こんにちは佐々木です。
誰に望まれた訳でもないですが、データ分析基盤の設計シリーズの第三弾です。今回のテーマは、データ分析基盤における個人情報&パーソナルデータの扱いについてです。ここを最初に考えておかないと、データ分析基盤は毒入りとなって、扱いづらいものになります。
データ分析基盤構築の肝は、データレイクとDWHの分離 - NRIネットコムBlog データレイクはRAWデータレイク・中間データレイク・構造化データレイクの3層構造にすると良い - NRIネットコムBlog
個人情報&パーソナルデータと匿名加工について
まず最初に個人情報&パーソナルデータの定義と匿名加工について、サラッと確認しておきましょう。
個人情報&パーソナルデータ
個人情報とは、任意の一個人に関する情報であり、かつその情報をもとに個人を特定できるものを指します。代表的な個人情報としては、名前・住所・電話番号・E-mailアドレスなど"誰が"を特定できるものです。ただ、個人情報の難しいのは、組み合わせによって特定できるものは、それが個人情報として扱う必要がある点です。また、年齢も40歳といったものであれば個人の特定は難しいですが、120歳とか世界で一人しかいない場合は個人の特定が可能になります。前記の考え方でいうと、年齢でも個人を特定できる可能性があるということに注意してください。
パーソナルデータは、個人情報を含むもう少し広範なデータを指します。例えば、個人の属性情報(年齢・性別・出身地etc)やリアルの世界での行動履歴やWeb等での活動履歴、ウェアラブル機器等で取得した身体的なログ情報(心拍数・体温etc)なども含まれます。個人情報は個人情報保護法に定義され、パーソナルデータは総務省の情報通信白書に説明されています。システムを構築する際は、趣旨を把握した上で設計する必要があります。
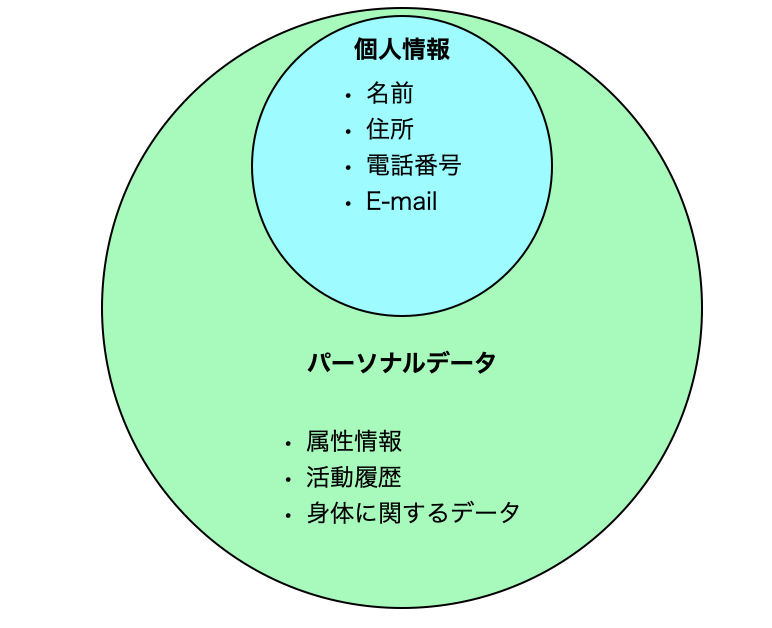
データ分析基盤を構築する上では、個人情報ではなくより広義なパーソナルデータをどう扱うかを考えて設計すると良いでしょう。
匿名加工情報
個人情報・パーソナルデータとともに覚えておいて欲しい用語に、匿名加工情報があります。匿名加工情報とは、特定の個人を識別することができないように個人情報を加工し、当該個人情報を復元できないようにした情報のことをいいます。簡単に言うとハッシュ化のような不可逆な加工を施したものです。匿名加工情報にすることで、データを分析の対象にしやすくなります。
基本的には、データを分析する際には個人情報は不要です。必ず個人情報を取り除いたもの、或いは匿名加工情報を分析する必要があります。また、匿名加工情報にすれば無条件で自由に扱ってよいかというと、そういう訳でもありません。オプトアウトが必要なケースもあり、原則的にはデータの利用ポリシーを事前に明確化しておく必要があります。
データ分析基盤と個人情報&パーソナルデータ
さて、そろそろ本題に入ります。データ分析基盤を作る上では、個人情報&パーソナルデータをどう扱うかのポリシーが重要になります。(以下、冗長なので個人情報と表現します)企業におけるデータ分析の目的の殆どが、売上や利益の拡大を最終的な目標とすることが多く、その場合は顧客データや売上データなど機微な情報を含むものを対象とする必要があるからです。結果、個人情報と向かい合わざるをえなくなります。
理想的な状況は、データ分析基盤内には個人情報は存在しない、或いはルールに基づいて匿名加工されている状態です。こういう状態であれば、分析基盤を組織内に広く開放し、誰でも手軽に扱えるようになります。いわゆる「データの民主化」が実現している状況ですね。一方で、そこに至るには数々のハードルが存在します。個人情報の取り扱い戦略とともに解説していきます。
個人情報の取り扱い戦略
個人情報の取り扱い戦略として、代表的なパターンを4つに分類し名前をつけました。名前については、今適当に考えたのでググっても出てきませんので悪しからず。
- ノーガード戦略
- 全部入り戦略
- 全部なし戦略
- 分離パターン戦略
順番に解説していきます。
ノーガード戦略
1つ目のノーガード戦略は、いわゆるアンチパターンです。絶対やらない方がよいパターンです。分析対象のデータを、分析担当者のパソコンに全部持ってきて、そこで分析するというパターンです。個人情報のあるなしに関わらずです。このパソコンを紛失した場合は大量の個人情報の流出につながりますし、万が一ウイルスに感染した場合はインターネット上に拡散する恐れも高くなります。
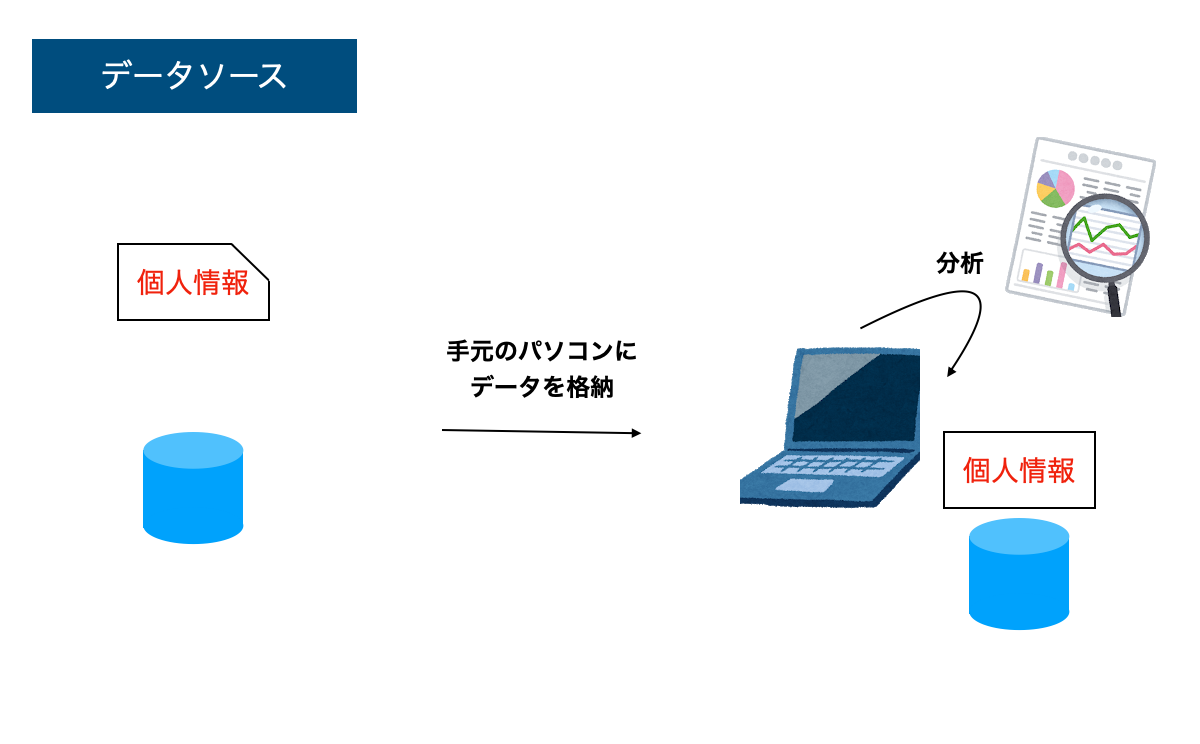
こんな怖い構成やらないよと思う方は多いと思います。一方で、規模の大小はあれど、これに類する構成は散見されるようです。データ分析基盤を構築する場合は、ローカルにデータをいれて分析しない、それを防げる構成にするということを肝に命じておきましょう。
全部入り戦略
2つ目が全部入り戦略です。データソースから個人情報も含めて全部データ分析基盤に連携するパターンです。その代わり、そのデータ分析基盤を扱える環境を限定し、出口の方で統制をかけるパターンです。
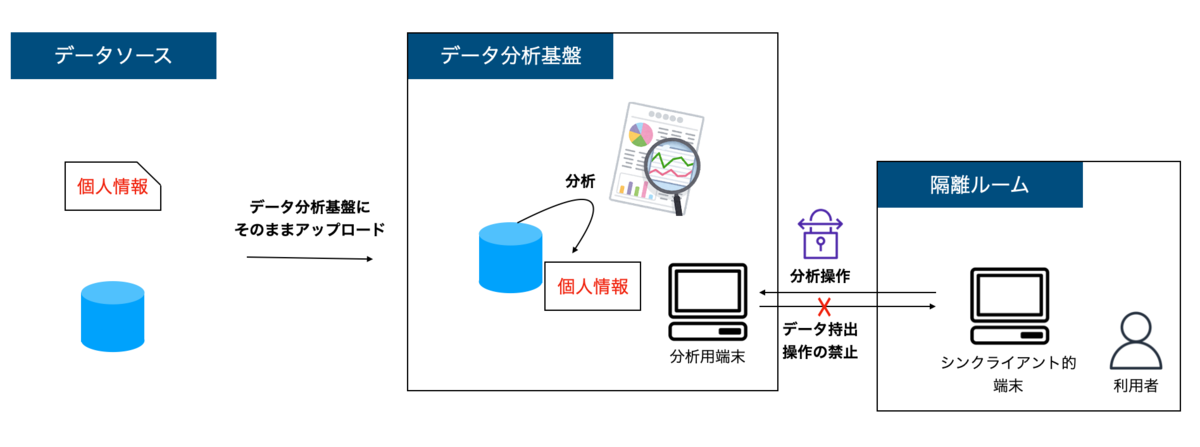
この構成は、ある一定合理的です。データ分析基盤と考えると奇異に見えるかもしれませんが、一般的なシステムはこのような扱いをしているのではないでしょうか?データの統制を既存のルール下で運用できるのが強みです。一方で、データを扱うための制約が大きく、データの民主化とは距離があります。
全部なし戦略
3つ目が全部なし戦略です。データソース側で個人情報の加工を行い、データ分析基盤に連携するパターンです。これは一番安全で、データ分析基盤を作る際は、まずこの構成を取れないか検討すべきでしょう。
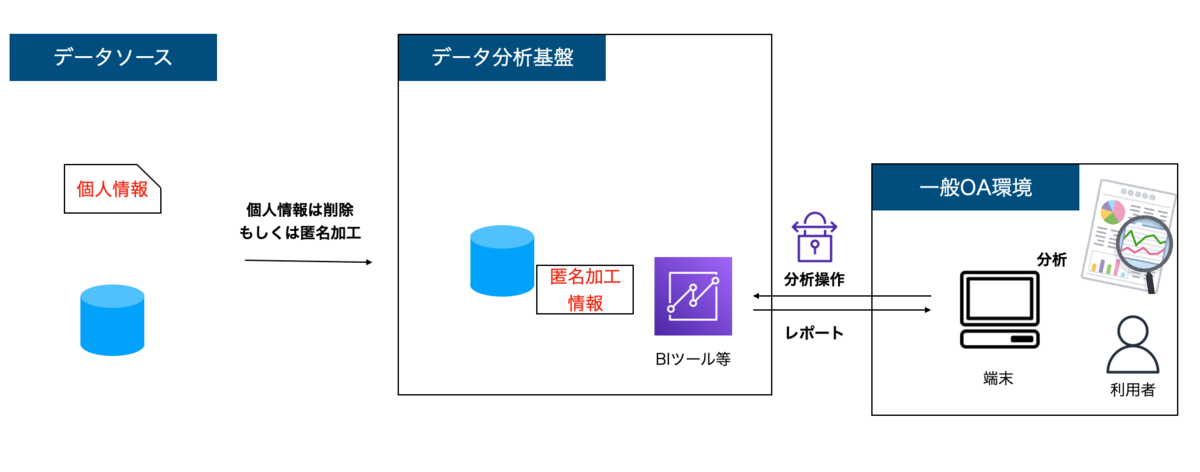
一方で、この構成は既存システムであるデータソース側の構築・運用負荷が高いです。また、データソースが多数ある場合は、それぞれのシステム担当者に同じような処理をしてもらう必要があります。全体効率の面と、それぞれ調整するためのコミュニケーションコストが課題となります。安全に倒すのであれば、全部なし戦略をとるべきです。一方で、なかなか実現が難しいという現実があるのも事実です。
分離パターン戦略
最後は、分離パターン戦略です。データ分析基盤の中を論理的に2つに別けて、個人情報ありの領域となしの領域の2つに分離します。その上で、データ分析の利用者は個人情報なしの領域のみを使うように遮断した構成となります。
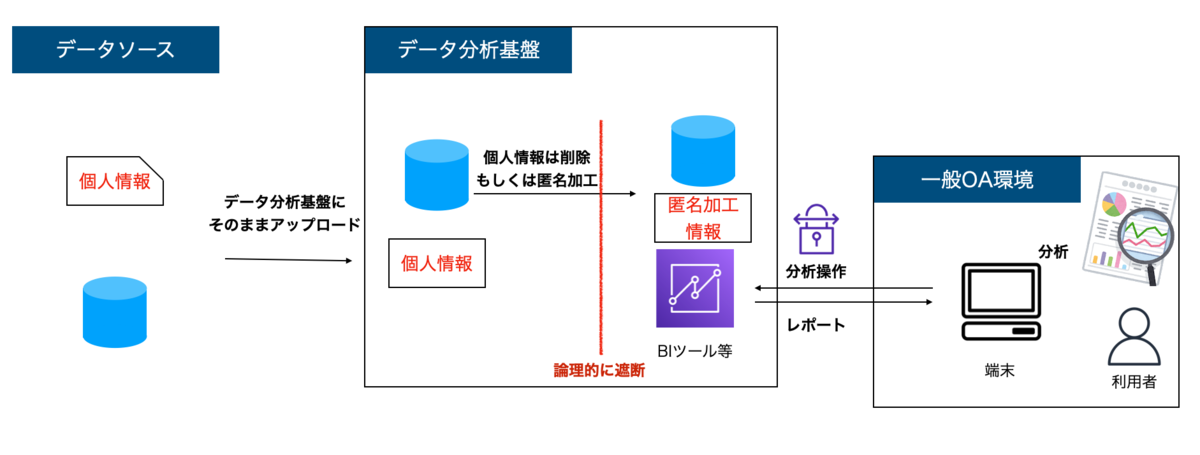
この方法のメリットとしては、データソース側担当の負荷が小さく、かつ匿名化などの加工が一元的にできるために、比較的効率的に行えることです。現実的な構成として、このような構成をとるケースが増えてきています。この記事に先立ち、「データレイクはRAWデータレイク・中間データレイク・構造化データレイクの3層構造にすると良い」という記事を書いていました。あれは、この構成を念頭においているものになります。
デメリットとしては、データ分析基盤の果たすべき範囲が大きくなる点です。どのようなデータが連携されているのか、適切にデータが処理されているかなど、全てデータ分析基盤側で把握する必要があります。この塩梅をどう管理すべきか、組織によって考えるべき課題となります
まとめ
データ分析基盤のあり方は、組織のポリシー・規模・習熟度によって大きく異なります。そのため、どの構成が最適というのもありません。また、今回4つのパターンに分類しましたが、実際はもっと細分化できます。もしデータ分析基盤の構築担当になった場合は、設計上の重要な観点を理解して、組織の実情にあった構成を考える必要があります。なかなか難しいところですが、腕の振るいどころですね。
データ分析基盤はNRIネットコムにお任せください。
NRIネットコムは、AWSを活用した統合的なデータ分析環境を構築・運用するサービスを提供しています。お客さまに適した柔軟性のある分析環境をご提供することで、お客さまのデータ利活用を継続的にサポートいたします。
