本記事は
生成AIウィーク
5日目の記事です。
👨💻
4日目
▶▶ 本記事 ▶▶
6日目
👩💻
こんにちは越川です。最近、検証でAmazon Bedrock Knowledge Bases(以降Knowledge Bases)を使う機会がありました。予想以上に様々な機能があったため、この機会に整理をしてみようと思います。
Knowledge Baseとは
Knowledge BasesとはAmazon Bedrockの機能の一つで、最近流行のRAG(Retrieval-Augmented Generation:検索拡張生成)を簡単に実装できる機能です。RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)の回答精度を向上させる技術です。LLMは基本的に事前に学習されたデータの範囲内でしか回答できないため、例えば社内情報について質問しても答えることはできません。
そこで、独自のデータ(例えば社内データなど)をLLMのプロンプトに渡してあげることで、特定のデータに基づいた回答が可能な生成AIを作成できます。通常、RAGを自前で作成するとなると、ベクトルデータベースの作成や、質問のベクトル化、検索、回答生成など複数の処理を実装する必要があります。Knowledge Basesはこういった仕組みをある程度マネージドで実装できるようになっており、RAGを気軽に構築してみたい!という方にはピッタリのサービスです。
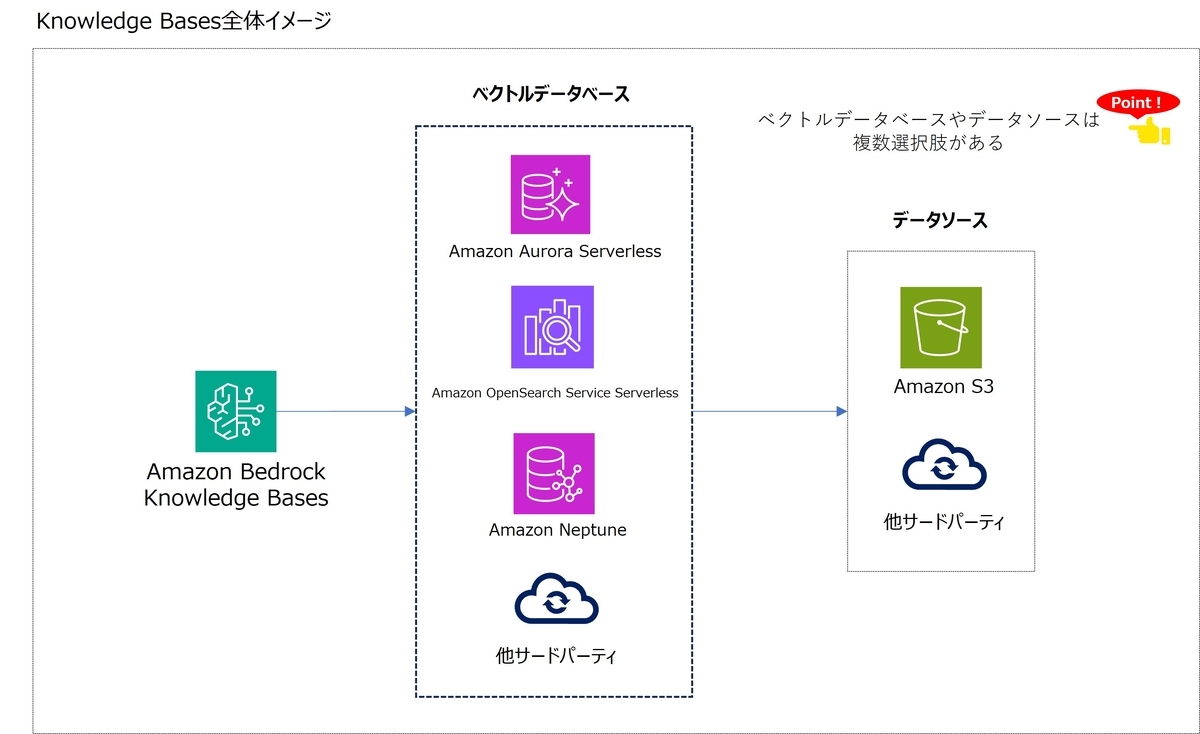
Knowledge Base全体構成
Knowledge Baseではデータソースを複数から選択することができます。Amazon S3以外に執筆時点(2025/02/25)では、SalesforceやSharePointも選択することが可能です。
また、ベクトルデータベースも複数選択することができます。デフォルトではOpenSearch Serverlessですが、AuroraベースのものやNeptune(GraphRAG)なども選択できます。AuroraのServerlessでは最近のアップデートでACUを0に設定することができるようになったため、コストメリットも大きい選択肢となります。また、Neptuneベースの物は従来のベクトル検索とは異なり、GraphRAGという新しいRAGになります。このGraphRAGはより文脈理解に強いRAGと言われており、昨今ではRAGの中でも注目を浴びています。このGraphRAGもナレッジベースを利用すれば、簡単に実装することができます。
その他の機能
その他にも様々な機能があるため、その一部をご紹介します。
メタデータフィルタリング
ドキュメントにカテゴリ等のメタデータを付与することで、メタデータで絞り込んだ検索を行うことができる機能です。 検索精度を向上させたい際や、特定の人にしかデータソースを閲覧させたくない場合に有効です。
高度なパース機能
PDFをそのままテキスト化した場合、表や図などが含まれていてもその情報を取り込むことができず、情報が失われてしまうケースがあります。 高度なパース機能を用いることで、図や表などの非構造データをテキスト化することができる機能です。
Bedrock Data Automation
ドキュメント、画像、音声、動画などの非構造化マルチモーダルコンテンツからデータを簡単に抽出できるサービスです。 書類、画像、音声、動画などの非構造化データをAIで自動処理し、有用な洞察を生成するサービスです。 こちらの機能は、音声や動画など幅広いコンテンツに対応しています。
Bedrock Guardrails
生成AIを利用する上で、生成されるコンテンツの安全性や適切さを管理者側で確保する必要があります。この機能を利用することで、特定のコンテンツ、トピック、単語、機密情報などをフィルタリングする事ができ、安全に生成AIを提供できます。
おわりに
今回紹介しきれなかった機能も複数あります。興味を持たれた方はぜひ色々と調べていただければと思います。個人的には、予想以上に簡単にRAGが構築でき、非常に使いやすいサービスだなと思いました。生成AIの導入を検討している方はぜひ触ってみていただければと思います。

