止・削除すると、その他のリソースを残すことができます。
- Studioからノートブックインスタンスの停止
- ノートブックインスタンスの停止(ノートブックインスタンスの課金を抑制)
- コンソールから推論エンドポイントの削除
- 推論エンドポイントの削除(推論エンドポイントの課金を抑制)
- エンドポイント設定の削除
- モデルの削除
- ドメイン
- スペースの削除(ユーザー削除のため)
- ユーザーの削除(EBSボリュームの課金を抑制)
- ドメインの削除
ドメインのみを削除した場合でもエンドポイントが起動しており、課金が継続するケースもあるため注意しましょう。
私は以前SageMaker Studio Classicを使用していると、自身でも気づかないうちにSageMakerのコンポーネントの一つであるDataWranglerが立ち上がっており、無料利用枠を超えて10$課金されてしまったというトラウマがあります。それ以降SageMakerを使用したらドメインごと削除する癖がついてしまっています。(インスタンスを停止することで課金を防ぐことが可能ですが、停止し忘れる可能性もありますので、もし不要でしたらドメイン事削除するほうが無難かなと個人的には思います)
皆さんもSageMakerやAWSのサービスを利用するときは不要なリソースを削除して不要な課金をしないように気を付けましょう!
4. まとめ
このように、SageMaker Jump Startを使えばかなりお手軽にStable Diffusionモデルのデプロイから推論まで行うことができました!
AIFやMLAで勉強していたとはいえ、SageMaker JumpStartを使用したのが初めてだったので、試行錯誤しながら取り組みました。自分でも事前に想定したものの10倍は簡単に画像生成できたので驚きでした!また、若干失敗したプロンプトもあるので、失敗した原因を探るために、失敗したか否かでAmazon SageMaker Ground Truthでラベル付けをして、失敗するプロンプトを推定しても面白そうですね!
今回は用いなかったのですが、Stability AIの提供するSageMaker JumpStartで利用できるモデルの一つに「Stable Diffusion 2.1 base」というモデルがあります。こちらはデプロイして推論を行うだけでなく、ユーザーが用意する数枚の画像を利用してファインチューニングを行うことができます。さらに他にも、SageMaker Jump StartにはStable Diffusion以外の様々なモデルも利用できます!皆さんもSageMaker JumpStartを用いて、AI・機械学習ライフを楽しんでください!
あとがき
実は面白い画像を生成するアイデアを、ChatGPTに考えてもらっていました。
Stable Diffusionに入力するプロンプトを考えています。ただし、現実ではありえないような状況の画像を生成したいと考えていますが、思いつきません。コンプライアンスに違反しない範囲で面白い状況を教えてください
面白くて非現実的な状況のアイデアをいくつか考えてみました!Stable Diffusionでのプロンプト作成の参考にどうぞ。
1. ファンタジー・SF系
- 「空飛ぶクジラの背中に街が広がる、幻想的な風景」
- 「猫サイズのドラゴンたちがカフェでお茶をしている」
- 「魔法使いがスマホで呪文をダウンロードしている」
- 「巨大なロボットが海でサーフィンしている」
2. 現実にはありえない日常系
- 「図書館の本が自分で歩いて本棚に戻る」
- 「フクロウがカフェでバリスタをしている」
- 「ピザが自分でスライスになって皿に飛び乗る」
- 「バス停でバスを待つペンギンたち」
3. 逆転・パラドックス系
- 「宇宙飛行士が海の底を歩いている」
- 「魚が水中ではなく空を泳いでいる」
- 「雲の上で人々がスケートをしている」
- 「未来の人が恐竜にスマホの使い方を教えている」
4. 食べ物を面白くする系
- 「雲がわたあめでできている世界」
- 「惑星の表面がチョコレートでできている」
- 「ラーメンの海で泳ぐ忍者」
- 「スイカの中に小さな宇宙が広がっている」
5. 物の擬人化系
- 「目と口のついたコーヒーカップが会話している」
- 「電車が笑顔でレールを走る」
- 「ピアノの鍵盤がダンスをしている」
- 「時計の針が疲れて休憩している」
どれもStable Diffusionなら面白いビジュアルになりそうですね!
気になるアイデアがあれば、それをもとに具体的なプロンプトを作ることもできますよ😊
おかげでなかなか面白い画像の数々を生成することができました!「猫サイズのドラゴンたちがカフェでお茶をしている」が個人的にかわいくて好きですね~。
※ 「Stable Diffusion XL 1.0」は下記Creative ML Open RAIL++-Mライセンスに基づいています。
LICENSE.md · stabilityai/stable-diffusion-xl-base-1.0 at main
※本記事執筆にあたっては個人でユーザー登録したAWSアカウント上でAWSサービスを使用しています。
※本記事執筆にあたって使用したモデル「stable-diffusion-xl-base-1.0」は2025-02-11(JST)に実行し、その時点における次のEnd user license agreement (EULA)に基づいています。
Stability AI Stable Diffusion XL 1.0 :STABILITY AMAZON SAGEMAKER END USER LICENSE AGREEMENT(Last Updated June 15, 2023)
