はじめまして。喜早です。
業務では主に開発チームのマネジメントと要件定義を生業にして日々を過ごしています。
さて、多少エモめのタイトルをつけましたが、今回は機械学習とそれを構築する人間との倫理のお話をしようと思います。
機械学習モデルとバイアス
先日、社内の研修で、アンコンシャス・バイアス研修というものを受講しました。 アンコンシャス・バイアスを日本語訳すると「無意識の思い込み、偏見」です。 人間の行動は、自分の過去の経験や知識に基づいて発言や判断をすることが多いと思います。 その発言、判断の中に、自分でも無意識にステレオタイプや思い込みが含まれてしまっていることがあります。
アンコンシャス・バイアスは誰でも持っているものなので、完全に止めることはできない。 ただ、そういう人間の特性があることを自覚して、発言・判断を行う際には注意して行動しましょう、 というような内容でした。
で、これを受けてふと思い出したことがあります。2019年、私はGoogle I/Oに現地参加させてもらいました。
そこで受けたセッションのうちの一つに、Machine Learning Fairnessというタイトルのセッションがありました。
(YouTubeで動画が公開されているので貼り付けておきます。)
Machine Learning Fairness: Lessons Learned (Google I/O'19) - YouTube
概要としては、機械学習モデルにもバイアスがかかったものができてしまう可能性があるので 注意しよう、というようなことでした。機械学習は過去のデータをもとにモデルを作ります。 そのデータが偏っていればバイアスがかかってしまいます。
例としてセッションの中で示されていたのは「結婚式の写真」を判別する場合です。
新郎新婦の服装は各国で異なります。日本でポピュラーな形状と大きく異なる国もあります。
(具体的なイメージは、上記の動画の3分11秒あたりで見ることができます)
この場合、日本国内で日本人のユーザがほとんどの場合はさほど問題となることはないかもしれませんが、
Googleのようなグローバル企業が全世界向けに提供するサービスを提供している場合、サービスを提供している地域の結婚式の服装がそうであると判別されない場合、問題になる可能性があります。
こういったことを防ぐために、GoogleにはAI principalというものが定められていると同動画では語られています
Google Japan Blog: Google と AI : 私たちの基本理念
バイアスが紛れ込むタイミング
機械学習モデル構築において、このようなバイアスが作り込まれるのはどのタイミングでしょうか。
答えは、「人間の手が入る工程すべて」となります。
収集されるデータの偏り、分類を行う場合の教師あり学習の答えのラベル付け、モデル作成時のパラメタチューニングなど
人間が行動を行う際に、アンコンシャス・バイアスのような無意識な思い込みが影響して偏りが生まれてしまう可能性はあります。
機械学習は与えられたデータや設定をもとにアルゴリズムに基づいてモデルを作ることしかできないので、
バイアスを埋め込むのも除去するのも人間が行う必要があります。
偏りを可視化するAmazon SageMaker Clarifyの登場
昨年2020年のAWS re:Inventでこの問題の解消を手助けしてくれるサービスが発表されました。 Amazon SageMaker Clarify(以下、SageMaker Clarify)というサービスです。このサービスを用いると、機械学習に用いるデータセットとトレーニング済みのモデルの偏りを調べることができます。
例として、AWSが用意しているSageMaker Clarifyのサンプルノートブックでの結果を用いてお話します。 (すでにソースコードが全て書かれているため、ご自身でGithubからAmazon SageMaker Studioに取得すれば、各ブロックを実行していくだけで簡単に試すことができます。)
このソースでは、個人の職業や国籍などの属性情報を特徴量として、年収が5000ドルを超えるかどうかを予測するモデルを作っています。 サンプルでは、SageMaker Clarifyの機能を使い、データセットの性別の値の偏り具合と、構築したモデルの推論結果に性別がどれくらい影響しているか、ということを見ることができます。
下記図の赤枠の部分が、データの偏りを表現する指標です。 今回のサンプルソースの設定だと、この値が1に近いほど男性にデータが偏り、-1に近いほど女性に偏ったデータであることを表します。 このサンプルソースで利用しているデータだと、男性に偏りのあるデータであることがわかります。
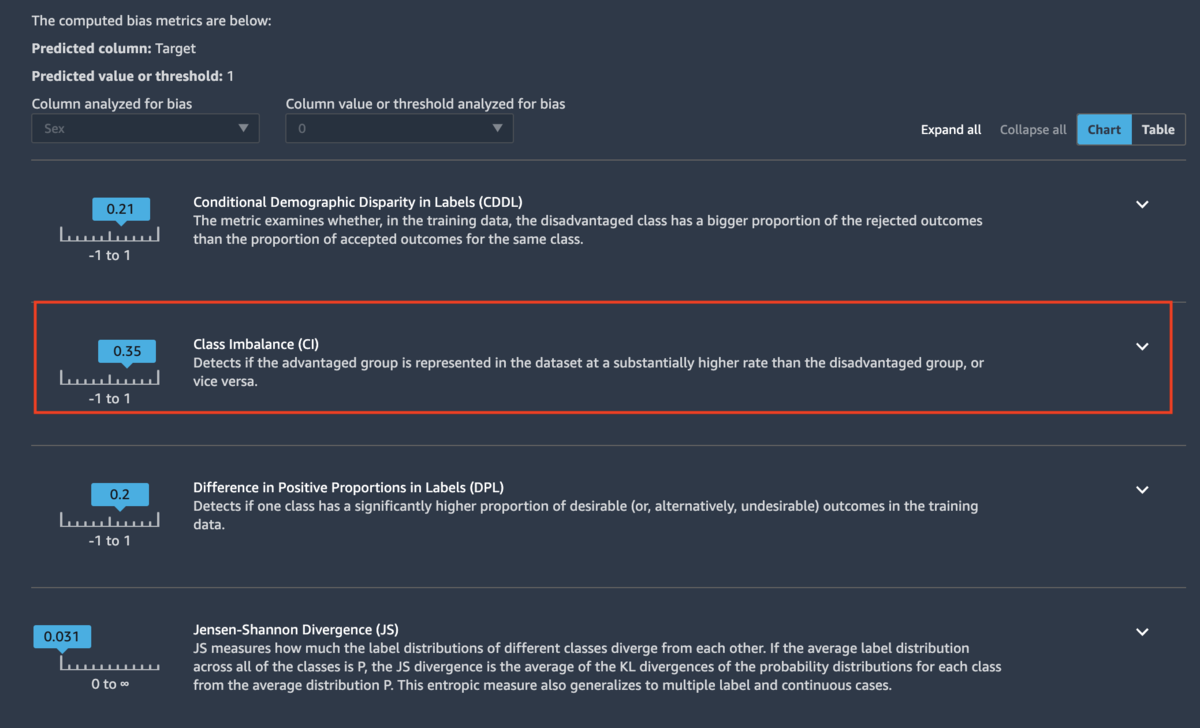
また、こちらの赤枠の指標が、モデルの推論結果に対する影響度を表します。1を基準とし、1以下であれば男性が、1以上であれば女性であることが、年収5000万ドル以上と判定される場合に影響を与えているという意味になります。
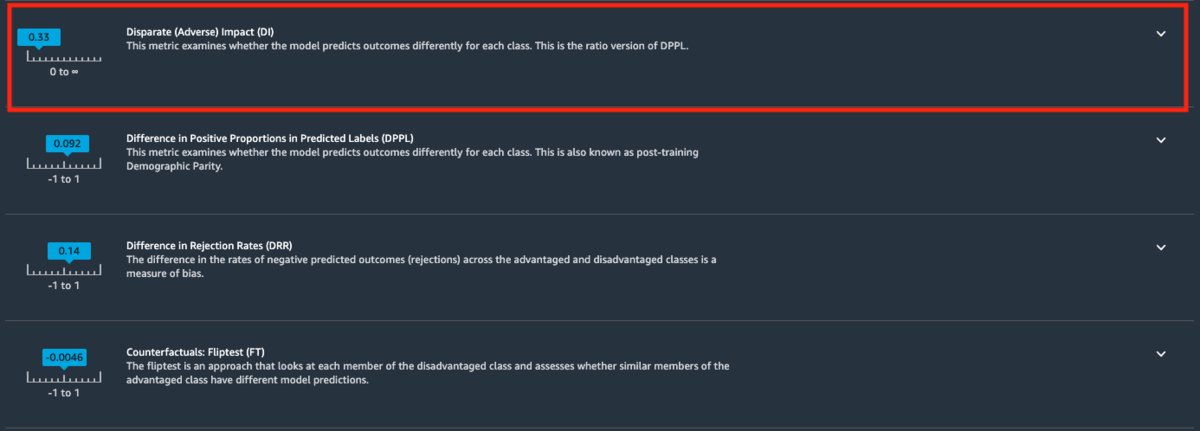
(ちなみに、このあたりの数値の見方はSageMaker Clarifyの設定次第でどちらが男性・女性かということは変わります)
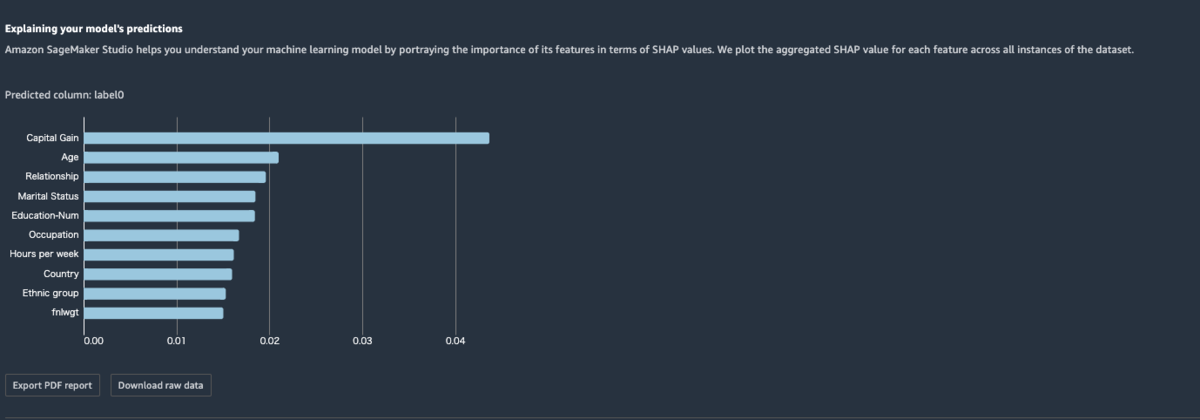
ここまでは、データ内のある列の値がどう結果に影響を与えるか、という観点の指標でしたが、SageMaker Clarifyでは、どの列が結果を推論する場合に大きな影響を持っているか、ということも可視化できます。 下記の図のように棒グラフで表現され、バーの長さが長いほど影響度が大きいということになります。 サンプルソースの例では他の列と比較して群を抜いて給与の列が一番影響度が高いという結果になっています。 一方で、これまで見てきた性別列はこのリストに出てきていません。
このグラフのもとになる数値のデータも見ることができるので見てみましょう。 すると、数値から性別の列の結果に対する影響度は、他の特徴量と比べて極端に低いわけではないものの、全特徴量の中で一番低いことがわかります。
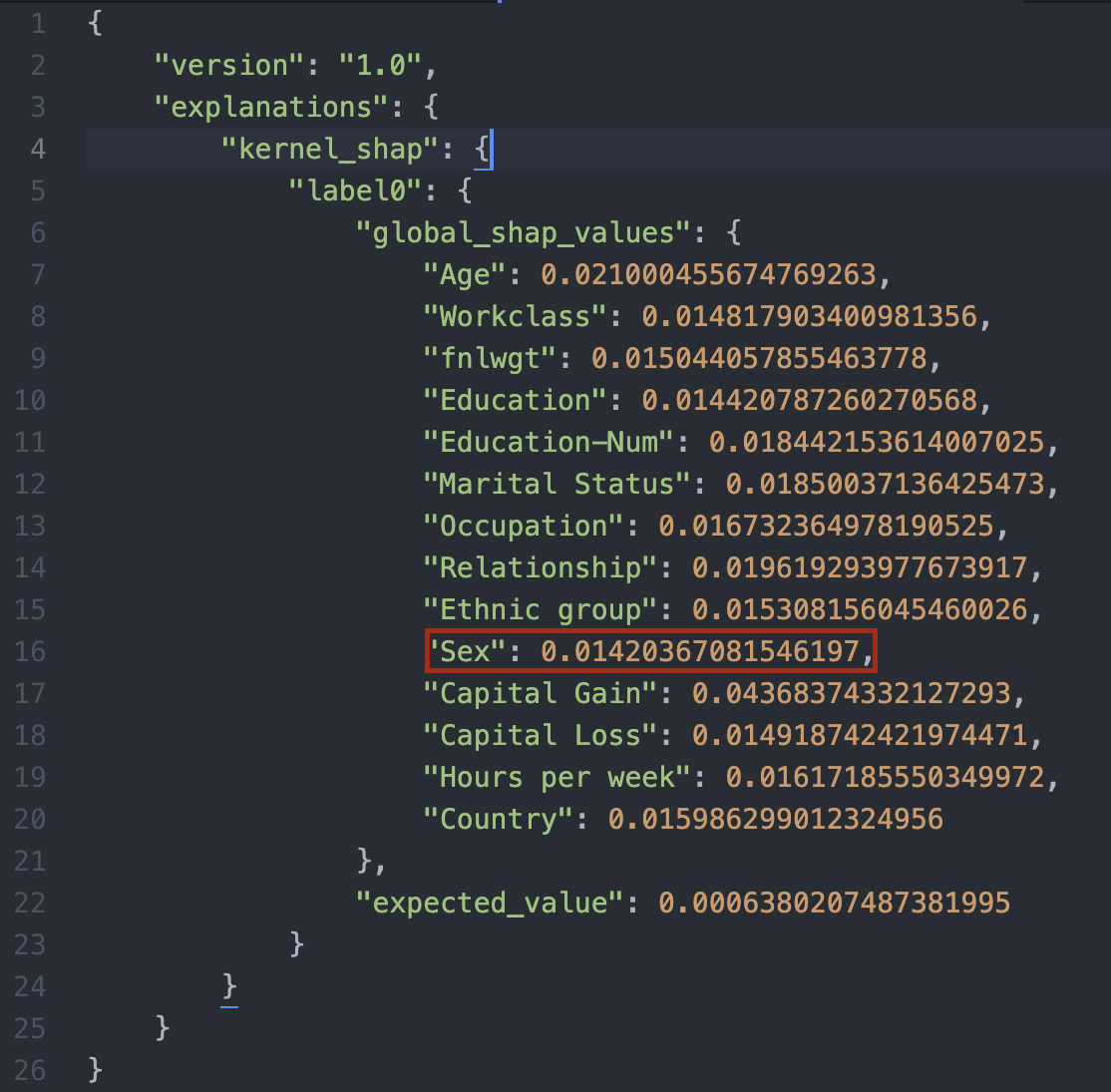
これらの結果を受けて、これが公正な推論結果を生み出すデータセットになっているか、またはモデルになっているかということを、データサイエンティストや事業担当者は考え、モデルの調整を検討します。
今回のサンプルでいうと、年収5000ドルを稼ぐ人かどうかを機械学習が推測する上で、その結果の判定に性別がどの程度影響を与えているか、そして、結果に影響を与える偏りかたは公平なのかどうか、という点ですね。
客観的な指標や統計情報があることは、モデルの公平性や、それを踏まえてのその後モデルやデータセットの調整を行う上でも大変役に立ちます。
まとめ
機械学習モデルは、インプットされたデータと設定されたパラメタに基づいて、赤子のように純粋に素直に結果を出しているに過ぎません。 そのため、公平性や倫理観というような、人間社会で重要視されるような部分については、機械学習モデルの生みの親となる人間の意識が強く反映されてしまいます。
一方で、どのような結果が公平なのか、というのは、この機械学習モデルを用いられる環境や文脈によって都度変わる、センシティブで一律の答えのない難しいテーマです。 特に、多様性のある社会が叫ばれている現代において、このテーマを考える難易度や複雑さは増していると思います。
機械学習モデルをビジネスで使う際には、構築に関わる人間側が公平性や倫理観のバランス感覚、思い込みで判断していないか、というような点に対して敏感になるとともに、 SageMaker Clarifyのようなサービスを使うことで、公平性を検討する負荷を下げていくことで、よりより機械学習モデルを育てていけることにつなげていけると思います。
