
1. はじめに
皆さんこんにちは、入社2年目の松澤武志です!
普段はJavaやAngularを用いてアプリケーション開発を行い、趣味でAWSコンソールをいじっています!
2年目もたくさんブログを書いていきたいと思います!
突然ですが、私は過去にAPI削除のタスクに着手しました。ただAPIに関連するメソッドを削除するだけだったらよいのですが、削除したことによって他の実装への影響がないかを把握する必要があり、この洗い出しがかなり大変でした。私はIntelliJ IDEA上で、Controllerメソッドから、メソッド参照箇所をたどっていきましたが、かなり骨の折れる作業でした。参照するメソッドも多くなってしまい、かなり複雑で、ヒューマンエラー(消してはいけないメソッドを消してしまうなど)が出る可能性があります。ですので、こんなことを思いつきました。
この作業、可視化すれば効率的に探索できるのでは??
グラフDBを使えばメソッド間の関係性を可視化できそう??
ということで、今回はグラフDBのサービスであるAmazon Neptuneを使用して、メソッド間の依存関係を可視化していこうと思います!
2. 基本知識
2-1. グラフとは
ここでグラフについて軽く押さえておきましょう。
グラフとは、頂点(Vertex/Node)と辺(Edge)から構成される集合のことです。折れ線グラフ等のグラフのことではありません。
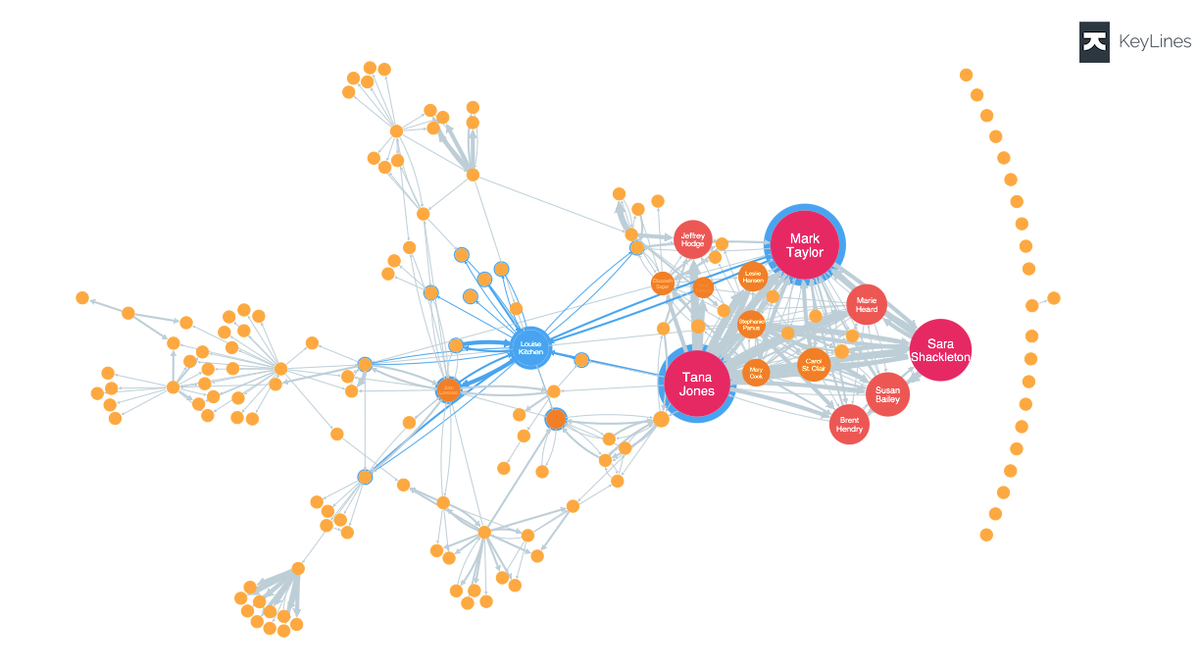
図のように、Nodeとその間を自由に結ぶEdgeが存在します。参照先を同一のNodeにする(ループ)こともできます。
グラフはSNSなど様々な場面で利用されています。例えば一人のユーザーを起点に、フォローしている人やフォローされている人の関係など、ユーザー同士のつながりをグラフで表すこともできます。リレーショナルデータやキーバリュー型データでは表現できないデータの複雑なつながりも、グラフを用いれば表現することができます。
2-2. Amazon Neptuneとは
Amazon Neptuneは、NoSQLデータベースサービスの一種でフルマネージド型のグラフデータベースサービスです。
前項で述べたグラフデータを効率よく扱うために設計されており、以下の特徴があります。
- グラフモデル対応:Property Graph(TinkerPop/Gremlin)、RDF(SPARQL)という2つの主要なグラフモデルをサポートしています。
- 高速なクエリ:数百万の関係性を高速にクエリできます。
- 高い安全性:Amazon Virtual Private Cloud(Amazon VPC)のプライベートサブネットに配置され、ネットワーク分離ができるほか、AWS Key Management Service(AWS KMS)による暗号化にも対応しています。
- 高可用性:Neptuneレプリカを作成し、読み取りの負荷を軽減します。
- 高い耐久性:クラスターボリュームにより、AZ間でレプリケーションされます。
このように、グラフデータに特化したサービスで、SNS、不正検出、ナレッジグラフなどに利用されます。
3. メソッド依存関係を可視化してみた
3-1. データの準備
今回はサンプルとしてAPIサーバとして実装されたSpring Bootアプリケーションを想定します。使用するサンプルメソッドの依存関係を図示します。
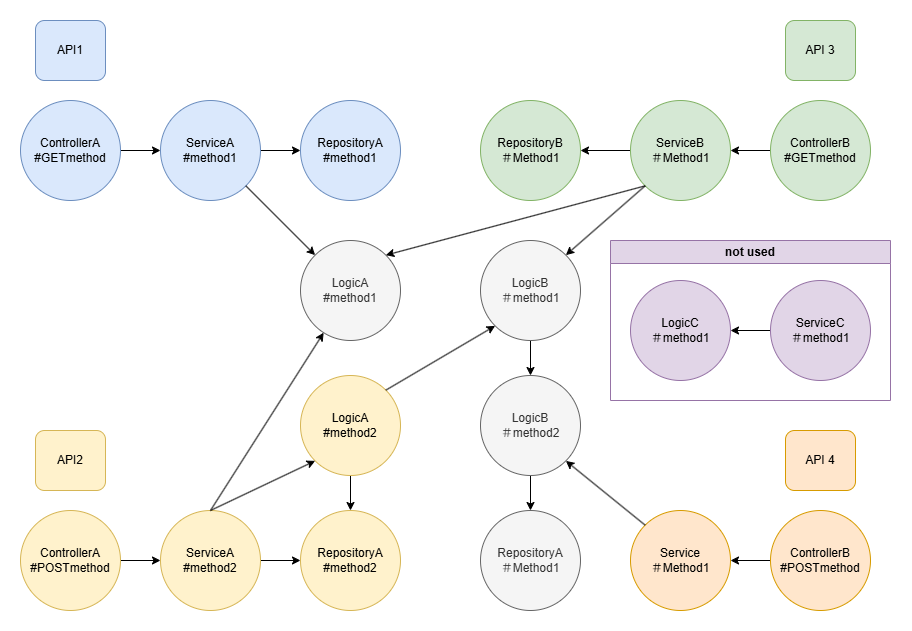
- 4つのAPIと関連するメソッドを用意します。
- 依存関係を簡素化するために、メソッドはController、Service、Repository、Logicと4つの層のみ抽出し、依存関係を矢印で表現しました。
- 複数のAPIで使用される共通部分は灰色で示しています。
- 4つのAPIのどれにも依存関係を持たないメソッド(紫)も用意しました。
また、後述するAmazon Neptune Bulk Loaderにより、このグラフのデータをApache TinkerPop Gremlin データ *1としてNeptuneにインポートします。そのためにVertexとEdgeそれぞれのデータを、下記のようにcsvフォーマットに整形します。
# Vertex.csv # group:String:文字列値(オプション) # ~label:識別するためのラベル ~id,group:String,~label v1,"API1",ControllerA#GETmethod v2,"API1",ServiceA#method1 v3,"API1",RepositoryA#method1 v4,"Common",LogicA#method1 v5,"API2",ControllerA#POSTmethod v6,"API2",ServiceA#method2 v7,"API2",RepositoryA#method2 v8,"API2",LogicA#method2 v9,"API3",ControllerB#GETmethod v10,"API3",ServiceB#Method1 v11,"API3",RepositoryB#Method1 v12,"Common",LogicB#method1 v13,"API4",ControllerB#POSTmethod v14,"API4",Service#Method1 v15,"Common",RepositoryA#Method1 v16,"Common",LogicB#method2 v17,"notUsed",ServiceC#method1 v18,"notUsed",LogicC#method1
# Edge.csv # ~id:edgeId # ~from, ~to:vertex.Id # ~label:識別するためのラベル ~id,~from,~to,~label e1,v1,v2,depend1 e2,v2,v3,depend2 e3,v2,v4,depend3 e4,v5,v6,depend4 e5,v6,v4,depend5 e6,v6,v7,depend6 e7,v6,v8,depend7 e8,v8,v7,depend8 e9,v8,v12,depend9 e10,v9,v10,depend10 e11,v10,v4,depend11 e12,v10,v11,depend12 e13,v10,v12,depend13 e14,v12,v16,depend14 e15,v13,v14,depend15 e16,v14,v16,depend16 e17,v16,v15,depend17 e18,v17,v18,depend18
クラス図を利用すればいいじゃないか
メソッド間の依存関係と言われたら、真っ先にUMLのクラス図が思いつく方もいらっしゃると思います。実際にNodeやEdgeにラベルを付けることができるので、クラス図をグラフ化すること自体は可能だとは思います。しかし、今回はメソッド間の依存関係を見たいので、クラス図を使用しないことにします。
また、クラス図だと多重度やカーディナリティを参照しないといけないのですが、ラベルに書く場合は可読性が落ちると感じました。
3-2. 必要なリソースのプロビジョニング
環境構築は、下記のAmazon Neptuneユーザーガイドに則り実施しました。詳細はこちらのページを確認してください。
大まかな流れは下記の通りです。
- ssh接続に用いるキーペア(例:ec2-key-pairs-for-connect-neptune)を作成
Neptuneクラスターの作成
Neptuneクラスターを作成するもっとも簡単な方法としてAWS CloudFormationのテンプレートを利用する方法が提供されています。- AWS CloudFormationを使用するためのアクセス許可設定を行う
- Neptuneのサービスリンクロールポリシー(例:NeptuneServiceLinked)を作成
- カスタマー管理ポリシーを作成(例:NeptuneClusterManagementPolicy)
- IAMユーザー(例:iam-user-forNeptune)を追加し、下記ポリシーをアタッチ
- NeptuneFullAccess
- NeptuneConsoleFullAccess
- NeptuneServiceLinked
- AmazonVPCFullAccess
- AWSCloudFormationReadOnlyAccess
- NeptuneClusterManagementPolicy
- クラスターを作成する
下記サイトからリージョンごとのテンプレートを起動できます。作成したキーペアの選択をする以外は、デフォルトの設定のままで起動可能です。 docs.aws.amazon.com
※NeptuneクラスターはDBインスタンスが時間単位で課金されます。課金を停止するためにはCloudFomationからスタックを削除しないといけないので注意が必要です。
CloudFormationスタックの起動が完了したら、Amazon Neptuneのコンソール画面を開きます。コンソールから、データベースにクラスターが作成されていることを確認できます。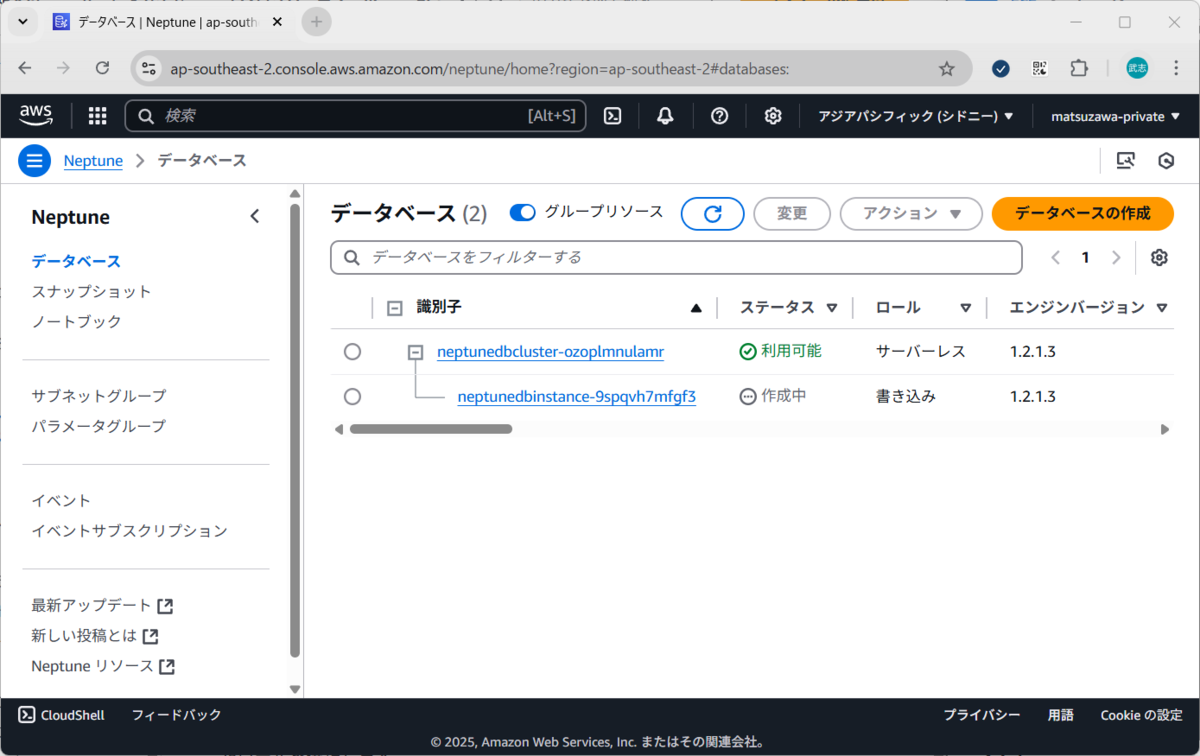
- AWS CloudFormationを使用するためのアクセス許可設定を行う
Amazon Simple Storage Service (Amazon S3)バケットの作成
Vertex.csv及びEdge.csvを保存するために、任意のS3バケットを作成します。Neptuneクラスター接続用のAmazon Elastic Compute Cloud (Amazon EC2)インスタンスの作成
CloudFormationスタックを起動させると、自動的にVPCがプロビジョニングされます。また、Neptuneクラスターは1つのリージョン内の複数のAZの各プライベートサブネットにまたがって構成されます。したがって、このVPCの任意のパブリックサブネットに対してEC2インスタンスを起動させることで、初めてNeptuneクラスターと接続することができます。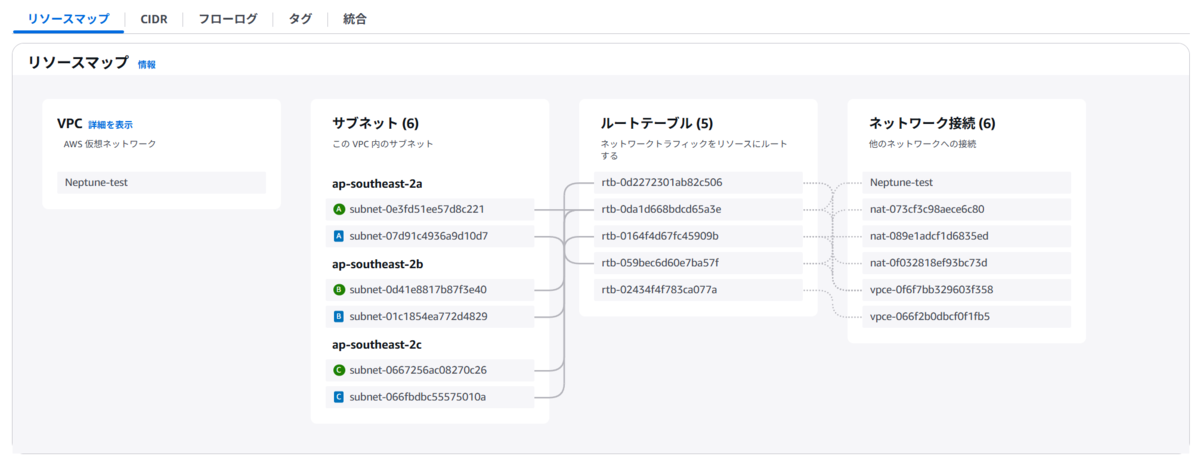
EC2インスタンスの設定は任意で問題ありませんが、ssh接続するために、今回作成したキーペア(ec2-key-pairs-for-connect-neptune)を指定しましょう。
また、EC2インスタンスへのssh接続、EC2インスタンスからNeptuneクラスターにHTTPS接続ができるか確認します。
セキュリティグループのチェック項目として下記に注意しましょう。
- EC2インスタンスのインバウンドルール
- ポート22のTCPプロトコルが許可されていること。
- Neptuneクラスターのインバウンドルール
- ポート8182のTCPプロトコルが許可されていること。
- Graph Explorer アクセスを有効にするようにHTTPSプロトコルが許可されていること。
- EC2インスタンスのインバウンドルール
全てのリソースがプロビジョニングされた場合は以下のような構成となります。
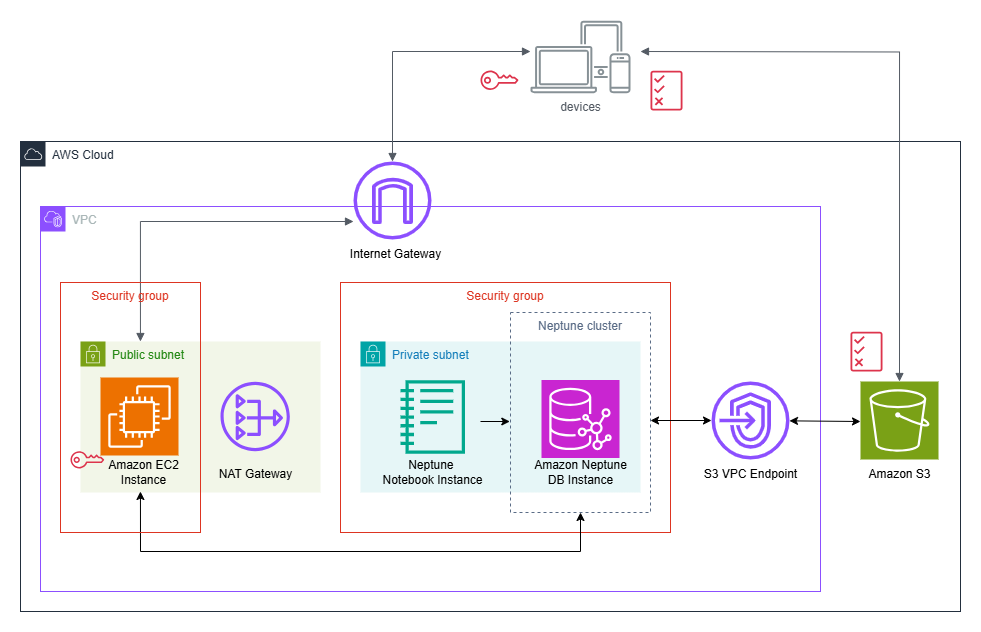
※Notebookインスタンスは次項で起動します。
3-3. Neptune Bulk Loaderによるデータの登録
Neptune Bulk Loaderとは
Neptuneクラスターにデータを登録する方法はいくつかあります。
- クエリによるロード
- EC2インスタンスからNeptuneがサポートするクエリ言語(Gremlin・openCypher・SPARQL)のコンソールを開き、コマンドを入力します。
- 少量のデータを入力する場合に適しています。
- Neptune Bulk Loader
- 外部ファイルに存在するデータを取り込むことができます。
- クエリによるロードよりも高速でオーバーヘッドが少なくなるメリットがあります。
- AWS Database Migration Service (AWS DMS)
- 他のデータストアからデータをインポートできます。
- Gremlin の
g.io(URL).read()ステップを利用- XML形式、JSON形式のファイルを読み込めます。
今回はNodeおよびEdgeが18個あり、クエリによるロードが若干手間がかかるため、csvファイルからNeptune Bulk Loadを利用することとします。
参考:Amazon EC2 インスタンスを同じ VPC 内の Amazon Neptune クラスターに接続する - Amazon Neptune
手順
- AmazonS3ReadOnlyAccessを付与したIAMロール(例:NeptuneLoadFromS3)を作成して、Neptuneクラスターに追加します。
- CloudFormationスタックにより作成されたVPCにVPCエンドポイントを作成します。
- EC2を起動し、ssh接続を行い、下記curlコマンドをたたきます。source項目のバケット名を変更してVertex.csv、Edge.csvの両方ロードします。
curl -X POST \
-H 'Content-Type: application/json' \
https://your-neptune-endpoint:port/loader -d '
{
"source" : "s3://bucket-name/object-key-name",
"format" : "format",
"iamRoleArn" : "arn:aws:iam::account-id:role/role-name",
"region" : "region",
"failOnError" : "FALSE",
"parallelism" : "MEDIUM",
"updateSingleCardinalityProperties" : "FALSE",
}'
リクエストに成功した場合は下記レスポンスが返ってきます。
{ "status" : "200 OK", "payload" : { "loadId" : "ef478d76-d9da-4d94-8ff1-08d9d4863aa5" } }
Vertex.csv、Edge.csvの両方問題なくロードできたら完了です!
3-4. Graph Explorerで可視化
Neptuneクラスターにデータをインポートしたので、いよいよ可視化していきましょう!
Graph Explorerの起動
Neptuneクラスターに登録されたグラフデータを可視化する手段はいくつかありますが、一番簡単に利用できるツールはGraph Explorerです。
Graph ExplorerはApache-2.0 ライセンスの下で利用可能な、グラフデータ用のオープンソースのローコードビジュアル探索ツールです。Neptuneグラフノートブック上で利用できます。
Neptuneグラフノートブックは、Neptuneのコンソールを開き、「ノートブックを作成」から作成したNeptuneクラスターを選択し、ノートブック名、説明、インスタンス、IAMロールに任意の名前を選択することで作成できます。
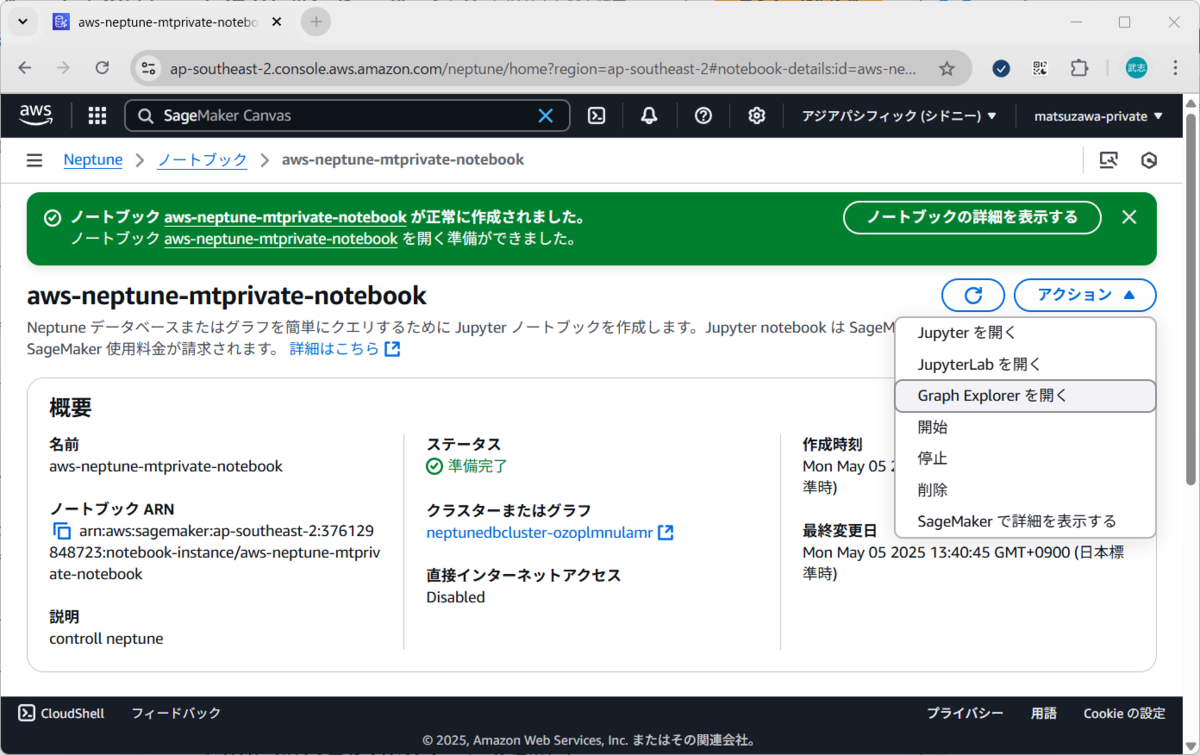
先ほど作成したNeptuneノートブックの「アクション」から「Graph Explorerを開く」を選択することでGraph Explorerが開きます。
Graph Viewで可視化
Graph Explorerの右側のナビゲーターからSearchタブを選択し、Node labelやAttributeから「Add node to View」を選択すると、NodeがGraph Viewに表示されます。また、NodeをダブルクリックするとNodeに関連するEdgeとNodeが表示されます。(※NodeをダブルクリックしないとEdgeが表示されないため注意です。)
そしてすべてのNodeを表示させると、、このようにGraph Viewからグラフを可視化することができました!
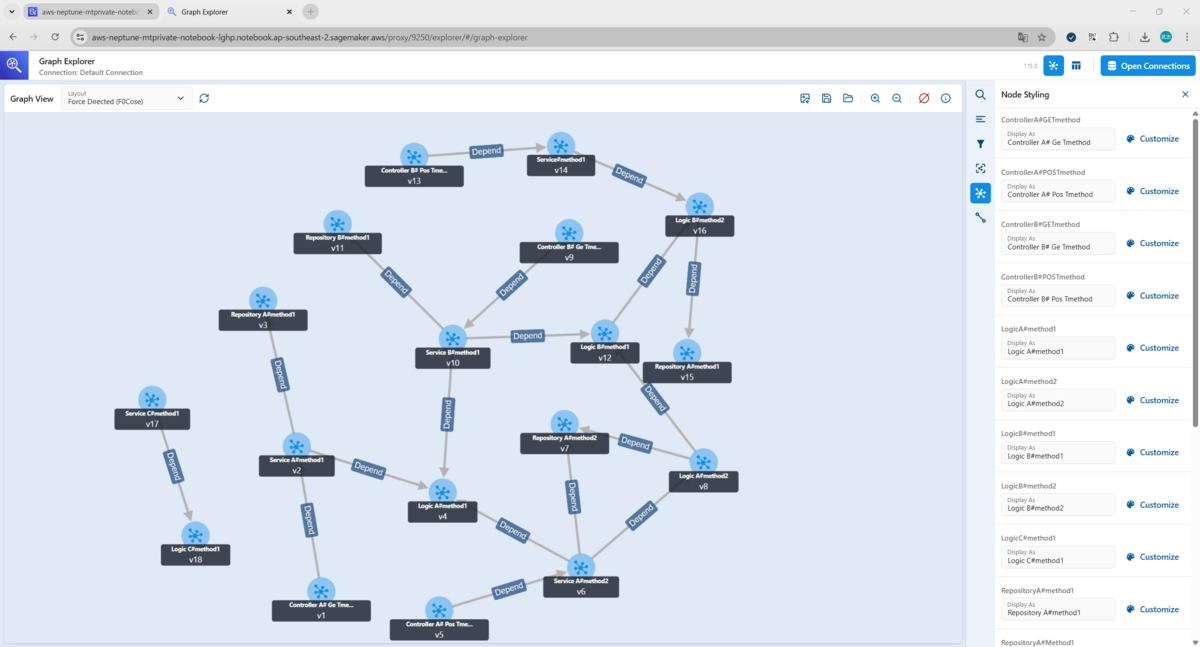
ちなみに「Re-run Layout」ボタンを押すと、レイアウトが変わります。押すたびにかなり違ったレイアウトになります。ノードはドラッグして位置を変えることもできます。レイアウトによっては、Edgeが重なって可視性が落ちるものもありました。適宜可視性の高いレイアウトにしていきましょう。
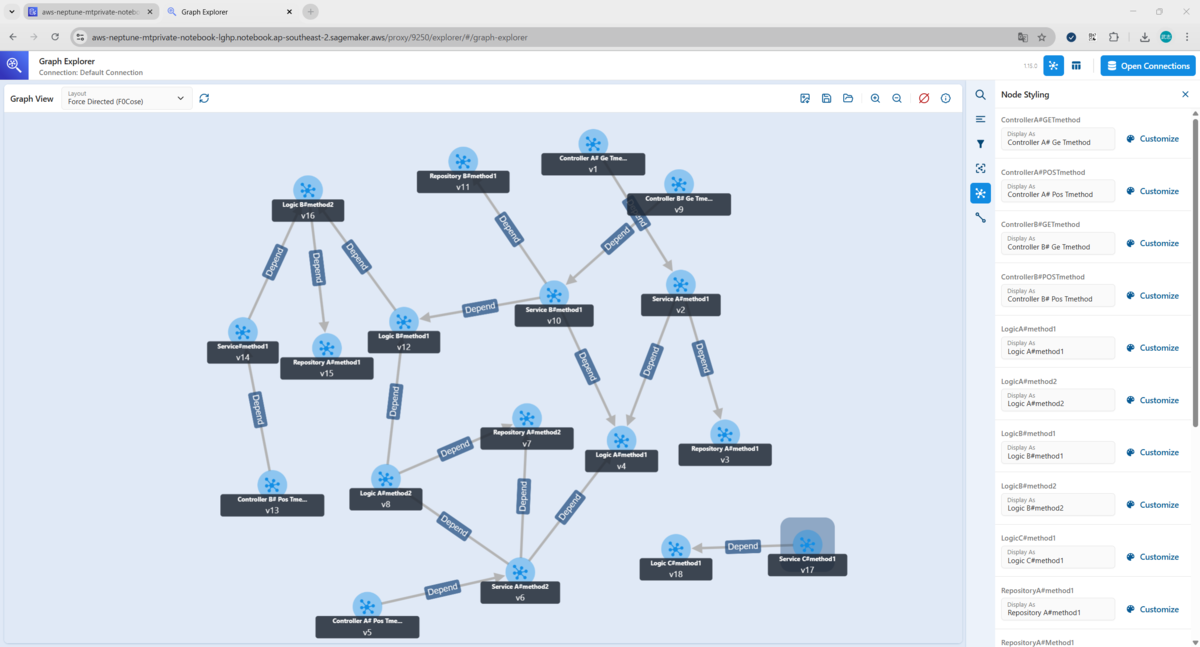
Graph viewでは、拡大縮小はもちろん、表示されたものはpngファイルに保存できます。
Graph Explorerその他の機能
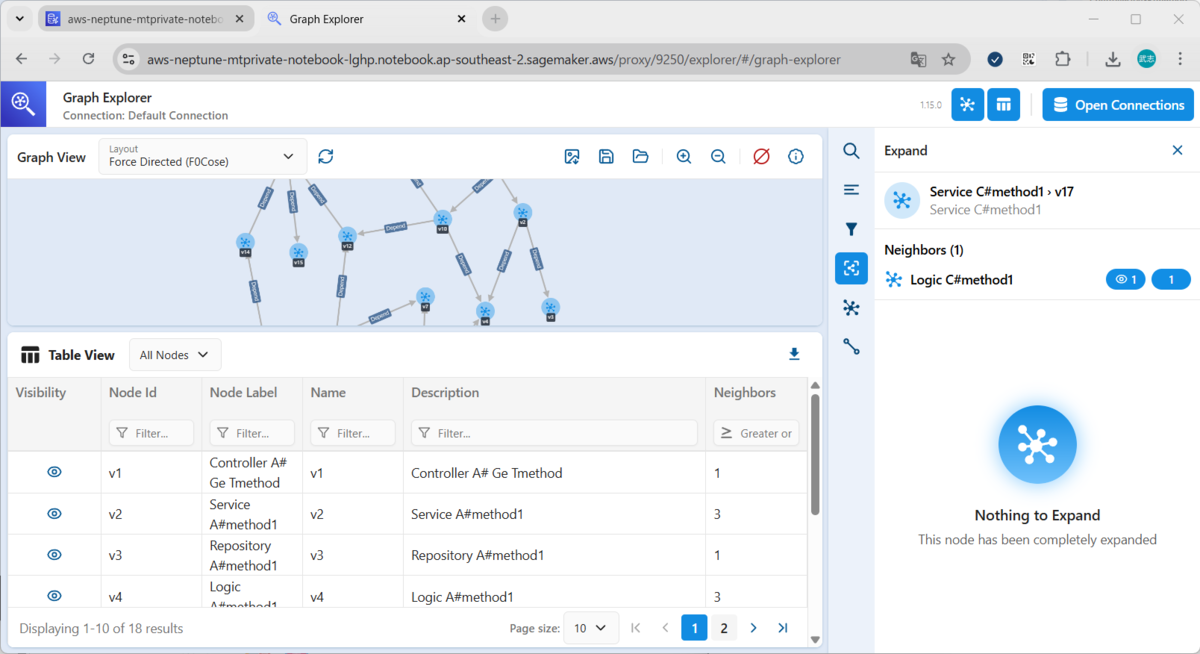
3-5. リソースの削除
今回のAWSリソースの利用によって、15$程度課金されました。 無駄な課金を抑制するためにも、利用が終わったらリソースの削除を行いましょう。
主なサービス課金内訳(サービスと使用タイプ)は以下のようになっています。
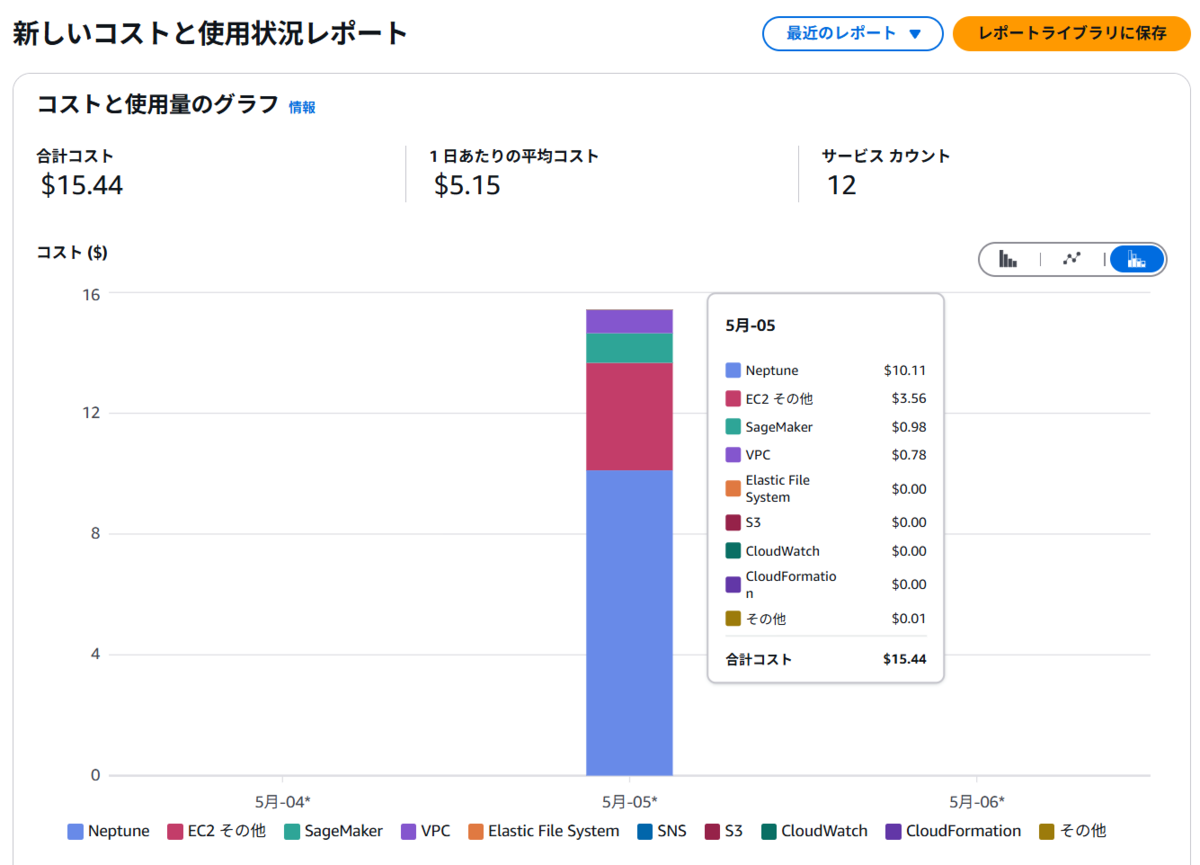
- Amazon Neptune:$10.11
- APS2-Neptune:ServerlessUsage
- Amazon EC2 その他(今回はNatGateway):$3.56
- APS2-NatGateway-Hours
- APS2-NatGateway-Bytes
- Amazon SageMaker AI:$0.98
- APS2-Notebk:ml.t3.medium
- APS2-Notebk:VolumeUsage.gp2
- Amazon VPC:$0.78
- APS2-VpcEndpoint-Hours
削除する方法
- EC2の削除
- EC2コンソールから削除できます。
- CloudFormationスタックの削除
- CloudFormationコンソールからスタックを選択し、削除します。
- EC2およびアタッチされたENIを削除しないとVPCが削除できないため注意してください。
- Neptuneクラスター、VPCの課金、NatGatewayの課金を抑制できます。
- Neptuneノートブックインスタンスの削除
- Neptuneコンソール、SageMaker AIコンソールから削除できます。
- SageMakerの課金を抑制できます。今回はボリュームでも少額課金されてしまったので、ノートブックインスタンス自体を削除しました。
- S3バケットのデータの削除
- S3コンソールから削除できます。
※EC2、S3に関しては、今回は無料利用枠の範囲で利用したため課金は発生しませんでした。
※私は執筆のために1日中CloudFormationスタックを起動させていたため15$も課金されてしまいました。起動しっぱなしには注意しましょう。
4. まとめ
可視化によってメソッドの依存関係を把握できたか
こちらに関しては、把握できたのではないかと感じました。グラフ化したことによって、Edgeで表示される依存関係を一目で見ることができました。例えばAPI Aを削除したいとなった際には
- ControllerA#GETmethod:依存されていない(矢印が向いていない)ため削除可能
- ServiceA#method1:ControllerA#GETmethodに依存されているが、ControllerA#GETmethodが削除可能なため削除可能
- RepositoryA#method1:ServiceA#method1に依存されているが、ServiceA#method1が削除可能なため削除可能
- LogicA#method1:3つのmethodに依存されているため削除不可
というように、ControllerA#GETmethod、ServiceA#method1、RepositoryA#method1が削除できることは一目瞭然です。
ただ、可視化されたことにより依存関係の洗い出しが簡単になったとはいえ、グラフを追わないとなりません。とあるNodeに依存するNodeを洗い出すようなクエリ文を作ることで、作業効率も上がるのではないかなと感じました。
今後の展望
今回は可視化だけにとどまりましたが、データを随時追加してインタラクティブなグラフを可視化できるように出来たら、とても有用なものになるのではないかと感じました!実はAmazon Neptune可視化ツールはいくつかあります。
- Tom Sawyerソフトウェア
- Cambridge Intelligence
- Graphistry
- metaphactas
- G.V()
- Linkurious
- Graph.Build
中でもCambridge IntelligenceはJavaScriptやReact用のSDKがあるため、アプリケーションに組み込むときに利用できそうです!
皆さんもAmazon Neptuneで様々な業務におけるデータの関係性を可視化していきましょう!
*1:グラフ計算のためのフレームワーク。グラフDBに対してクエリが可能 Graph Query Language - Gremlin | Apache TinkerPop
