
はじめに
ジブリの音楽を演奏できるようになることを夢見て、最近カリンバという楽器を購入した松村です。
本ブログでは、Google Cloud Next 2025 で一般公開機能として紹介された BigQuery ML の貢献度分析(※1)を試した内容をまとめます。今回は、ニューヨーク市のシェアサイクルサービス「Citi Bike」の利用データを使用して、貢献度分析を実施し、データから有益なインサイトを引き出すという一連の流れを紹介してみたいと思います。貢献度分析は、簡単に意味のあるインサイトを網羅的に出せる機能なので、是非最後まで見ていただき、皆さんの業務にも活用してみてください。
(※1)参考:貢献度分析の概要 | BigQuery | Google Cloud
貢献度分析とは
貢献度分析(Contribution Analysis)は、ある特定の成果(数値)に対して、どの要素(ディメンション)がどれくらい影響を与えているのかを明らかにする分析手法です。
例えば、ECサイトの売上が前年比で20%増加した場合に「どの製品カテゴリが貢献したのか?」「どの地域のお客様が増えたのか?」「どのキャンペーンが効果的だったのか?」といった疑問に答えるのに役立ちます。逆に、売上が減少した場合にも、その原因となった要素を特定するのに使えます。
これまでは、様々な角度からデータを集計し、比較することで原因を特定していたかと思います。しかし、BigQuery ML の貢献度分析(※2)を使うことで、このプロセスを自動化し、より迅速かつ網羅的にインサイトを得ることができます。皆さんのデータ分析の現場でも、「なぜ?」という問いに答えるために役立つ機能になるかと思います。
(※2)BigQuery ML における「貢献度分析モデル」は、一般的な機械学習モデルとは性質が異なります。通常の機械学習モデルは、訓練データを学習してパラメータをチューニングし、新たなデータを入力することで、予測や分類を行います。それに対して、貢献度分析モデルでは、投入したデータをそのまま解析して、指標への各特徴の貢献度を算出する仕組み自体をモデルと呼んでいます。そのため、モデルを作成した後に別データを再投入して推論するのではなく、データ投入と同時に貢献度分析が実施される点に注意が必要です。
今回使うデータの紹介
今回の貢献度分析では、「NYC Citi Bike Trips」のデータセット(※3)を使用します。これはニューヨーク市のシェアサイクルサービス「Citi Bike」の利用データです。Google Cloud Marketplaceで公開されており、BigQueryの公開データセットとして誰でもアクセスできます。
(※3)参考:NYC Citi Bike Trips – Marketplace
このデータセットには、以下のような情報が含まれています。
- 利用開始・終了時間
- 利用開始・終了ステーション情報
- 利用時間(秒)
- 利用者の情報(年齢層、性別、会員種別など)
- バイクの識別情報
このデータを使用して、2016年から2017年の間での自転車の利用時間の変化に貢献した要因を分析していきます。
BigQuery で貢献度分析をする際のステップ
BigQuery ML を用いて貢献度分析を実施する際の基本的なステップは、以下の3つです。
- データの準備:分析対象の指標と、その変化に影響を与えうるディメンションを含んだテーブルを準備します。
- モデルの作成:CREATE MODEL 文を使い、貢献度分析モデルを作成します。
- インサイトの出力: ML.GET_INSIGHTS 関数を使い、モデルから分析結果(インサイト)を取得します。
それでは、ステップごとの具体的に必要な手順を見ていきましょう。
ステップ① データの準備
まずは、分析に必要なデータを準備します。NYC Citi Bike Trips の公開データセットに対して、以下の SQL を実行して、分析用のテーブルを作成します。
SELECT -- 分析対象の指標で、自転車の合計利用時間を算出 SUM(tripduration) AS trip_duration, usertype, -- birth_year から計算し、10歳区切りに丸めた利用者の年代。 CAST(FLOOR((EXTRACT(YEAR FROM CURRENT_DATE()) - birth_year) / 10) * 10 AS INTEGER) AS age_group, gender, -- テストデータかコントロールデータかを示すフラグ。2017年に乗車したデータをテストデータ(TRUE)、2016年の乗車したデータをコントロールデータ(FALSE)として設定。 CASE WHEN EXTRACT(YEAR FROM starttime) = 2017 THEN TRUE WHEN EXTRACT(YEAR FROM starttime) = 2016 THEN FALSE END AS is_test FROM `bigquery-public-data.new_york_citibike.citibike_trips` WHERE starttime BETWEEN '2016-01-01 00:00:00' AND '2017-12-31 23:59:59' GROUP BY ALL
このクエリを実行すると、分析用のテーブルが作成されます。実行結果を新しいテーブルとして保存しておきましょう。
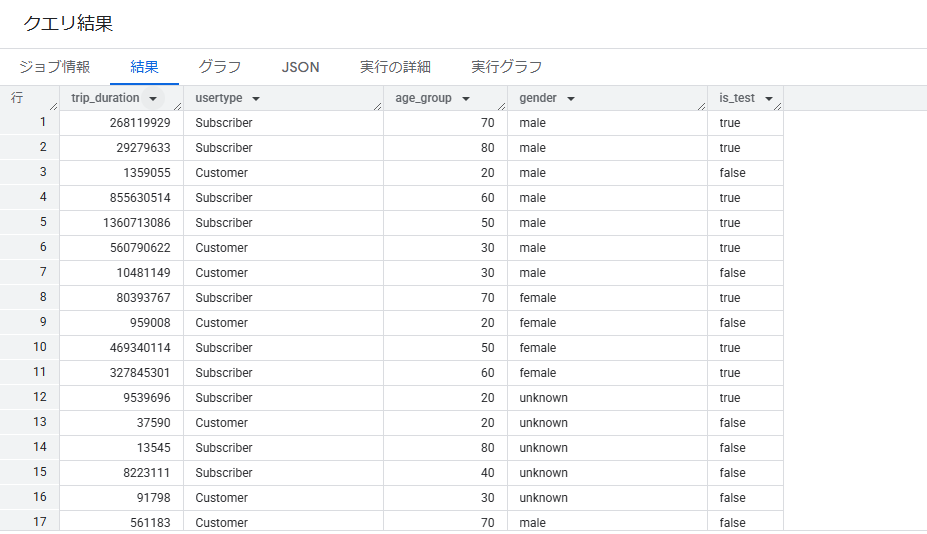 本ステップでは、分析の目的に応じて適切なディメンションを選択することが重要です。今回は、利用者の情報(年齢層、性別、会員種別)を選択し、これらのディメンションを軸に分析していきます。また、欠損値や異常値の処理も必要に応じて行ってください。
本ステップでは、分析の目的に応じて適切なディメンションを選択することが重要です。今回は、利用者の情報(年齢層、性別、会員種別)を選択し、これらのディメンションを軸に分析していきます。また、欠損値や異常値の処理も必要に応じて行ってください。
ステップ② モデルの作成
次に、準備したデータを使って貢献度分析モデルを作成します。以下の SQL を実行してモデルを作成しましょう。
この SQL を実行すると、バックグラウンドでモデルの学習を開始します。データ量により処理に必要な時間は変動しますが、今回は1分程度でモデルが作成されるかと思います。
-- 「{{projectid}}.{{datasetid}}.{{modelid}}」ご自身のプロジェクト ID とデータセット名、モデル名に置き換えて下さい。 CREATE MODEL `{{projectid}}.{{datasetid}}.{{modelid}}` OPTIONS( MODEL_TYPE='CONTRIBUTION_ANALYSIS', CONTRIBUTION_METRIC = 'SUM(trip_duration)', IS_TEST_COL = 'is_test', DIMENSION_ID_COLS = ['usertype', 'age_group', 'gender'], TOP_K_INSIGHTS_BY_APRIORI_SUPPORT = 20 ) AS -- 「{{projectid}}.{{datasetid}}.{{modelid}}」ステップ①で保存したテーブルの宛先に置き換えてください。 SELECT * FROM `{{projectid}}.{{datasetid}}.{{modelid}}`;
ここで重要なのが OPTIONS の設定です。OPTIONS の各パラメータが持つ意味と役割を見ていきましょう。
- MODEL_TYPE:作成するモデルの種類を指定します。今回は貢献度分析なので、 CONTRIBUTION_ANALYSIS を指定します。
- CONTRIBUTION_METRIC: 分析対象の指標を指定します。今回は利用時間の合計(SUM(trip_duration))を分析します。
- IS_TEST_COL:テストデータ(比較先)とコントロールデータ(比較元)を区別するカラムを指定します。今回は、is_test カラムを指定しています。このカラムが TRUE のデータがテストデータ、FALSE のデータがコントロールデータとして扱われます。
- DIMENSION_ID_COLS:分析対象のディメンションのカラム名を配列で指定します。今回は、ユーザータイプ、年齢グループ、性別を分析の切り口としています。
- TOP_K_INSIGHTS_BY_APRIORI_SUPPORT:ディメンションがデータ全体でどれくらいの割合を占めているかを示す指標に基づいて、取得するインサイトの数を指定します。今回は、上位20件を取得するように設定しています。
これらのオプションを適切に設定することで、分析の目的に合ったモデルを作成することができます。例えば、より詳細な分析を行いたい場合は、ディメンションを増やしたり、インサイトの数を増やしたりすることができます。一方で、ディメンションが多すぎると計算コストが高くなったり、解釈が難しくなったりする可能性もあるため、分析の目的に応じて調整することが重要です。それぞれのパラメータの詳細な説明については、「The CREATE MODEL statement for contribution analysis models | BigQuery | Google Cloud」をご参考ください。
ステップ③ インサイトを見てみよう
モデルの作成が完了したら、分析結果(インサイト)を確認してみましょう。以下の SQL を実行してみてください。
SELECT contributors, metric_test, metric_control, difference, relative_difference, unexpected_difference, relative_unexpected_difference, apriori_support, contribution FROM ML.GET_INSIGHTS( -- ステップ②で作成したモデルの宛先に置き換えてください。 MODEL `{{projectid}}.{{datasetid}}.{{modelid}}`);
このクエリを実行すると、以下のような結果が得られます。
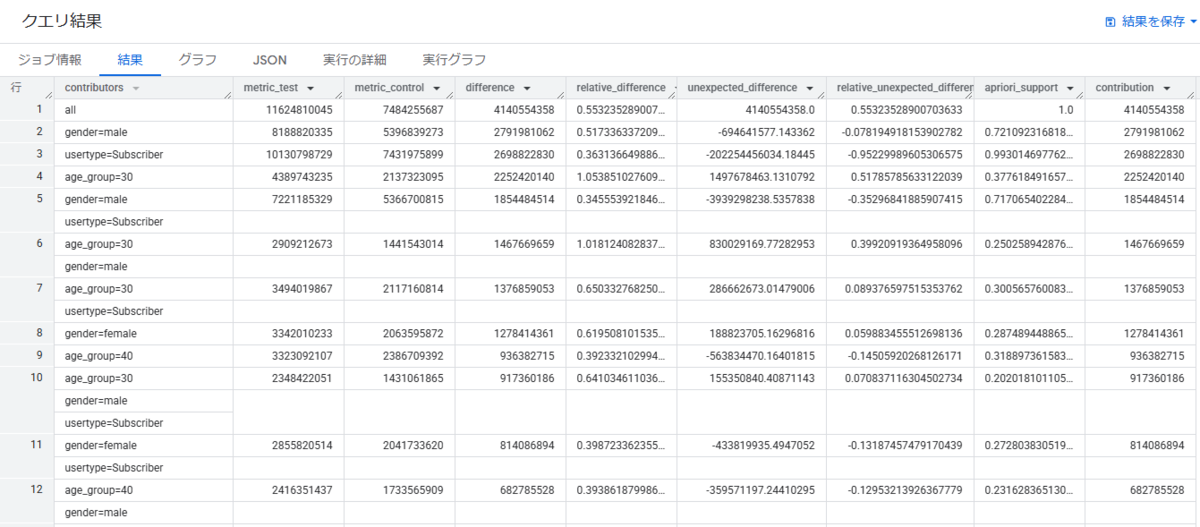
出力される主なカラムについて、簡単に説明します。
- contributors:指標の変化に貢献したディメンションの組み合わせ。
- metric_test:テスト期間における指標の値。今回の場合、2017年における、自転車の合計利用時間です。
- metric_control: コントロール期間における指標の値。今回の場合、2016年における、自転車の合計利用時間です。
- difference:テスト期間とコントロール期間の指標の値の絶対的な変化量。(計算式:metric_test - metric_control)
- relative_difference:相対的な変化量。(計算式:difference / metric_control)
- unexpected_difference:期待される変化からの差分。母集団の変化のトレンドから予測される値と、実際の値との間の差。
- relative_unexpected_difference:相対的な期待外れの変化量。
- apriori_support:ディメンションがデータ全体でどれくらいの割合を占めているかを示す指標。
- contribution:ディメンションが全体の変化にどれだけ貢献しているかを示す貢献度。
それぞれのカラムの詳細な説明については、「The ML.GET_INSIGHTS function | BigQuery | Google Cloud 」をご参考ください。
実行結果を見ると、様々なディメンションの組み合わせに対するインサイトが表示されています。全体としては、2017年の利用時間が2016年と比較して全体で約41.4億秒(約55%)増加していることがわかります。 主な貢献要因としては、男性ユーザー(全体の変化の約67%)、定期会員(約65%)、そして30代ユーザー(約54%)が挙げられます。
特に、30代のユーザーについては、前年比で約2倍(約105%)以上拡大しており、注目すべきセグメントであることが見受けられるかと思います。ほかにも、「男性の定期会員」や「30代の男性」といった複合セグメントも大きな貢献を示しています。
unexpected_differenceの列からは、30代のユーザーが予想以上に増加している一方、男性ユーザーは増加しているものの、予想を下回る結果となっていることがわかります。
このように、分析結果を見ることで、どのセグメントが全体に大きく影響しているのか、それはポジティブな影響なのかネガティブな影響なのか、といったことを具体的な数値と共に把握することができます。更に、例えば「なぜ、30代のユーザーは急激に利用時間が伸びたのか?」を、利用開始・終了ステーションに関するディメンションを加えて分析したり、他のマーケティング施策等の実施結果から深ぼって分析していくことで、より良いインサイトを得ることができるかと思います。
まとめ
今回は、BigQuery ML の一般公開された機能である貢献度分析について、NYC Citi Bike Trips のデータを使って、データの準備からモデル作成、インサイトの出力までの一連の流れを紹介しました。
これまで、時間をかけて複数の複雑な SQL を開発・駆使して行っていた貢献度の分析が、本機能を使用することで、ものの数分で複雑なデータの中から注目すべき変化とその要因を見つけ出すことができます。特に複数のディメンションを組み合わせて、ディメンションごとの影響度を提示してくれる点は、分析作業にかかる時間を大幅に短縮することができると感じました。これにより、分析結果を元にしたアクションプランの策定や意思決定により多くの時間を割くことができるようになるのではないでしょうか。
今回紹介した NYC Citi Bike Trips のデータ以外にも、皆さんがお持ちの様々なデータでこの貢献度分析を試すことができます。例えば、ウェブサイトのアクセスログ、購買データ、広告の成果データなど、様々なデータを活用できるかと思います。ぜひ、皆さんも貢献度分析を試していただき、隠れたインサイトを発見してみてください。そして、どのような発見があったか、どのような活用をしたか、コメントなどで教えていただけると嬉しいです!
